
 用 Skill 将能力固化为可复用流程
用 Skill 将能力固化为可复用流程
# 3.5 用Skill将能力固化为可复用流程
# 🚄 前言
Memory让Agent记住了你的偏好,但具体的工作方法每次还是要在对话里重新交代。Skill就是解决这个问题的:把"在什么情况下,正确做法是什么"固化为可触发的专属流程。这节课你将学会从零设计Skill,并探索Skill的团队化应用。
# 🍁 课程目标
你将学到:
- 理解从"临时Prompt"到"可复用Skill"的演进逻辑
- Skill的结构:触发条件、工作流、知识库
- 如何写出高质量的Skill(五步编写法)
- Skills-as-Code:让Skill进入版本控制和CI/CD
- Skill生态:社区共享与复用
# 加载百炼的 API Key 用于调用千问大模型
import os, sys
os.chdir(os.path.join(os.path.dirname(os.path.abspath('')), 'course_core'))
sys.path.insert(0, os.getcwd())
from openai import OpenAI
from config.load_key import load_key
load_key()
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
print(f"API Key 已加载:{os.environ['DASHSCOPE_API_KEY'][:5]}*****")
2
3
4
5
6
7
8
9
10
11
12
13
14
回顾一下你走过的路:你先为 Agent 装上了工具调用、反思和记忆等单体能力,用这些能力让它能处理多步骤任务,进而应对更复杂的场景。到这一步,Agent 在能力层面已经相当完备了。
你大概试过让 AI 帮你审代码、改文章、检查文档——它确实会给反馈,但总觉得隔靴搔痒:提的问题要么太泛("建议增加注释"),要么抓不住重点(漏掉了真正的 bug,反而纠结命名风格)。问题不在于 Agent 能力不够,而在于它不知道你的标准是什么。
本章用"审查技术教程"作为贯穿案例——在一家教育内容公司,审查同事写的教程是日常工作的一部分,你手边就有现成的素材(docs/ 目录下的 Jupyter Notebook)。但这里要解决的问题是通用的:怎样把你脑中的专业标准交给 Agent?
假设你收到一个任务:审查一份同事写的技术教程。这份教程是 docs 目录下的《Python 数据分析实战》——一个完整的 Jupyter Notebook,包含近 300 个单元格,从环境准备、数据清洗、特征工程一直到可视化和综合业务分析。你最容易想到的方法就是:用你已有的 Agent,直接给它一句话。
# 1 用 Prompt 做教程审查
你已经有了一个功能完备的 ReActAgent。给它装上一个 read_file 工具让它能读取文件,然后像平时使用 AI 助手一样,直接给它一句话:
import asyncio
import os
from agentscope.agent import ReActAgent
from agentscope.formatter import DashScopeChatFormatter
from agentscope.memory import InMemoryMemory
from agentscope.message import Msg, TextBlock
from agentscope.model import DashScopeChatModel
from agentscope.tool import Toolkit, ToolResponse
async def read_file(file_path: str) -> ToolResponse:
"""读取指定路径的文件内容。
Args:
file_path: 要读取的文件路径
Returns:
文件内容的字符串
"""
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
return ToolResponse(content=[TextBlock(type="text", text=content)])
async def main():
toolkit = Toolkit()
toolkit.register_tool_function(read_file)
agent = ReActAgent(
name="Course Reviewer",
sys_prompt="你是一个AI助手,能够帮助用户完成各种任务。",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
memory=InMemoryMemory(),
max_iters=8,
)
# 关闭中间过程的控制台输出(工具调用、JSON 等),只保留最终结果
agent.set_console_output_enabled(False)
response = await agent(Msg("user",
"帮我审查一下 docs/Python数据分析实战.ipynb,看看质量怎么样、能不能发布。",
"user"))
# 从返回的 Msg 对象中提取纯文本内容
print(response.get_text_content())
await main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
运行上面的代码,观察 Agent 返回的审查报告。你会发现,它确实给出了反馈——但这些反馈大多是"放之四海而皆准"的通用建议,比如"补充代码注释"、"增加异常处理"、"优化图表显示"、"添加学习资源"等。把"Python 数据分析实战"换成任何一份技术教程,这些建议依然成立。 它们是正确的废话。
而如果你自己抽查一下这份 Notebook,会发现只对这份教程才成立的真正问题,它一个都没提:
- 代码跑不通:课程末尾使用了
pd.ExcelWriter(..., engine='openpyxl')将分析结果导出为 Excel,但环境准备部分只安装了pandas numpy matplotlib seaborn——执行到这里会直接报ModuleNotFoundError。 - 说一套做一套:清洗计划中明确写道用众数填充
city和gender,但实际代码填充的是字符串"未知"——两种策略完全不同,中间没有任何解释。 - 讲解风格问题:课程开篇用了一整段小说式描写("你刚入职一家中型电商公司,工位还没坐热……"),多处出现俏皮话("数据自带各种'惊喜'"、"恭喜你!")。
为什么 Agent 找不到这些真正的问题?
因为 Agent 使用的是通用审查标准——它知道课程应该内容完整、结构清晰、代码可运行,但这只是一个泛化的理解。而你的团队有一套更专业、更细分的审查要求,这些要求只有你和团队成员才知道:
- 代码可执行性:每个代码块能否在干净环境中顺利执行,有没有遗漏的依赖或路径问题
- 内容准确性:技术概念和 API 用法是否与最新文档一致,文本描述和代码实现是否一致
- 学习曲线:知识点的编排是否遵循渐进式设计,有无跳跃过大的地方
- 讲解风格:是否对初学者友好,是否存在俏皮话或多余的情景描写
这些标准存在你和团队成员的经验中——通用模型无从知晓。
💡 小贴士:大模型在审查任务中容易给出"放之四海而皆准"的泛泛建议。要获得有针对性的反馈,关键不是措辞技巧,而是提供明确的审查标准——告诉它你具体在乎什么。
自然的改进思路是:把这些审查标准明确写进 Prompt,告诉 Agent 你的团队到底在乎什么。除了审查标准,你可能还需要告诉它怎么处理 Notebook 格式(.ipynb 是 JSON 结构,代码块、Markdown 块、输出块各有不同字段)。最终 Prompt 可能会变成这样:
请审查 docs/Python数据分析实战.ipynb,按以下标准逐项检查:
## 审查标准
1. 代码可执行性:在干净环境中逐一执行所有代码块,检查是否有遗漏的依赖、
未定义的变量、路径问题。注意 .ipynb 文件是 JSON 格式,代码在
cells[*].source 字段中。
2. 内容准确性:核对 API 用法是否与最新文档一致,检查文本描述和代码实现
是否一致(例如文本说用"众数"填充,代码是否真的用了众数)。
3. 学习曲线:从第一节到最后一节,知识点是否逐步递进,有无跳跃过大的地方。
4. 讲解风格:禁止俏皮话(如"恭喜你解锁了新技能!"),禁止多余的情景描写
(如"你端着咖啡走进办公室……"),术语首次出现时需有解释。
## 输出格式
逐项给出:通过/不通过 + 具体位置 + 修改建议
2
3
4
5
6
7
8
9
10
11
12
13
14
这段 Prompt 比之前那句"帮我审查一下"好多了——它明确了检查什么、怎么检查、输出什么格式。
但如果你真的把它用起来,很快会遇到一些实际问题。想象一下:你今天审查完《Python 数据分析实战》,下周又要审查《机器学习入门》,下个月还有《深度学习实战》。每次你都需要:
- 找到这段 Prompt:它存在你的聊天记录里,可能存在某个文档里,也可能只存在你的脑子里
- 复制粘贴到新对话:每开一轮新会话,就要把这一大段文本重新贴一遍
- 和同事对齐口径:你写了一版 Prompt,同事写了另一版,两个人对"讲解风格"的要求不同——审查结果没有可比性
- 记住上次改了什么:上次审查时你发现"术语首次出现需有解释"这条很重要,补充进去了——但补充到哪个版本了?
