
 Agent 基础与工具调用
Agent 基础与工具调用
# 3.1 Agent基础与工具调用
# 🚄 前言
你的答疑机器人能回答员工手册里的问题了,但知识库之外的事情它无能为力:不能搜索互联网上的最新资料、也不能搜索数据库。这不是 RAG 的问题,而是大模型本身的局限:它只能基于已有文本进行对话,无法主动与外部环境交互。然而,人们恰恰希望利用它的理解和推理能力去“指挥”这些外部工具,来完成更复杂的任务。
这节课你将从最简单的工具函数开始,一路走到行业标准的 Function Calling 和 MCP 协议,理解 Agent 工具调用的完整机制。
# 🍁 课程目标
你将学到:
- 理解Agent为什么能"动手":工具定义→工具选择→输出格式约束→工具执行四件事
- 掌握Function Calling(重点):FC的完整机制与JSON Schema设计
- ReAct框架:用思考-行动-观察循环验证工具调用结果
- MCP协议:为什么出现、解决什么问题、对开发者和知识服务企业的价值
# 加载百炼的 API Key 用于调用千问大模型
import os, sys
os.chdir(os.path.join(os.path.dirname(os.path.abspath('')), 'course_core'))
sys.path.insert(0, os.getcwd())
from openai import OpenAI
from config.load_key import load_key
load_key()
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
print(f"API Key 已加载:{os.environ['DASHSCOPE_API_KEY'][:5]}*****")
2
3
4
5
6
7
8
9
10
11
12
13
14
# 1 你的第一个工具函数
有位同事正在开发一篇"大模型基本原理"的在线课程,他希望机器人可以帮他搜集互联网上最新的教学素材。
你会发现,机器人只能从公司知识库中检索信息,或者用大模型的世界知识回答问题。
# 1.1 硬编码方案:最简单的实现
要让机器人能获取互联网信息,最直接的思路是:为机器人编写一个联网搜索工具函数,它每次都会搜索用户的问题,并把搜索结果和问题一并发送给大模型。
假设你已经写好了一个名为 web_search 的函数,它可以通过搜索引擎查找资料。现在,当用户提出请求时,你希望模型能够利用这个函数。最简单的实现方式是,在收到请求后,程序"硬编码"执行这个函数,然后将执行结果与原始请求一并发送给大模型,让它生成一段总结性的回复。

# 1. 用户的原始请求
user_request = "你好,请帮我搜集一些关于 Transformer 模型的最新资料。"
# 2. “硬编码”执行工具函数
# 这里的 web_search 函数是模拟的,以聚焦于核心逻辑
def web_search(query: str):
"""模拟执行网络搜索并返回JSON格式的结果"""
print(f"--- [工具执行中] 正在搜索: {query} ---")
# 真实场景中,这里会调用一个真正的搜索引擎API
return '''{
"results": [
{"title": "Attention Is All You Need (Transformer 论文原文)", "url": "https://arxiv.org/abs/1706.03762", "snippet": "The dominant sequence transduction models are based on complex recurrent or convolutional neural networks... We propose a new simple network architecture, the Transformer, based solely on attention mechanisms..."},
{"title": "The Illustrated Transformer – Jay Alammar", "url": "https://jalammar.github.io/illustrated-transformer/", "snippet": "A visual and intuitive explanation of the Transformer model."}
]
}'''
tool_result = web_search(query=user_request)
print(f"用户请求: {user_request}")
print(f"工具结果: {tool_result}\n")
# 3. 将用户请求和工具结果拼接成一个提示,发送给大模型
# 目标是让模型基于结构化的工具输出,生成一句人类易于理解的回复。
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'system', 'content': '你是一位课程研究助理,你的任务是根据工具的执行结果,向用户生成一句友好和清晰的回复。'},
{'role': 'user', 'content': f'用户原始请求: "{user_request}"\n工具执行结果: {tool_result}'}
]
)
# 4. 输出模型的最终回复
final_response = completion.choices[0].message.content
print(f"模型生成的最终回复:\n{final_response}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 1.2 局限性分析:为什么需要更灵活的方案
这种方式虽然简单有效,但它也有局限性:只适用于"有且仅有一个工具,且每次对话都必须调用它"的场景。随着同事们的需求增长,你的机器人可能还要添加 search_arxiv_paper(在学术网站 Arxiv 搜索论文)、fetch_webpage_content(获取指定网页的全文内容)等更多工具。这时,你会遇到一个更棘手的问题:如何让机器人按需调用工具呢?