这些问题的根源是:Prompt 是会话级别的。它只在当前对话中生效,对话结束,知识就散了。它不是一个可以被存储、被版本管理、被团队共享的独立资源。这就像把操作规范写在便签纸上——你自己用一次没问题,但便签会丢、别人看不到、改了也没人知道。
你需要的是另一种东西:一套可复用的、基于文件的专业知识模块——写一次,存在文件系统里,需要时按需加载到 Agent 的上下文中,不用每次都手动粘贴。
# 2 把审查经验沉淀下来
既然 Prompt 散落在聊天记录里不好用,那就把它固定下来。接下来分四步,逐步构建一套可复用的审查知识库。
# 2.1 从聊天记录到独立文件
首先解决"找不到"的问题。
每次审查都要翻聊天记录找那段 Prompt,既麻烦又容易出错。最直接的改进是:把它保存成一个 Markdown 文件,放在项目目录下。
用脚本创建 course-review.md:
review_guide = """\
# 教程审查指南
## 审查标准
### 1. 代码可执行性
- 所有代码块能否在干净环境中顺利执行
- 有没有遗漏的依赖(如用了 openpyxl 但没安装)
- 有没有未定义的变量或路径问题
### 2. 内容准确性
- 技术概念和 API 用法是否与最新文档一致
- 文本描述和代码实现是否一致(说用众数,代码是否真的用了众数)
- 重要术语首次出现时是否有解释
### 3. 学习曲线
- 知识点的编排是否遵循渐进式设计,有无跳跃过大的地方
- 核心概念是否有动手环节——读者先尝试再学原理,而非先听讲解再看示例
- 开篇是否包含前言和课程目标
### 4. 讲解风格
**禁止俏皮话**:不得出现卖弄聪明的俏皮话、网络流行语、段子式表达。课程语气应当平实、专业、直接。
| 不合格 | 合格 |
|-------|------|
| "恭喜你解锁了新技能!🎉" | "到这里,你已经掌握了 X 的基本用法。" |
| "是不是有种开挂的感觉?" | "相比手动处理,这种方式效率明显更高。" |
| "这就像给模型开了天眼" | "这让模型能够访问外部数据源" |
**禁止多余的情景描写**:场景引入要点到即止——一两句话交代背景和问题即可,不要写小说式的铺垫。
| 不合格 | 合格 |
|-------|------|
| "周一早上九点,你端着咖啡走进办公室,阳光透过百叶窗洒在工位上……" | "主管给了你一份销售数据,要求本周完成分析报告。" |
**判断标准**:如果删掉某段描写后,读者对技术内容的理解不受任何影响,那这段描写就是多余的。
## 输出格式
每项检查给出:
- 状态:通过 / 不通过 / 需人工复核
- 位置:章节名 + 单元格编号
- 说明:具体问题描述和修改建议
"""
with open("course-review.md", "w", encoding="utf-8") as f:
f.write(review_guide)
print("已创建 course-review.md")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
现在让 Agent 按照这份标准审查《Python数据分析实战》:
async def main():
toolkit = Toolkit()
toolkit.register_tool_function(read_file)
agent = ReActAgent(
name="Course Reviewer",
sys_prompt="你是一个AI助手,能够帮助用户完成各种任务。",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
memory=InMemoryMemory(),
max_iters=10,
)
agent.set_console_output_enabled(False)
response = await agent(Msg("user",
"按照 course-review.md 的标准,审查 docs/Python数据分析实战.ipynb",
"user"))
print(response.get_text_content())
await main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
问题解决了一半:文件有了固定位置,不会再丢失;团队成员也可以共享同一份文件。但当你真正开始往里补充细节时,新的麻烦就来了。
# 2.2 从单文件到知识库目录
但 course-review.md 很快会变得很长。你会发现需要补充更多细节:
- pandas 哪些 API 已经过时?(
append已废弃,应该用concat) - 什么样的情景描写算"多余"?需要正例和反例
- 代码注释应该写到什么程度?
如果把这些全塞进一个文件,它会膨胀到几十页,反而难以维护。
更好的做法是:主文件保持精简,详细内容拆到子文件里。
course-review/
├── README.md # 审查流程概述(入口)
├── code-quality.md # 代码可执行性的详细检查项
├── content-accuracy.md # 事实准确性的详细检查项
├── style-guide.md # 讲解风格的正例和反例
└── outdated-api.md # pandas/numpy 过时 API 对照表
2
3
4
5
6
下面用脚本把原来的单文件拆分成这个目录结构。核心思路是:README.md 只保留审查流程和方向索引,具体的检查项、风格要求、API 对照表各自独立成文件。
import os
# 创建目录
os.makedirs("course-review", exist_ok=True)
# ---- 1. README.md:精简的入口文件 ----
# 只列审查流程和四个方向,用链接指向子文件
readme = """\
# 教程审查指南
## 审查流程
1. 提取 Notebook 目录结构,了解整体章节编排
2. 按章节逐段检查,每段对照以下四个方向
3. 汇总审查结果,输出结构化报告
## 审查方向
| 方向 | 详细规则 |
|------|---------|
| 代码可执行性 | 见 [code-quality.md](code-quality.md) |
| 内容准确性 | 见 [content-accuracy.md](content-accuracy.md) |
| 讲解风格 | 见 [style-guide.md](style-guide.md) |
| 过时 API | 见 [outdated-api.md](outdated-api.md) |
## 输出格式
每项检查给出:
- 状态:通过 / 不通过 / 需人工复核
- 位置:章节名 + 单元格编号
- 说明:具体问题描述和修改建议
"""
# ---- 2. code-quality.md:代码可执行性的详细检查项 ----
code_quality = """\
# 代码可执行性检查
## 检查清单
- [ ] 所有代码块能否在干净环境中从上到下顺序执行
- [ ] 依赖是否完整(如用了 openpyxl 但没有 `pip install` 单元格)
- [ ] 有没有未定义的变量、缺失的文件路径
- [ ] 数据文件是否随课程提供,或有明确的下载指引
- [ ] 长耗时操作(模型训练、大文件下载)是否有预期时间提示
## 常见问题
| 问题 | 示例 | 修复建议 |
|------|------|---------|
| 隐式依赖 | 代码中 `import openpyxl` 但未安装 | 在环境准备章节添加 `pip install openpyxl` |
| 路径硬编码 | `pd.read_csv('/home/user/data.csv')` | 改为相对路径或提供下载脚本 |
| 单元格顺序依赖 | Cell 10 使用了 Cell 15 才定义的变量 | 调整单元格顺序,确保自上而下可执行 |
"""
# ---- 3. content-accuracy.md:事实准确性的详细检查项 ----
content_accuracy = """\
# 内容准确性检查
## 检查清单
- [ ] 技术概念和 API 用法是否与最新官方文档一致
- [ ] 文字描述和代码实现是否一致(说用众数,代码是否真的用了众数)
- [ ] 重要术语首次出现时是否有简明解释
- [ ] 数字、公式、图表中的数据是否与代码输出吻合
- [ ] 外部链接是否有效,引用的论文/文档是否标注了版本或日期
## 常见问题
| 问题 | 示例 | 修复建议 |
|------|------|---------|
| 文字与代码不一致 | 文字说"用中位数填充",代码用了 `mean()` | 统一为同一种方法 |
| 术语无解释 | 直接使用"embedding"未做任何说明 | 首次出现时括注中文释义 |
| API 版本过时 | 使用 `df.append()` | 参考 outdated-api.md 替换 |
"""
# ---- 4. style-guide.md:讲解风格的正例和反例 ----
style_guide = """\
# 讲解风格指南
## 规则一:禁止俏皮话
不得出现卖弄聪明的俏皮话、网络流行语、段子式表达。课程语气应当平实、专业、直接。
| 不合格 | 合格 |
|-------|------|
| "恭喜你解锁了新技能!🎉" | "到这里,你已经掌握了 X 的基本用法。" |
| "是不是有种开挂的感觉?" | "相比手动处理,这种方式效率明显更高。" |
| "这就像给模型开了天眼" | "这让模型能够访问外部数据源" |
## 规则二:禁止多余的情景描写
场景引入要点到即止——一两句话交代背景和问题即可,不要写小说式的铺垫。
| 不合格 | 合格 |
|-------|------|
| "周一早上九点,你端着咖啡走进办公室,阳光透过百叶窗洒在工位上……" | "主管给了你一份销售数据,要求本周完成分析报告。" |
**判断标准**:如果删掉某段描写后,读者对技术内容的理解不受任何影响,那这段描写就是多余的。
## 规则三:学习曲线
- 知识点遵循渐进式编排,不能跳跃过大
- 核心概念先动手再讲原理(先尝试,再解释)
- 开篇包含前言和课程目标
"""
# ---- 5. outdated-api.md:过时 API 对照表 ----
outdated_api = """\
# 过时 API 对照表
审查代码时,如发现以下已废弃的 API,请标记为"不通过"并给出替换建议。
## pandas
| 已废弃 | 替换为 | 废弃版本 | 说明 |
|--------|--------|---------|------|
| `DataFrame.append()` | `pd.concat([df1, df2])` | 1.4.0 | append 在 2.0 中已移除 |
| `DataFrame.swaplevel()` 无参数 | 显式传入 `i, j` 参数 | 1.5.0 | 未来版本不再支持隐式参数 |
## numpy
| 已废弃 | 替换为 | 废弃版本 | 说明 |
|--------|--------|---------|------|
| `np.bool` | `np.bool_` 或 `bool` | 1.20.0 | 内置类型别名已移除 |
| `np.int` | `np.int_` 或 `int` | 1.20.0 | 同上 |
| `np.float` | `np.float64` 或 `float` | 1.20.0 | 同上 |
| `np.object` | `np.object_` 或 `object` | 1.20.0 | 同上 |
> 此表需要持续维护——每当库发布新版本时,检查 Release Notes 中的 Deprecation 部分并更新。
"""
# ---- 写入文件 ----
files = {
"course-review/README.md": readme,
"course-review/code-quality.md": code_quality,
"course-review/content-accuracy.md": content_accuracy,
"course-review/style-guide.md": style_guide,
"course-review/outdated-api.md": outdated_api,
}
for path, content in files.items():
with open(path, "w", encoding="utf-8") as f:
f.write(content)
print(f"✅ 已创建 {path}")
print(f"\n拆分完成,共生成 {len(files)} 个文件。")
print("原始的 course-review.md 可以归档或删除。")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
README.md 只列出审查流程和四个大方向,需要看细节时再去读对应的子文件。这样既保持了入口的简洁,又能承载足够丰富的专家知识。
知识库的结构理清了,但审查对象本身也有挑战——那份近 300 个单元格的 Notebook,Agent 能一口气读完吗?
# 2.3 应对长文档:分段检查
还有一个实际问题:Notebook 文件可能很长。《Python 数据分析实战》有近 300 个单元格,一次性塞进上下文会被截断。
一个有经验的审核员不会一口气从头看到尾——她会先翻目录了解结构,然后按章节逐段检查。你可以用脚本帮 Agent 做同样的事。
方法一:提取目录结构
创建一个脚本,从 Notebook 中提取所有 Markdown 标题:
import os
os.makedirs("scripts", exist_ok=True)
extract_toc_code = '''\
import json
import sys
def extract_toc(notebook_path):
"""从 Jupyter Notebook 中提取所有 Markdown 标题,生成带单元格编号的目录。"""
# .ipynb 本质是 JSON 文件,cells 数组包含所有单元格
with open(notebook_path, 'r', encoding='utf-8') as f:
nb = json.load(f)
toc = []
for i, cell in enumerate(nb['cells']):
# 只关注 Markdown 单元格,跳过代码和输出
if cell['cell_type'] == 'markdown':
# cell['source'] 是行列表,拼接后按行扫描标题
source = ''.join(cell['source'])
for line in source.split('\\n'):
if line.startswith('#'):
# 记录单元格编号,方便后续定位
toc.append(f"[Cell {i}] {line}")
return '\\n'.join(toc)
if __name__ == '__main__':
print(extract_toc(sys.argv[1]))
'''
with open("scripts/extract_toc.py", "w", encoding="utf-8") as f:
f.write(extract_toc_code)
print("已创建 scripts/extract_toc.py")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
运行脚本,提取《Python数据分析实战》的目录结构:
import subprocess
result = subprocess.run(
["python", "scripts/extract_toc.py", "docs/Python数据分析实战.ipynb"],
capture_output=True, text=True
)
print(result.stdout)
2
3
4
5
6
7
Agent 就能先看到完整的章节结构,再决定从哪里开始细读。
方法二:转换为 Markdown 便于编辑
如果你需要频繁修改 Notebook,可以用 jupytext 在 .ipynb 和 .md 之间同步:
%%bash
# 安装
pip install jupytext
# Notebook → Markdown
jupytext --to md docs/Python数据分析实战.ipynb
# 编辑 Markdown 后同步回 Notebook
jupytext --to ipynb docs/Python数据分析实战.md
2
3
4
5
6
7
8
9
Markdown 格式更容易用文本工具检索和编辑。
扩展阅读:为什么不直接把整个文件塞进上下文?
当前主流模型的上下文窗口越来越长(128K–1M tokens),理论上放得下整个 Notebook。但研究表明,模型对上下文中段的信息处理能力明显下降——这被称为 Lost in the Middle 效应。即使文件能放进去,中间部分的问题也容易被忽略。分段检查不仅绕过了窗口限制,还能让 Agent 对每一段都保持高质量的注意力。
把这些脚本也放进 1.2.2 创建的 course-review/ 目录:
import os
import shutil
# 创建 scripts 子目录
os.makedirs("course-review/scripts", exist_ok=True)
# 将目录提取脚本移入
if os.path.exists("scripts/extract_toc.py"):
shutil.move("scripts/extract_toc.py", "course-review/scripts/extract_toc.py")
# 创建格式转换脚本
convert_script = """\
#!/bin/bash
jupytext --to md "$1"
"""
with open("course-review/scripts/convert_format.sh", "w") as f:
f.write(convert_script)
os.chmod("course-review/scripts/convert_format.sh", 0o755)
print("已将辅助脚本整合到 course-review/scripts/ 目录")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
加上 1.2.2 已经创建的文件,完整的目录结构如下:
course-review/
├── README.md
├── code-quality.md
├── content-accuracy.md
├── style-guide.md
├── outdated-api.md
└── scripts/
├── extract_toc.py # 提取 Notebook 目录
└── convert_format.sh # jupytext 格式转换
2
3
4
5
6
7
8
9
知识库越来越完善了。但如果每次对话都把整个目录一股脑塞给 Agent,又回到了另一个问题上。
# 2.4 按需加载:不要一次塞全部
现在你有了一个完整的审查知识库。但新的问题来了:如果每次对话都把整个目录塞给 Agent,上下文会很拥挤。
回顾 1.2.2 中创建的 README.md,它的"审查方向"表格已经用 Markdown 链接指向了子文件:
| 方向 | 详细规则 |
|---|---|
| 代码可执行性 | 见 code-quality.md |
| 内容准确性 | 见 content-accuracy.md |
| 讲解风格 | 见 style-guide.md |
| 过时 API | 见 outdated-api.md |