# 2 意图识别:让 Agent 决定用什么工具
# 2.1 脆弱的关键词匹配
一个直接的想法是编写一个"路由器",通过 if/elif 结构和关键字匹配来判断用户的意图。
# 伪代码:一个脆弱的、基于关键字的工具路由器
def route_to_tool(user_input):
if "论文" in user_input or "arxiv" in user_input:
return "search_arxiv_paper"
elif "搜索" in user_input or "查找" in user_input or "资料" in user_input:
return "web_search"
elif "总结" in user_input or "内容" in user_input or "http" in user_input:
return "fetch_webpage_content"
# ... 你需要在这里不断添加 elif 判断
else:
return "no_tool_needed"
2
3
4
5
6
7
8
9
10
11
你立刻能发现这种方式的弊端。它非常脆弱且难以维护。如果用户说"我想看看那篇 Attention is All You Need 讲了什么",这个简陋的路由器就无法识别出 search_arxiv_paper和fetch_webpage_content 的意图,因为它不包含任何预设的关键词。
# 2.2 基于大模型的意图识别
一个更优的思路是,你可以在提示词中列出所有工具,让大模型帮你决定调用哪个工具,使用什么入参。这就是意图识别的一种简单实现。
def get_tool_decision_from_llm(user_request):
from textwrap import dedent
# 使用 dedent 移除为了代码美观而添加的缩进,
# 避免这些格式化用的tab/空格被传递给大模型
prompt = dedent(f"""
你是一个智能助理的路由模块。你的任务是根据用户的请求,从下面的工具列表中选择最合适的工具来解决问题,并给出入参。
[可用工具列表]
1. web_search: 用于在互联网上搜索通用信息。
2. search_arxiv_paper: 用于在 Arxiv.org 上搜索学术论文。
3. fetch_webpage_content: 用于获取指定URL的网页内容。
[用户请求]
"{user_request}"
[决策]
请告诉用户你的决定。
""")
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'user', 'content': prompt}
],
temperature=0.0 # 使用低 temperature 以获得更确定的决策
)
decision = completion.choices[0].message.content
return decision
# --- 测试用例 ---
request = "帮我找一下那篇经典的 Transformer 论文,标题是 'Attention Is All You Need'"
decision = get_tool_decision_from_llm(request)
print(f"用户请求: \"{request}\"")
print(f"模型决策: {decision}\n")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 3 确保可靠:结构化输出
# 3.1 为什么需要结构化
现在你解决了"该调用哪个工具"的问题,下一步就是用代码解析和执行大模型的决策结果。然而,你会发现大模型返回的结果夹杂着自然语言,且没有固定的格式:
我将使用 search_arxiv_paper 工具来搜索标题为 "Attention Is All You Need" 的经典 Transformer 论文。好的,工具是 search_arxiv_papersearch_arxiv_paper(query="Attention Is All You Need")
这是因为大模型倾向于生成多样化的文本,而你需要的是一种易于解析的、确定的数据格式。要解决这个问题,你需要反过来,要求模型必须按照你预设的、严格的结构化格式进行输出。
JSON 就是这样一种理想的格式。一份定义清晰的 JSON 输出是无歧义且易于解析的:
{
"tool_name": "search_arxiv_paper",
"parameters": {
"query": "Attention Is All You Need"
}
}
2
3
4
5
6
它清晰地定义了"做什么"(tool_name)和"用什么做"(parameters)。这种键值对结构,任何编程语言都能轻松解析。
# 3.2 构建"引导-校验-重试"闭环
接下来的任务,就是如何确保模型能够稳定、严格地按照你定义的 JSON 结构进行输出。要实现这一目标,你需要建立一套清晰的流程。
定义结构:首先,你需要精确地定义你期望的输出结构。你可以使用 JSON Schema(一种用于描述 JSON 数据结构的语言),或是在 Python 代码中通过 Pydantic 等库来定义数据模型。这个 Schema 明确了最终产出物必须包含哪些字段、每个字段的类型,是整个流程的基石。
构建提示词:在你的提示词中,除了要下达任务指令,你还应该附上完整的 Schema 定义,并提供一到两个完全符合该 Schema 的输出范例。通过这种"指令 + 范例"的方式,模型能更透彻地理解你的要求。
校验与重试:程序在收到模型的输出后,须使用相同的 Schema 进行严格验证。如果验证失败,程序应捕获验证的错误信息,并将其连同模型上一次的错误输出,作为修正线索,再次发给模型,要求它重新生成。