这个结构天然支持按需加载——Agent 拿到 README.md 后,只需要根据当前检查的方向,去读取对应的子文件:
- 审查代码质量时 → 加载
code-quality.md和outdated-api.md - 审查讲解风格时 → 加载
style-guide.md - 处理长 Notebook 时 → 先运行
extract_toc.py,再按章节逐段检查
Agent 不需要一开始就加载所有内容,而是根据当前检查的阶段,按需读取对应的文件。
# 2.5 对比:改造前 vs 改造后
下图展示了从"一次性 Prompt"到"可复用知识库"的四步演进:
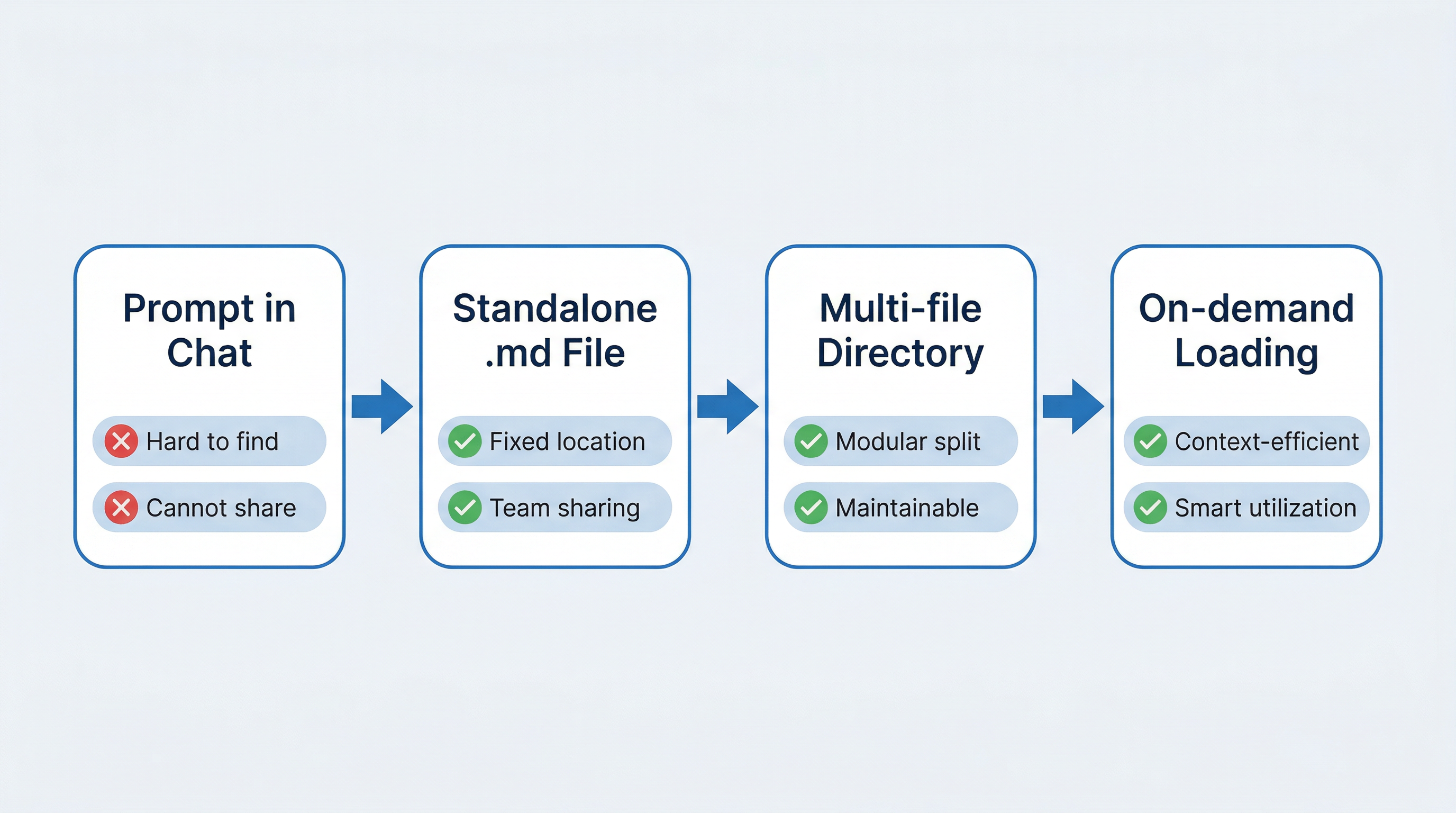
回顾一下这四步带来的变化:
| 改造前(一次性 Prompt) | 改造后(知识库目录) |
|---|---|
| 散落在聊天记录里 | 存在固定位置,可版本管理 |
| 所有内容混在一起 | 主文件精简,详细内容拆分 |
| Notebook 太长会截断 | 先提取目录,按章节逐段检查 |
| 每次都要塞全部内容 | 按需加载,避免上下文拥挤 |
| 一个人写,标准不统一 | 团队共享同一份文件,可协作迭代 |
现在你手上有了一个完整的 course-review/ 目录——它不是一段 Prompt,而是一套可复用、可维护、可团队协作的专家知识库。
回顾一下 1.1 和 1.2 的核心收获:
- 通用 Prompt 的局限:Agent 使用通用标准审查教程时,会遗漏团队特有的专业要求——代码依赖完整性、文本与代码一致性、讲解风格合规性等细分标准,通用模型无从知晓
- Prompt 是会话级别的:它只在当前对话中生效,无法被存储、版本管理和团队共享
- 文件化解决复用问题:将审查标准保存为独立文件,团队成员共享同一份标准
- 目录化解决维护问题:主文件保持精简,详细内容拆分到子文件,各司其职
- 按需加载解决效率问题:根据当前检查阶段加载对应内容,避免上下文拥挤
但这套方案仍然是"人驱动"的——你需要手动告诉 Agent 去读哪个文件、按什么流程检查。有没有办法让 Agent 自己知道该怎么做?
# 3 Agent Skills:将专家知识注入 Agent
# 3.1 Skill 的概念
回顾一下你最开始做的事情。每次让 Agent 审核课程,你都要重新描述审核标准、工作流程、质量要求、反模式清单……这些信息本质上是稳定的,但你却在每次对话中反复拼凑。漏掉一条检查项,审核质量就下降;换一个人来做,又要从头交代一遍。
这就是你为什么要把一段冗长的一次性 Prompt 拆解成 course-review/ 目录的原因——你想把这些稳定的知识固定下来,不再每次重复。
你构建的这个东西,就是一个 Skill。
Skill 是扩展 Agent 能力的模块化功能单元。 每个 Skill 将指令、元数据和可选资源(脚本、模板等)打包在一起,Agent 在遇到匹配的任务时自动调用。
来看你构建的 CourseReviewSkill:
course-review/
├── SKILL.md # 主指令(入口)
├── code-quality.md # 代码可执行性的详细检查项
├── content-accuracy.md # 事实准确性的详细检查项
├── style-guide.md # 讲解风格的正例和反例
├── outdated-api.md # 过时 API 对照表
└── scripts/
├── extract_toc.py # 提取 Notebook 目录
└── convert_format.sh # jupytext 格式转换
2
3
4
5
6
7
8
9
其中 SKILL.md 就是 1.2.2 中那个 README.md 的升级版——入口文件从 README.md 改名为 SKILL.md(Skill 规范的约定),同时补充了在 1.2 中缺失的两部分内容:更细化的工作流程步骤,以及审查中应避免的反模式。以下是节选:
# CourseReviewSkill
## 审查流程
1. 提取 Notebook 目录结构,了解整体章节编排
2. 按章节逐段检查,对照以下方向:
- 代码可执行性(详见 [code-quality.md](code-quality.md))
- 内容准确性(详见 [content-accuracy.md](content-accuracy.md))
- 讲解风格(详见 [style-guide.md](style-guide.md))
- 过时 API(详见 [outdated-api.md](outdated-api.md))
3. 汇总审查结果,按输出格式生成报告
## 反模式清单
- ❌ 不要修改代码中的变量名、API版本号
- ❌ 不要跳过任何一项检查
- ❌ 不要在审核过程中引入新的技术概念
## 输出格式
每项检查给出:通过/不通过/需人工复核 + 位置 + 修改建议
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
对比 1.2.2 中的 README.md,变化有两点:一是审查流程从简要的 3 步细化为更具操作性的步骤(每个方向都带了链接),二是新增了反模式清单——这些都是在后续使用中沉淀下来的经验。
注意步骤 2 中的链接——这就是渐进式披露:主文件只给出流程框架,详细的检查清单放在子文件里。Agent 执行到对应步骤时,才会去读取链接背后的文档,既不浪费上下文窗口,又不会遗漏细节。
这样设计带来了三个好处:
不再重复交代。 审核标准、工作流程、反模式清单——这些稳定的知识写进 Skill 后就固定了。无论谁来用、用多少次,Agent 都按同一套标准执行。你的偏好也一样:喜欢先用 jupytext 把 Notebook 转成 Markdown 再审核、喜欢用表格输出检查结果——写进 Skill,不用每次重复交代。
不会污染无关任务。 Agent 会根据任务自动判断是否需要这个 Skill。当你让它审核课程时,它会加载 CourseReviewSkill;当你让它写代码时,不会把审核规则塞进上下文。当然,你也可以显式指定——比如告诉 Agent"按照 course-review 的标准来检查这份文档"。
不会撑爆上下文。 即使激活了 Skill,Agent 也不会把所有子文件一股脑读完。它先读 SKILL.md 获取流程框架,执行到"检查技术概念准确性"这一步时,才去读 content-accuracy.md。上下文窗口始终只装当前步骤需要的内容。
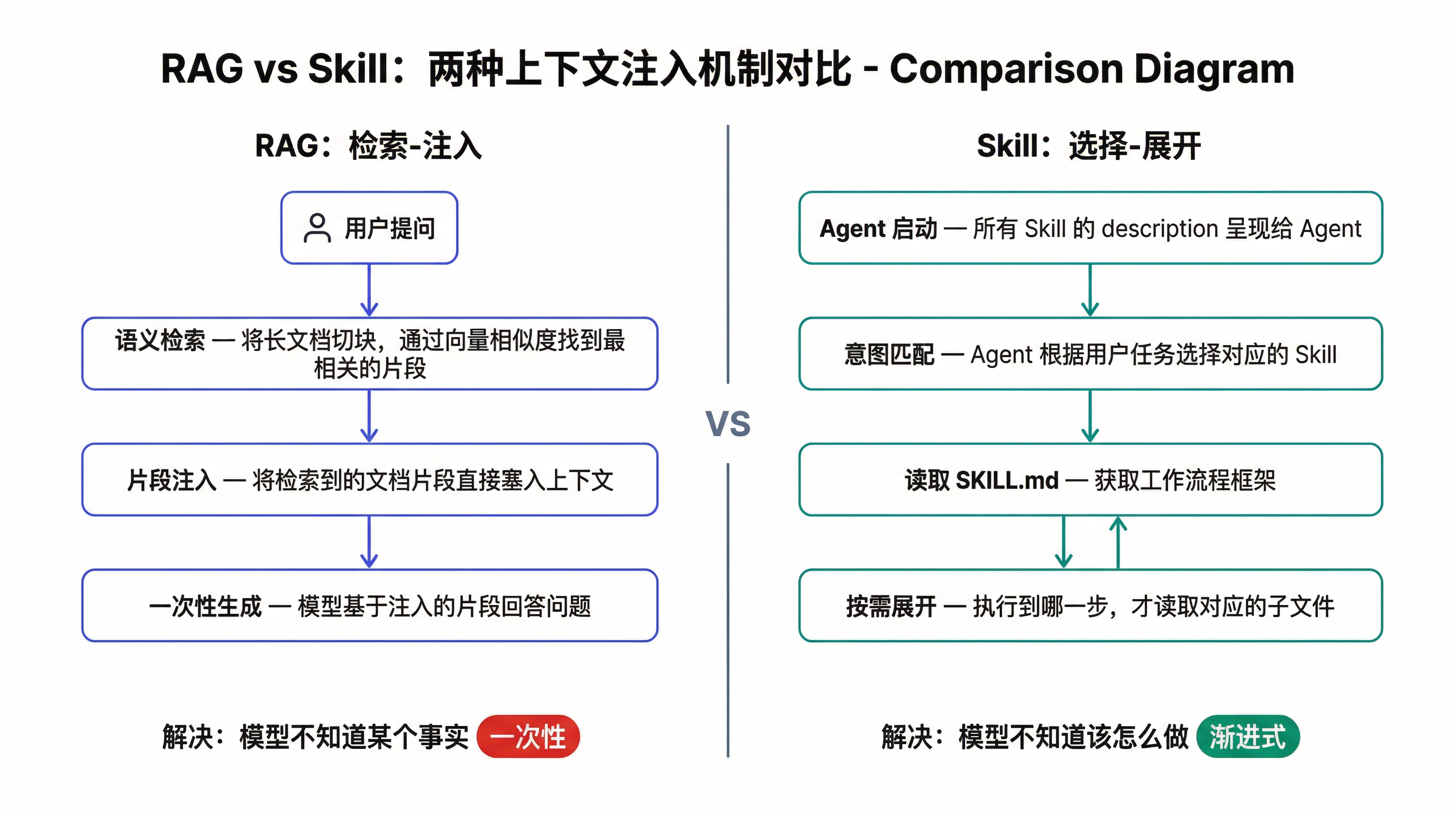
💡 Skill 和 RAG 的区别
你可能会问:这和 RAG 有什么区别?不都是给 Agent 补充信息吗?
首先,它们要解决的问题不同。RAG 解决的是"模型不知道某个事实"——比如某份文档的内容、某个产品的参数;Skill 解决的是"模型不知道该怎么做"——比如审核课程应该按什么流程、遇到过时 API 该如何处理。
其次,从上下文的角度看,信息进入上下文的方式也不同:
RAG 是"检索-注入"。 用户提问后,系统把长文档切成块,通过语义检索找到最相关的几个片段,直接塞进上下文。模型拿到的是一堆事实材料,用它们来回答问题。整个过程是一次性的——检索完就注入,注入完就生成。
Skill 是"选择-展开"。 Agent 启动时,所有可用 Skill 的描述(类似工具描述)会完整呈现给它。Agent 根据当前任务判断是否需要、需要哪个 Skill。只有在选择激活某个 Skill 之后,才会读取它的详细内容——而且是逐步展开的,执行到哪一步才读取对应的子文件。
# 3.2 Skill 的结构
你已经见过一个简单的 Skill——CourseReviewSkill,里面有 SKILL.md、几份检查清单和辅助脚本。现在来看一个正式的 Skill 应该长什么样。
回想一下 Skill 的工作方式:Agent 启动时看到所有 Skill 的描述,判断当前任务需要哪个,选中后才读取详细内容。这意味着一个 Skill 必须同时解决两个问题:让 Agent 快速判断"要不要用",以及告诉 Agent "具体怎么做"。
SKILL.md 就是为此设计的。它由两部分组成——YAML frontmatter 解决第一个问题,Markdown body 解决第二个问题:
---
name: course-review
description: |
审查课程内容的技术准确性、代码正确性和教学质量。当用户要求审查、审计或评估现有的课程或培训材料时使用此技能。
---
# 课程审查技能
## 快速开始
1. 运行代码验证:`python scripts/validate_code.py`
2. 对照 [CHECKLIST.md](CHECKLIST.md) 检查术语
...
2
3
4
5
6
7
8
9
10
11
12
--- 包裹的部分就是 YAML frontmatter。Agent 还没决定是否使用这个 Skill 时,就已经能看到这里的信息了——就像你在书店翻书,先看封底简介再决定要不要读。
name:Skill 的唯一标识。用户可以通过 /course-review 显式调用它,所以取一个一目了然的名字比什么都重要。
description:这是 Skill 能否被正确触发的关键。Agent 面对用户指令时,需要从可能上百个 Skill 中选出正确的那一个——它依赖的就是每个 Skill 的 description。
一个好的 description 需要回答两个问题:
- 这个 Skill 做什么(功能描述)
- 什么时候应该触发它(触发条件)
# ❌ 模糊的 description
description: 处理课程相关任务。
# ✅ 明确的 description
description: |
审查课程内容的技术准确性、代码正确性和教学质量。当用户要求审查、审计或评估现有的课程或培训材料时使用此技能。
2
3
4
5
6
第一个版本的问题在于:什么叫"处理课程相关任务"?写课程、审核课程、翻译课程都算,Agent 根本无法判断该不该触发。第二个版本先说明功能(审核课程内容的技术准确性、代码正确性和教学质量),再明确触发条件(当用户要求审核、审计或评估课程时使用),Agent 可以精准匹配用户意图。
下图展示了 SKILL.md 的完整结构——YAML frontmatter 解决"要不要用",Markdown body 解决"怎么做",外部资源文件按需加载:

为什么需要外部资源文件?
Markdown body 定义了 Skill 的核心指令——工作流程、关键规则、审查标准。但有些内容放在主文件里会让它变得臃肿:10 份写作风格指南、一份 200 行的检查清单、一张过时 API 对照表……这些都是详细的参考资料,Agent 不需要一开始就全部读完。
解决办法是把它们拆成独立文件,SKILL.md 只保留链接。以 course-writer Skill 为例:
course-writer/
├── SKILL.md # 核心指令:写作流程、质量标准
└── guides/ # 外部资源:10 份详细的写作风格指南
├── 01-chapter-structure.md # 章节开篇结构
├── 02-scenario-driven.md # 场景驱动叙事
├── 05-code-examples.md # 代码示例规范
└── ...
2
3
4
5
6
7
SKILL.md 用一张表格列出每份指南的用途,Agent 写课程时根据当前阶段(比如正在写代码示例)去读取对应的 05-code-examples.md,而不是一次加载全部 10 份。这样做的好处是:SKILL.md 保持简洁易读,上下文窗口不会被参考资料撑满,而 Agent 需要细节时又随时能找到。
为什么需要本地脚本?