import json
from textwrap import dedent
from typing import Union, Literal
from pydantic import BaseModel, Field, ValidationError, TypeAdapter
# 1. 为与课程研究相关的工具定义 Pydantic 参数模型
class WebSearchParams(BaseModel):
query: str = Field(description="用于网络搜索的关键词。")
class SearchArxivParams(BaseModel):
query: str = Field(description="用于在 Arxiv.org 上搜索的论文标题或关键词。")
# 2. 定义工具调用模型,将工具名与对应的参数模型绑定
class WebSearchCall(BaseModel):
tool_name: Literal["web_search"]
parameters: WebSearchParams
class SearchArxivCall(BaseModel):
tool_name: Literal["search_arxiv_paper"]
parameters: SearchArxivParams
# 使用 Union 类型,表示模型最终的决策是这两种调用中的一种
ToolCall = Union[WebSearchCall, SearchArxivCall]
# 3. 构建提示词,包含清晰的指令、工具定义和示例
def build_prompt(user_request: str) -> str:
return dedent(f"""
你的任务是根据用户的请求,从可用工具列表中选择最合适的工具,并以严格的 JSON 格式输出调用信息。
# 可用工具:
- `web_search(query: str)`: 当需要搜索通用信息、新闻或非学术性内容时使用。
- `search_arxiv_paper(query: str)`: 当需要搜索学术论文,特别是来自 Arxiv.org 的论文时使用。
# 输出格式要求:
你必须严格按照以下 JSON 结构输出,不要包含任何额外的自然语言解释。
{{
"tool_name": "工具名称",
"parameters": {{
"参数名": "参数值"
}}
}}
# 示例:
用户请求: "最近AI领域有什么好玩的新闻?"
你的输出:
{{
"tool_name": "web_search",
"parameters": {{
"query": "AI领域最新新闻"
}}
}}
# 用户请求:
"{user_request}"
# 你的输出:
""")
# 4. 调用并验证(带重试)
def get_structured_output(user_request: str, max_retries: int = 2):
messages = [{'role': 'user', 'content': build_prompt(user_request)}]
adapter = TypeAdapter(ToolCall)
for attempt in range(max_retries):
# 此处为对大模型服务的API调用,为保证课程的通用性,具体实现已省略
# 你可以替换成自己的代码,例如 client.chat.completions.create(...)
response = client.chat.completions.create(
model="qwen-plus", messages=messages, temperature=0
)
raw_output = response.choices[0].message.content
try:
# 解析并验证
data = json.loads(raw_output.strip('```json').strip('```'))
# 使用Pydantic模型验证解析后的数据
validated_data = adapter.validate_python(data)
return validated_data.model_dump()
except (json.JSONDecodeError, ValidationError) as e:
# 如果失败,则将错误信息和原始输出都加入到对话历史中,以便模型进行修正
messages.extend([
{'role': 'assistant', 'content': raw_output},
{'role': 'user', 'content': f"格式错误: {e},请严格按照JSON格式重新输出"}
])
return None
# 使用
# 假设 client 变量已在别处初始化
user_request = "帮我找一下那篇经典的 Transformer 论文,标题是 'Attention Is All You Need'"
result = get_structured_output(user_request)
if result:
print(json.dumps(result, indent=2, ensure_ascii=False))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
# 4 主流方案:函数调用 (Function Calling)
# 4.1 Function Calling 的工作原理
你刚刚手动实现的"意图识别 -> 结构化输出 -> 验证与重试"是一套健壮的工具调用流程,它的完整实现较为复杂。为了简化开发过程,许多大模型服务商(阿里云、OpenAI、Anthropic、Google等)已在 API 中内置了这一能力,这就是函数调用 (Function Calling) 或 工具调用 (Tool Calling)。
以 OpenAI SDK 的函数调用为例:
工具定义 (Tool Definition): 你需要在 API 的
tools参数中定义可用的工具,使用 JSON Schema 描述每个工具的name、description以及parameters(函数所需的输入参数结构)。调用决策 (Call Decision): 模型根据用户输入和工具定义,自动决策是否需要调用工具。如果需要,模型会在响应中返回
tool_calls字段,包含要调用的函数名和符合 Schema 的参数 JSON。执行与返回 (Execute & Return): 你需要:
- 解析
tool_calls中的函数名和参数 - 在你的代码中实际执行对应的函数
- 将函数执行结果包装成一条
role: "tool"的 message - 再次调用 API,将工具执行结果发送给模型
- 模型基于工具返回的结果,生成最终的用户回复
- 解析

# 4.2 ReAct 模式:思考-行动-观察
你会发现,工具调用的结果是通过又一次调用传递给大模型的,大模型会观察工具调用的结果,然后思考任务是否完成,从而回复你最终答案或继续行动(调用工具)。这和你之前学过的"多轮对话"很相似。
我们把这种思考——行动——观察的循环模式称为 ReAct,按照此模式工作的 Agent 称为 ReAct Agent。
手动实现 ReAct Agent 的逻辑比较复杂。为了简化开发流程,我们将使用 AgentScope 这一生产级 Agent 框架——它已经帮你封装好了 ReAct Agent 和工具调用的完整逻辑。
AgentScope 是一套为开发者设计的、生产级别的 Agent 框架。它通过规范化的方式定义智能体的通信、记忆和工具调用,让你能专注于业务逻辑而非底层实现。AgentScope 的核心优势包括:
- 开箱即用的 ReAct Agent:内置了完整的"思考-行动-观察"循环逻辑
- 灵活的工具管理:通过
Toolkit类统一管理工具函数,支持自动解析工具的 JSON Schema- 多模型支持:兼容 OpenAI、DashScope(通义千问)、Anthropic 等主流 LLM API
- 状态管理:自动处理对话历史、工具调用记录等状态
- 异步支持:所有核心功能都支持异步调用,提升性能
让我们来看一下 AgentScope 是怎么实现刚才的工具调用的:

import json
# 1. 定义工具列表,包含每个函数的JSON Schema描述
tools = [
{
"type": "function",
"function": {
"name": "search_arxiv_paper",
"description": "在 Arxiv.org 上搜索学术论文",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "论文的标题或关键词"},
},
"required": ["query"],
},
}
}
]
# 2. 发起第一次API调用,让模型决策
messages = [{"role": "user", "content": "帮我找一下那篇经典的 Transformer 论文 'Attention Is All You Need'"}]
response = client.chat.completions.create(
model="qwen-plus", messages=messages, tools=tools, tool_choice="auto"
)
response_message = response.choices[0].message
# 3. 检查模型是否决定调用工具并执行
if response_message.tool_calls:
tool_call = response_message.tool_calls[0]
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
print(f"模型决定调用工具: `{function_name}`")
print(f"参数: {function_args}")
# 这里我们模拟函数执行结果
tool_result = json.dumps({"paper_id": "1706.03762", "url": "https://arxiv.org/abs/1706.03762", "title": "Attention Is All You Need"})
print(f"工具执行结果: {tool_result}")
# 4. 将模型的决策和工具的执行结果一起传回,让模型生成最终答复
messages.append(response_message)
messages.append(
{"tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": tool_result}
)
final_response = client.chat.completions.create(model="qwen-plus", messages=messages)
print("\n模型的最终回复:")
print(final_response.choices[0].message.content)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