有些判断不应该交给模型去"猜"。比如"这段代码能不能正常运行"——模型可能会看漏一个导入语句,或者猜测某个版本的 API 仍然可用。但一个脚本可以直接执行代码,给出确定性的结果。
course-testing/
├── SKILL.md # 核心指令:审查流程、检查标准
├── CHECKLIST.md # 外部资源:审查检查项清单
└── scripts/
└── validate_code.py # 本地脚本:自动执行代码块并报告结果
2
3
4
5
Agent 执行到代码测试阶段时,直接运行 python scripts/validate_code.py,拿到"第 3 个代码块报错:ModuleNotFoundError: No module named 'sklearn'"这样精确的结果,而不是自己逐行阅读代码然后猜测能否运行。让模型做它擅长的事(理解、推理、生成),让脚本做它擅长的事(执行、验证、计算)。
# 3.3 如何写出高质量的 Skill
知道 Skill 的结构是一回事,写出真正好用的 Skill 是另一回事。一个结构完整但指令含糊的 Skill,和一个精心打磨的 Skill,效果差距巨大——前者可能让 Agent 反复犯同样的错,后者能让 Agent 稳定地交付高质量结果。
写好一个 Skill,本质上要走完五步:判断值不值得做 → 提取该写什么 → 写好指令 → 配好工具 → 验证和迭代。每一步解决一个不同的问题,跳过任何一步都会在后面埋雷。
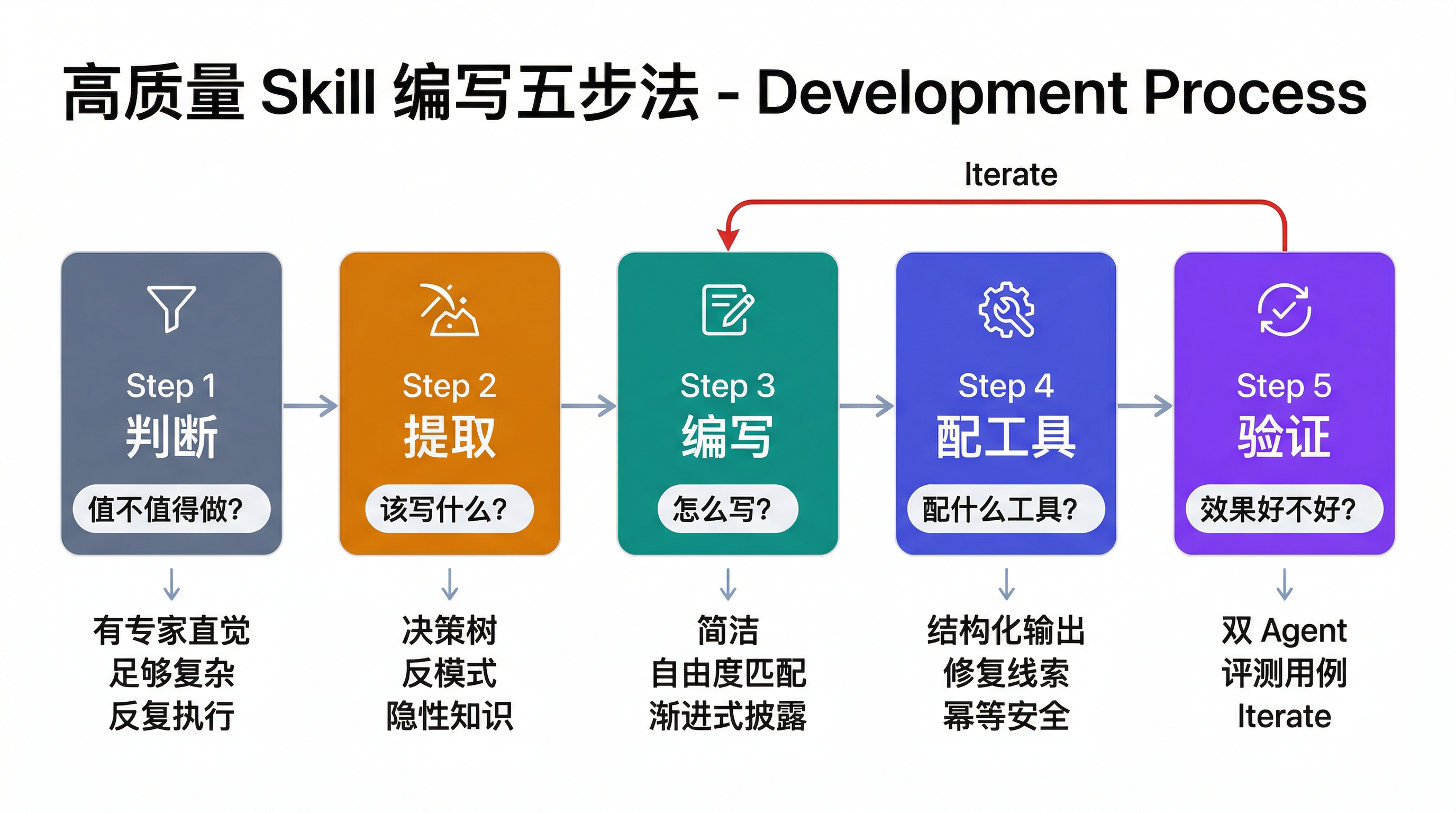
# 第一步:判断值不值得做
封装 Skill 有成本——设计结构、编写指令、测试迭代。如果任务本身很简单或只执行一次,这些成本就是浪费。在动手之前,先问自己三个问题:
这个任务有"专家直觉"吗?
"寻找那些'专家依靠直觉能做对,但新手经常漏掉边界条件'的环节。"
课程审核就是一个典型例子。资深课程设计师一眼就能看出"这个代码示例对初学者太复杂了",但新手往往意识不到。这种"隐性知识"正是 Skill 最应该捕获的内容。
这个任务足够复杂吗?
"能够在 3 步以内通过 GUI 完成的操作,严禁封装为 Skill。"
如果一个任务足够简单(比如"把这段文字翻译成英文"),直接用自然语言描述就够了,没必要大费周章地创建 Skill。为了用 AI 而用 AI,是工程实践中最常见的误区之一。
这个任务会反复执行吗?
Skill 的价值在于复用。如果一个任务只会执行一次,封装它的投入产出比就很低。但如果你的团队每周都要审核 20 门课程,那么花一天时间打磨一个 CourseReviewSkill 就非常值得。
三个问题都回答"是",才值得封装。这个判断能帮你避免最常见的浪费——不是 Skill 写得不好,而是根本不该写。
# 第二步:提取该写什么
确定要写之后,很多人会直接列操作步骤——"第一步做X,第二步做Y"。但这样的 Skill 和一段普通 Prompt 没什么区别。
真正有价值的内容是那些专家知道但很难说清楚的隐性知识。你需要做的核心工作是将它们显性化:
- 提取专家的决策树而非单纯的步骤——"在什么条件下选择方案A,什么条件下选择方案B"
- 注入反模式检查——"哪些坑绝对不能踩"
一个只告诉 Agent "做什么"的 Skill 是不完整的。一个优秀的 Skill 还会告诉 Agent "不要做什么"以及"为什么"。
提取出知识后,怎么呈现给模型?有两种高效的方式:
Template 模式:标准化输出格式
如果你的任务需要标准化的输出(审核报告、变更日志、测试总结等),直接在 Skill 中提供输出模板。模板比文字描述更精确,模型不需要"猜"你想要什么格式。
## 输出格式
按以下模板生成审查报告:
## 审查报告:{课程名称}
### 总览
- 整体质量:{1-5}/5
- 代码正确性:{通过数}/{总数} 个代码块通过
- 关键问题:发现 {数量} 个
### 关键问题
{逐条列出:}
- **[第 {n} 行]**:{问题描述}
- 严重程度:{严重|一般|轻微}
- 修复建议:{建议}
### 改进建议
1. {建议内容}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Agent 会严格按照这个模板生成输出,确保每份审核报告的结构一致、信息完整。
Examples 模式:用示例代替描述
有时候,你很难用文字精确描述你期望的风格和细节程度。这时候,一个好的 input/output 示例比一页文字描述更有效。
## 风格示例
### 输入示例
> 课程主题:Python 列表推导式
### 输出示例
> **痛点引入**:你是否曾写过这样的代码——用 5 行 for 循环只为了
> 筛选出列表中的偶数?Python 提供了一种更优雅的写法。
>
> **核心概念**:列表推导式的语法是 `[expression for item in iterable if condition]`...
>
> **对比展示**:
> ```python
> # 传统写法(4行)
> result = []
> for x in range(10):
> if x % 2 == 0:
> result.append(x)
>
> # 列表推导式(1行)
> result = [x for x in range(10) if x % 2 == 0]
> ```
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这个示例隐含了大量信息:你期望"痛点引入→核心概念→对比展示"的叙事结构、代码要有注释、要用对比来突出优势。这些如果用纯文字描述,可能需要好几段话,而且还不一定说得清楚。
两种模式可以组合使用:Template 控制结构,Examples 控制风格。
# 第三步:写好指令
有了内容,接下来是怎么写。上下文窗口是有限的公共资源——你的 Skill 要和 System Prompt、对话历史、其他 Skill 的元数据共享这个空间。写得太多,模型反而抓不住重点;写得太死,灵活的任务会被束缚;写得太长,单个文件装不下。这三个问题分别对应三条原则。
简洁:每句话都要值得它的 token 成本
在写下每一段文字之前,问自己:模型真的需要这个解释吗?我能假设模型已经知道这个吗?
看一个具体的例子——如何指导 Agent 提取 PDF 文本:
❌ 冗余版(约 150 tokens):
## 提取 PDF 文本
PDF(便携式文档格式)是一种常见的文件格式,包含文本、图片和其他内容。
要从 PDF 中提取文本,你需要使用一个库。有许多 PDF 处理库可供选择,
但我们推荐 pdfplumber,因为它易于使用且能处理大多数场景。
首先,你需要通过 pip 安装它。然后可以使用下面的代码……
2
3
4
5
6
✅ 简洁版(约 50 tokens):
## 提取 PDF 文本
使用 pdfplumber 提取文本:
2
3
4
import pdfplumber
with pdfplumber.open("file.pdf") as pdf: text = pdf.pages[0].extract_text()
简洁版假设模型已经知道 PDF 是什么、库是如何工作的。它只提供模型真正需要的信息:用什么工具、怎么调用。省下的 100 个 token,留给真正需要解释的地方。
自由度匹配:约束程度要匹配任务风险
不同的任务需要不同程度的指令精确度。一个数据库迁移脚本必须严格遵循每一步,一个代码审查则可以让 Agent 自由发挥。如果你在所有地方都用同样的约束程度,要么该严格的地方太松(出事故),要么该灵活的地方太死(限制了模型的能力)。
| 自由度 | 适用场景 | 示例 |
|---|---|---|
| 高(文本指令) | 多种方法皆可,依赖上下文判断 | 代码审查、内容分析 |
| 中(伪代码/参数化) | 存在首选模式,允许适度变化 | 报告生成、配置任务 |
| 低(精确脚本) | 操作脆弱,必须严格遵循 | 数据库迁移、部署脚本 |
把模型想象成一个探索路径的机器人。窄桥 + 悬崖(数据库迁移):只有一条安全的路,你需要提供精确的护栏(低自由度)。开阔田野(代码审查):多条路径都能到达目的地,你只需给出大致方向(高自由度)。
低自由度示例:
## 数据库迁移
严格执行以下脚本:
2
3
4
python scripts/migrate.py --verify --backup
不要修改命令或添加额外参数。
2
高自由度示例:
## 代码审查流程
1. 分析代码结构和组织方式
2. 检查潜在的 bug 和边界情况
3. 对可读性和可维护性提出改进建议
4. 验证是否符合项目规范
2
3
4
5
6
渐进式披露:主文件保持精简,详情按需加载
当 Skill 包含大量参考资料时,不要把所有内容都塞进 SKILL.md——在 1.3.1 中我们已经看到了这个原则。这里补充一个重要的实践细节:保持扁平结构,避免深层嵌套。
# ❌ 深层嵌套:SKILL.md → config.md → rules/
course-review/
├── SKILL.md → "详见 config.md"
├── config.md → "规则定义见 rules/ 目录"
└── rules/
├── code_quality.md # 模型可能根本走不到这里
└── style_guide.md
# ✅ 扁平结构:SKILL.md 直接链接所有资源
course-review/
├── SKILL.md → 直接链接下面每个文件
├── CHECKLIST.md
├── STYLE_GUIDE.md
└── scripts/
└── validate_code.py
2
3
4
5
6
7
8
9
10
11
12
13
14
15
为什么?当引用层级过深时,模型可能只用 head -100 预览中间文件而非完整读取,导致关键信息在传递链中丢失。扁平结构确保模型只需"一步"就能访问任何所需资源。
# 第四步:配好工具
1.3.2 介绍了为什么需要脚本——让模型不用"猜"。但脚本的输出质量直接决定了 Agent 能否用好它。一个输出 "Error: exit code 1" 的脚本和一个输出结构化诊断信息的脚本,对 Agent 来说是天壤之别。
先来看工作流设计,再看工具本身怎么写。
设计可追踪的工作流
复杂任务需要清晰的工作流。为 Agent 提供一个可追踪的 Checklist,能显著提高执行的可靠性。
## 课程审查工作流
复制此检查清单并跟踪你的进度:
2
3
4
审查进度:
- [ ] 步骤 1:提取所有代码块
- [ ] 步骤 2:验证每个代码块
- [ ] 步骤 3:检查技术准确性
- [ ] 步骤 4:评估难度梯度
- [ ] 步骤 5:验证风格合规性
- [ ] 步骤 6:生成审查报告
**步骤 1:提取所有代码块**
扫描课程文档并提取每个代码块...
**步骤 2:验证每个代码块**
运行每个代码块。如果验证失败:
- 记录错误信息
- 标记为"需要修复"
- 继续下一个代码块
2
3
4
5
6
7
8
9
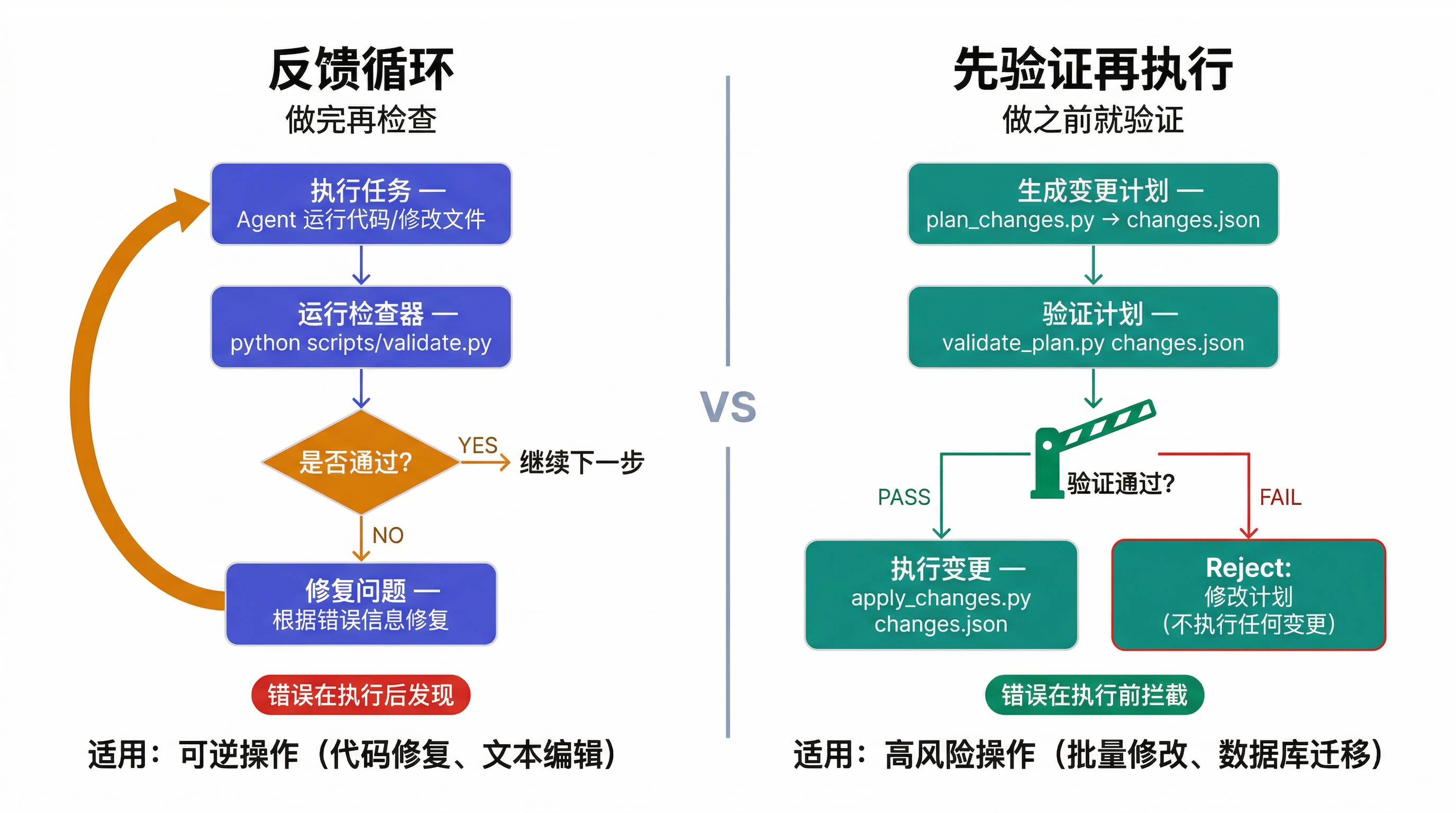
反馈循环模式
对于需要验证的任务,建立"运行 → 检查 → 修复 → 重复"的反馈循环:
## 验证循环
1. 运行验证器:`python scripts/validate.py`
2. 如果发现错误:
- 查看错误信息
- 修复问题
- 再次运行验证器
3. 只有在验证通过后才继续
2
3
4
5
6
7
8
这种模式给 Agent 提供了自我纠正的机会,而不是一次做完就结束。
高风险操作:先验证计划再执行
反馈循环是"做完再检查",但对于高风险操作(批量修改文件、数据库迁移等),你可能希望 Agent 在执行之前就验证计划。
## 批量更新工作流
在进行任何更改之前:
1. 生成 JSON 格式的更改计划:
2
3
4
5
python scripts/plan_changes.py --output changes.json
2. 验证计划:
python scripts/validate_plan.py changes.json
- 验证没有文件将被删除
- 验证所有目标路径都存在
- 验证更改是可逆的
3. 只有在验证通过后,才执行:
2
3
4
python scripts/apply_changes.py changes.json
与反馈循环的核心区别:错误在执行前就被拦截,而不是执行后才发现。
编写 AI 友好的脚本
工作流设计好了,脚本本身怎么写?核心理念:不要把问题踢给模型。当工具返回模糊的错误信息时,模型只能猜测原因;当工具返回结构化的诊断结果时,模型可以精准地决定下一步。四个关键原则:
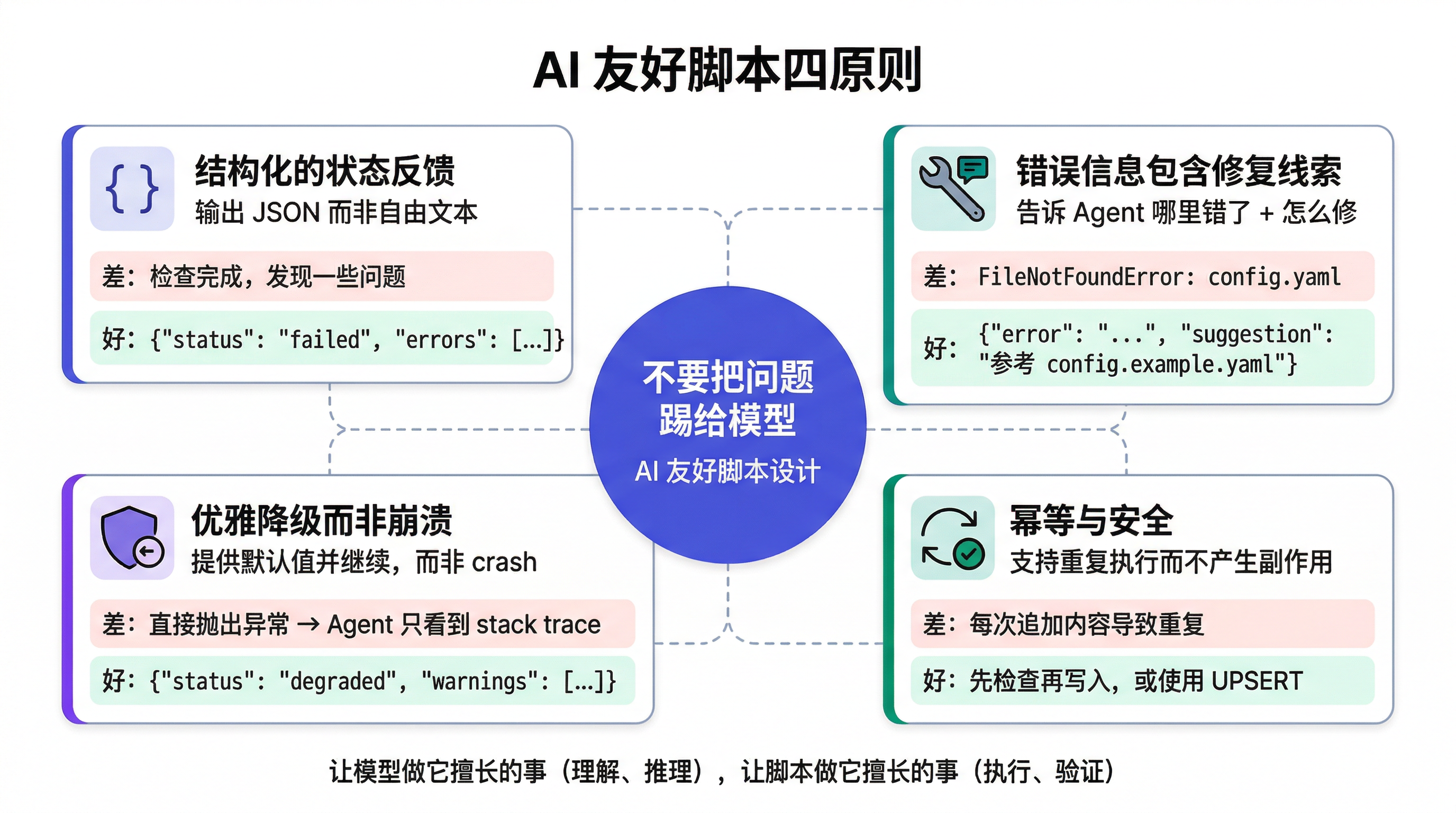
结构化的状态反馈——输出 JSON 而非自由文本。Agent 收到 "status": "failed" 能立即进入修复流程;收到 "检查完成,发现一些问题" 还需要先理解这句话的含义。
错误信息包含修复线索——Agent 不需要 stack trace,它需要"哪里错了 + 怎么修"。
| 做法 | 示例 |