你会发现,工具调用的结果是通过又一次调用传递给大模型的,大模型会观察工具调用的结果,然后思考任务是否完成,从而回复你最终答案或继续行动(调用工具)。这和你之前学过的"多轮对话"很相似。
我们把这种思考——行动——观察的循环模式称为 ReAct,按照此模式工作的 Agent 称为 ReAct Agent。
手动实现 ReAct Agent 的逻辑比较复杂。为了简化开发流程,我们将使用 AgentScope 这一生产级 Agent 框架——它已经帮你封装好了 ReAct Agent 和工具调用的完整逻辑。
AgentScope 是一套为开发者设计的、生产级别的 Agent 框架。它通过规范化的方式定义智能体的通信、记忆和工具调用,让你能专注于业务逻辑而非底层实现。AgentScope 的核心优势包括:
- 开箱即用的 ReAct Agent:内置了完整的"思考-行动-观察"循环逻辑
- 灵活的工具管理:通过
Toolkit类统一管理工具函数,支持自动解析工具的 JSON Schema- 多模型支持:兼容 OpenAI、DashScope(通义千问)、Anthropic 等主流 LLM API
- 状态管理:自动处理对话历史、工具调用记录等状态
- 异步支持:所有核心功能都支持异步调用,提升性能
让我们来看一下 AgentScope 是怎么实现刚才的工具调用的:
import asyncio
from agentscope.agent import ReActAgent
from agentscope.tool import Toolkit, ToolResponse
from agentscope.model import DashScopeChatModel
from agentscope.message import Msg, TextBlock
from agentscope.formatter import DashScopeChatFormatter
# 1. 定义一个工具,使用 ToolResponse 返回结果
def search_arxiv_paper(query: str) -> ToolResponse:
"""在 Arxiv.org 上搜索学术论文。
Args:
query (str): 搜索关键词
"""
print(f"--- [工具执行中] 正在 Arxiv 搜索: {query} ---")
# 此处模拟搜索结果
paper_url = "https://arxiv.org/abs/1706.03762"
return ToolResponse(
content=[
TextBlock(
type="text",
text=f"已成功找到论文 '{query}',你可以在这里访问:{paper_url}",
)
]
)
async def run_agentscope_example():
# 2. 将工具函数注册到工具箱(Toolkit)中
toolkit = Toolkit()
toolkit.register_tool_function(search_arxiv_paper)
# 3. 创建一个 ReActAgent 并为其配备工具箱
agent = ReActAgent(
name="Course Research Agent",
sys_prompt="你是一个课程研究助理,擅长帮人搜集和整理学习资料。",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY")
),
toolkit=toolkit,
formatter=DashScopeChatFormatter()
)
# 4. 向 Agent 发送消息,它会自动完成所有步骤
user_request = "帮我找一下那篇经典的 Transformer 论文 'Attention Is All You Need'"
msg = Msg(name="user", content=user_request, role="user")
print(f"用户请求: {user_request}\n")
await agent(msg)
# 运行示例
try:
# 在Jupyter Notebook环境中,可以直接await协程
await run_agentscope_example()
except NameError:
# 在普通Python脚本中,需要使用asyncio.run()来运行异步函数
asyncio.run(run_agentscope_example())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
与之前手动实现的 OpenAI Function Calling 相比,AgentScope 的优势在于:
- 工具定义更简洁:只需要写带文档字符串的普通 Python 函数,框架会自动解析生成 JSON Schema
- 无需手动解析:
ReActAgent内部自动处理tool_calls的解析、函数执行、结果包装等繁琐步骤 - 自动管理对话历史:框架会自动记录用户消息、工具调用、工具结果等,无需手动维护
- 支持多轮工具调用:如果一次工具调用不够,Agent 会自动继续思考并调用更多工具,直到完成任务
看到 AgentScope 的简洁实现,你可能会疑惑:既然有现成框架,为什么还要学习前面那套繁琐的手动实现?
这是因为:
理解底层原理:框架内部就是在执行"调用模型 → 解析 tool_calls → 执行函数 → 再次调用模型"这套流程。了解机制才能调试问题。
自定义需求:生产环境常需实现权限验证、缓存、重试、日志监控等特殊逻辑,理解底层才能扩展框架。
兼容性保障:部分模型或平台不支持标准 Function Calling 格式时,手动实现可作为降级方案。
# 5 MCP 协议:工具的规模化管理
# 5.1 工具复用的挑战
你已经用 Function Calling 实现了 web_search,并在 tools 参数里写好 JSON Schema,模型按需调用。但你发现这套机制有一个隐患:在 Agent 侧硬编码了 web_search 特定版本的 Schema,维护成本很高,你需要一种更灵活的工具接入方式。
从工具提供方的角度看,问题也很明显。web_search 服务想被更多 AI 应用调用,但 Function Calling 模式下,它无法主动"接入" AI 生态,只能被动等待每个 Agent 开发者自行发现,也无法保证开发者对其 Schema 的描述质量。
# 5.2 MCP 的解耦思想
为解决这一问题,Anthropic 公司提出了 MCP(Model Context Protocol,模型上下文协议),它的核心思想是"谁提供工具,谁定义工具"。将工具定义的职责从 Agent(消费方)转移到工具服务(提供方)。
在 MCP 中,工具提供方称为 MCP Server,负责声明工具(名称、描述和参数);工具消费方称为 MCP Client,负责连接 MCP Server 并拉取工具定义。这样,Agent 只需集成 MCP Client,就能动态发现并拉取 MCP Server 声明的最新能力定义,无需在代码中硬编码工具 Schema。

通过解耦工具的定义与使用,MCP 解决了工具"如何被发现和管理"的规模化问题。
关联思考:USB 协议
你可以将 MCP 类比为现实世界中的 USB 协议。在 USB 出现之前,每种外设(鼠标、键盘、打印机)都有自己独特的接口,计算机需要为每一种接口都做适配。而 USB 协议统一了这一切,任何符合该协议的设备都可以即插即用。
- Function Calling 就像是计算机主板上的一个内部总线,它定义了 CPU 如何与某个特定组件通信。
- MCP 则像是外部的 USB 接口,它定义了一个开放标准,让无数第三方设备能够轻松地接入这个生态系统。
# 5.3 用 MCP 重构 web_search 工具调用
理解了 MCP 的解耦思想后,你希望用 MCP 重构之前的 web_search,以降低后续的维护成本。为了降低开发和调试难度,你可以先在本地跑通 MCP Client,并使用本地的 mock Server 验证其功能,再切换到 web_search 的线上 MCP Server。
# 5.3.1 本地调试 MCP Client:stdio
在这一步中,MCP Client 和 Server 都运行在本地,两者通过 stdio (opens new window) 通信。同时,Server 端用 mock 数据模拟 web_search 线上 MCP 服务的返回结果。
MCP 官方 Python SDK 提供了 FastMCP 框架,可以快速将 web_search 函数改造为 MCP Server:
%%writefile run_mcp_server_example.py
# 上一句魔法命令在 Cell 执行时自动在本地生成该代码文件,方便 MCP Client 在本地拉起该服务
from datetime import datetime
from mcp.server.fastmcp import FastMCP
# 创建本地 MCP Server 实例,模拟联网搜索服务
mcp = FastMCP("MockWebSearch")
# @mcp.tool() 装饰器把普通函数注册为 MCP 工具
@mcp.tool()
def web_search(query: str, max_results: int = 3) -> str:
"""模拟联网搜索,根据关键词返回搜索结果。
Args:
query: 搜索关键词
max_results: 最大返回结果数量,默认为 3
"""
mock_db = {
"大型语言模型": [
{"title": "GPT-5 发布:多模态能力再次突破",
"snippet": "OpenAI 发布了 GPT-5,在推理和多模态理解方面取得显著进步。",
"date": "2026-04-10"},
{"title": "Qwen3 开源模型系列全面升级",
"snippet": "阿里云通义千问发布 Qwen3,在数学推理、代码生成等方面全面超越前代。",
"date": "2026-04-08"},
{"title": "大语言模型在科学发现中的应用综述",
"snippet": "Nature 综述总结了 LLM 在药物发现、材料科学等领域的最新应用。",
"date": "2026-04-05"},
],
}
results = []
for key, items in mock_db.items():
if key in query or query in key:
results.extend(items)
if not results:
results = [{"title": f"关于「{query}」的搜索结果",
"snippet": f"这是关于「{query}」的模拟结果。",
"date": datetime.now().strftime("%Y-%m-%d")}]
lines = [f"搜索「{query}」共找到 {len(results[:max_results])} 条结果:\n"]
for i, r in enumerate(results[:max_results], 1):
lines.append(f"{i}. 【{r['title']}】\n {r['snippet']}\n 日期: {r['date']}\n")
return "\n".join(lines)
if __name__ == "__main__":
# 以 stdio 方式启动,等待 Client 端(父进程)通过 stdin/stdout 通信
mcp.run(transport="stdio")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
mock Server 已就绪,现在使用 Client 来调用工具:
import asyncio
import os
import sys
from agentscope.agent import ReActAgent
from agentscope.mcp import StdIOStatefulClient
from agentscope.tool import Toolkit
from agentscope.model import DashScopeChatModel
from agentscope.message import Msg
from agentscope.formatter import DashScopeChatFormatter
async def run_local_mcp_example():
# 1. 配置 MCP 客户端,指向本地工具服务
# 这里通过 stdio 启动同目录下的 run_mcp_server_example.py(模拟联网搜索MCP服务)
web_search_client = StdIOStatefulClient(
name="web_search_service", # 当前客户端的名称
command=sys.executable, # 使用子进程启动 MCP Server
args=["run_mcp_server_example.py"], # 本地 MCP Server 脚本
cwd=os.getcwd(),
)
await web_search_client.connect() # stdio 有状态客户端需要显式连接
# 2. 工具发现:Client 自动向 Server 询问"你有什么工具?"
# Server 返回工具清单,注册到 Agent 的工具箱中
toolkit = Toolkit()
await toolkit.register_mcp_client(web_search_client)
# 3. 创建 ReAct Agent,配备工具箱
agent = ReActAgent(
name="Research Assistant Agent",
sys_prompt="你是一个课程研究助理,擅长使用工具搜集和整理最新的教学素材。",
model=DashScopeChatModel(
model_name="qwen-plus", api_key=os.environ.get("DASHSCOPE_API_KEY")
),
toolkit=toolkit,
formatter=DashScopeChatFormatter()
)
# 4. 发起任务
user_request = "我正在为'大模型原理'课程搜集素材,请帮我搜索一下最近关于'大型语言模型'的最新进展。"
msg = Msg(name="user", content=user_request, role="user")
print(f"用户请求: {user_request}\n")
response_msg = await agent(msg)
await web_search_client.close() # stdio 有状态客户端用完后需要显式关闭
await run_local_mcp_example()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
运行 Client 后,你会看到 Agent 成功调用了 web_search 工具并返回了搜索结果。
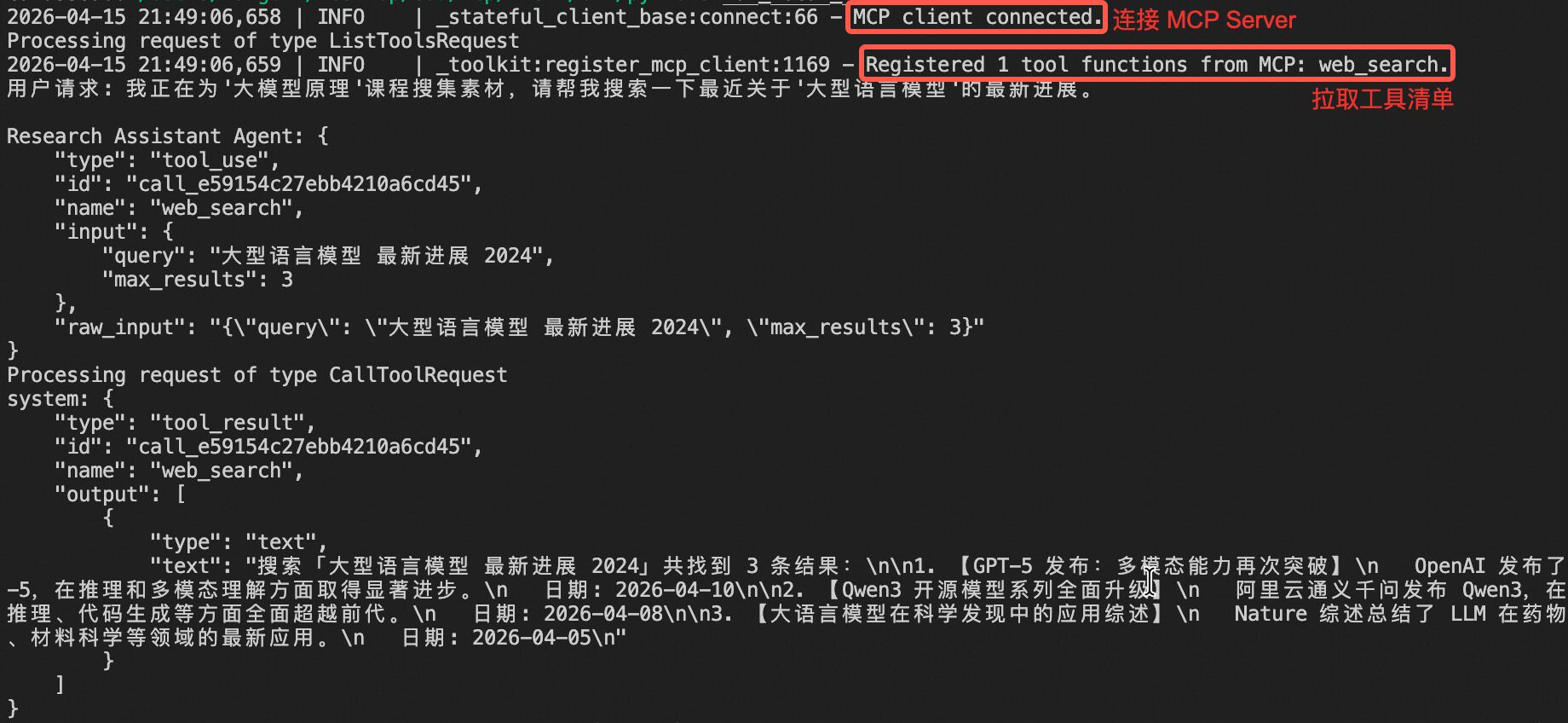
Agent 启动时,MCP Client 自动连接 MCP Server,拉取工具清单(名称、描述、参数)。拿到清单后,后续流程与 1.2 的 Function Calling 类似——选择工具、生成参数、执行调用、返回结果。

# 5.3.2 接入线上 MCP 服务:Streamable HTTP
MCP Client 已在本地验证完毕,接下来你就可以接入阿里云百炼平台托管的生产级 WebSearch MCP 服务了,只需稍微修改 Client 的传输方式:
| 本机模式(stdio) | 线上模式(Streamable HTTP) |
|---|---|
| |
关键变化是传输方式从 stdio 切换为 Streamable HTTP (opens new window)(代码中 transport="streamable_http")。
运行此代码前,请先前往阿里云百炼官网 (opens new window)开通联网搜索 MCP 服务,并了解其计费详情。
import asyncio
import os
from agentscope.agent import ReActAgent
from agentscope.mcp import HttpStatelessClient
from agentscope.tool import Toolkit
from agentscope.model import DashScopeChatModel
from agentscope.message import Msg
from agentscope.formatter import DashScopeChatFormatter
async def run_mcp_example():
# 1. 配置 MCP 客户端,指向远程工具服务
# 这里连接的是阿里云 DashScope 公开的联网搜索 MCP 服务
web_search_client = HttpStatelessClient(
name="web_search_service", # 为这个客户端起一个名字
transport="streamable_http",
url="https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/mcp",
headers={"Authorization": "Bearer " + os.environ.get("DASHSCOPE_API_KEY")},
)
# 2. 将 MCP 客户端注册到工具箱
# Agent 在启动时会自动通过客户端"发现"远程服务提供的所有工具
toolkit = Toolkit()
await toolkit.register_mcp_client(web_search_client)
# 3. 创建 Agent,并配备包含 MCP 工具的工具箱
agent = ReActAgent(
name="Research Assistant Agent",
sys_prompt="你是一个课程研究助理,擅长使用工具搜集和整理最新的教学素材。",
model=DashScopeChatModel(
model_name="qwen-plus", api_key=os.environ.get("DASHSCOPE_API_KEY")
),
toolkit=toolkit,
formatter=DashScopeChatFormatter()
)
# 4. 提出一个需要远程工具才能回答的问题
user_request = "我正在为'大模型原理'课程搜集素材,需要一个调用外部实时数据的例子,比如帮我搜索一下最近关于'大型语言模型'的最新进展。"
msg = Msg(name="user", content=user_request, role="user")
print(f"用户请求: {user_request}\n")
response_msg = await agent(msg)
try:
# 在 Jupyter Notebook 环境中,可以直接 await 协程
await run_mcp_example()
except NameError:
# 在普通 Python 脚本中,需要使用 asyncio.run() 来运行异步函数
asyncio.run(run_mcp_example())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
在这个例子中,你通过 MCP 解决了 web_search 工具在 Agent 侧硬编码 Schema 的问题。
- stdio:MCP Server 和 Client 在同一台机器上,适合本地开发调试,也是 Claude Desktop、Cursor 等 IDE 集成本地 MCP Server 的常见方式。
- Streamable HTTP:MCP Server 部署在远端,适合多个 Agent 或多个用户共用同一个 MCP Server 的生产环境。
至此,你已掌握从单工具函数、可靠意图识别到规模化工具管理的完整链路。你的 Agent 现在可以稳定高效地与外部世界交互。
# 6 总结
让我们回顾一下你在本节学到的知识:
- 为模型连接外部世界:你学会了如何为 Agent 编写工具函数来获取外部信息,并从脆弱的
if/else规则判断,升级到利用大模型自身的理解能力来决定调用哪个工具。 - 手动实现可靠的工具调用:你掌握了通过构建"引导-校验-重试"的闭环,让模型稳定输出结构化的 JSON 指令,并理解了这是实现健壮工具调用的底层逻辑。
- 函数调用与工具发现:你学习了"函数调用"这一行业标准,它将工具调用的复杂流程封装成简单的 API。更进一步,你也了解了 MCP 协议如何将工具的定义与使用解耦,解决了规模化复用与维护的难题。
- ReAct 循环与开发框架:你认识到工具调用是实现 ReAct (思考-行动-观察) 循环模式的关键,并学会使用 AgentScope 这样的开发框架,将你从手动实现的繁琐流程中解放出来,更专注于业务逻辑。
# 🔥 课后小测验
# 🔍 单选题 3.1.1
你的Agent已经集成了日历、邮件、代码仓库三个工具,每次新增工具都要修改Agent代码、更新JSON Schema、重新部署。团队计划再接入十几个内部系统。你该如何降低工具集成的维护成本❓ - A. 把所有工具的JSON Schema抽取到一个统一的配置文件中,新增工具只改配置不改代码
- B. 引入MCP协议,让每个工具作为独立服务运行,Agent通过标准协议动态发现和调用
- C. 为所有工具封装一个统一的HTTP网关,Agent只需调用网关的单一接口即可转发请求
- D. 减少工具数量,将功能相近的工具合并为一个多功能工具以降低管理复杂度
【点击查看答案】
✅ 参考答案:B 📝 解析: A只是把配置从代码中分离出来,减少了改代码的频率,但Agent仍然要感知所有工具的Schema定义,且每次新增仍需手动更新配置并重启。C的HTTP网关统一了调用入口,但Agent失去了对每个工具能力的感知,无法根据任务自主选择合适的工具。D违背了扩展需求,合并工具会降低专业性且增加单个工具的复杂度。B是正解:MCP让工具作为独立服务暴露自己的能力描述,Agent通过标准协议动态发现可用工具,新增工具无需修改Agent代码,实现了工具与Agent的解耦。
# ✉️ 评价反馈
欢迎你参与阿里云大模型ACP课程问卷 (opens new window) 反馈学习体验和课程评价。 你的批评和鼓励都是我们前进的动力!