|---|---|
| 差 | FileNotFoundError: No such file or directory: 'config.yaml' |
| 好 | {"error": "CONFIG_NOT_FOUND", "file": "config.yaml", "suggestion": "请在项目根目录创建 config.yaml,可参考 config.example.yaml", "fallback_used": true} |
差的版本只告诉 Agent "出错了";好的版本告诉 Agent "出了什么错、怎么修、当前是否有降级方案"。
优雅降级而非崩溃——工具应在可能的情况下提供默认值并继续,而不是直接 crash。Agent 收到一个 crash 后只能猜测原因;收到一个降级通知后能精准决策。
# 差:直接崩溃
def load_config(path):
with open(path) as f: # FileNotFoundError → Agent 只看到 stack trace
return json.load(f)
# 好:优雅降级,返回结构化状态
def load_config(path):
result = {"status": "ok", "warnings": []}
if not os.path.exists(path):
result["status"] = "degraded"
result["warnings"].append(f"Config '{path}' not found, using defaults")
return {**result, "config": DEFAULT_CONFIG}
# ...正常加载逻辑
2
3
4
5
6
7
8
9
10
11
12
13
幂等与安全——Agent 可能多次调用同一工具(尤其在反馈循环中)。工具应支持重复执行而不产生副作用。
| 场景 | 非幂等(危险) | 幂等(安全) |
|---|---|---|
| 文件写入 | 每次调用追加内容,导致重复 | 先清空再写入,或写入前检查 |
| 数据库操作 | 每次 INSERT 新记录 | 使用 UPSERT 或先检查是否已存在 |
| API 调用 | 每次创建新资源 | 使用幂等键,确保重复请求只生效一次 |
把这四个原则综合起来,看一个完整对比——以 validate_code.py 为例:
# ❌ 普通版:面向人类的输出
def validate(file_path):
errors = run_checks(file_path)
if errors:
print(f"发现 {len(errors)} 个问题:")
for e in errors:
print(f" - 第 {e['line']} 行:{e['message']}")
sys.exit(1)
print("✅ 全部通过!")
2
3
4
5
6
7
8
9
# ✅ AI 友好版:结构化输出 + 修复线索 + 优雅降级
def validate(file_path):
result = {
"status": "passed",
"file": file_path,
"errors": [],
"warnings": [],
"summary": ""
}
if not os.path.exists(file_path):
result["status"] = "error"
result["summary"] = f"未找到文件 '{file_path}'"
result["suggestion"] = "请检查文件路径并重试"
print(json.dumps(result, ensure_ascii=False))
return
errors = run_checks(file_path)
if errors:
result["status"] = "failed"
result["errors"] = [
{
"line": e["line"],
"rule": e["rule"],
"message": e["message"],
"fix_hint": e.get("fix_hint", "")
}
for e in errors
]
result["summary"] = f"{len(errors)} issues found, {sum(1 for e in errors if e.get('fix_hint'))} auto-fixable"
else:
result["summary"] = "All checks passed"
print(json.dumps(result, ensure_ascii=False))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
当 Skill 的反馈循环调用 AI 友好版的工具时,Agent 可以直接解析 JSON、按 fix_hint 逐个修复问题,然后再次运行验证——整个过程无需人类介入。
# 第五步:验证和迭代
Skill 写完了,怎么知道它好不好?靠自己读一遍是不够的——你觉得写得清楚,模型可能理解完全不同。最有效的方式是与 AI 协作开发。
“双 Agent”模式
- Agent A(设计者):帮你设计和精炼 Skill 的指令
- Agent B(使用者):在真实任务中测试 Skill
开发流程分三个阶段:
阶段一:建立评测基线。 先用 Agent A 完成一次真实任务(不用任何 Skill)。记录它在哪些地方犯了错、哪些地方需要你反复纠正,挑出 3 个最典型的失败场景作为评测用例。先有评测,再写 Skill——否则后续优化全靠“感觉”。
阶段二:提取 Skill。 任务完成后,让 Agent A 帮你总结:“哪些信息是你反复提供的?” 将这些信息整理成 Skill 的初稿。
阶段三:测试迭代。 让 Agent B(一个全新的会话)加载这个 Skill,执行阶段一中的评测用例。对比输出:改进了哪些?还有哪些没解决?把观察带回 Agent A 改进 Skill,重复测试,直到 Agent B 能稳定通过所有评测用例。
这种“评测-改进-验证”循环是打磨 Skill 最有效的方式。评测用例贯穿整个开发过程,为每一轮迭代提供客观的衡量标准。这一理念在第 3.6 课“用评测驱动Agent开发”中会有更系统的展开。
# 4 让你的 Agent 使用和生成 Skill
到目前为止,你手动完成了 Skill 从设计到迭代的全过程:用 1.2 节的审查经验提炼出检查清单,在 1.3 节中将其封装成 course-review/ 目录结构,又通过“双 Agent”模式反复打磨指令。但这个 Skill 还只是躺在文件系统里的一组 Markdown 文件——Agent 怎么发现它、加载它、在真实任务中调用它?
# 4.1 在 AgentScope 中加载 Skill
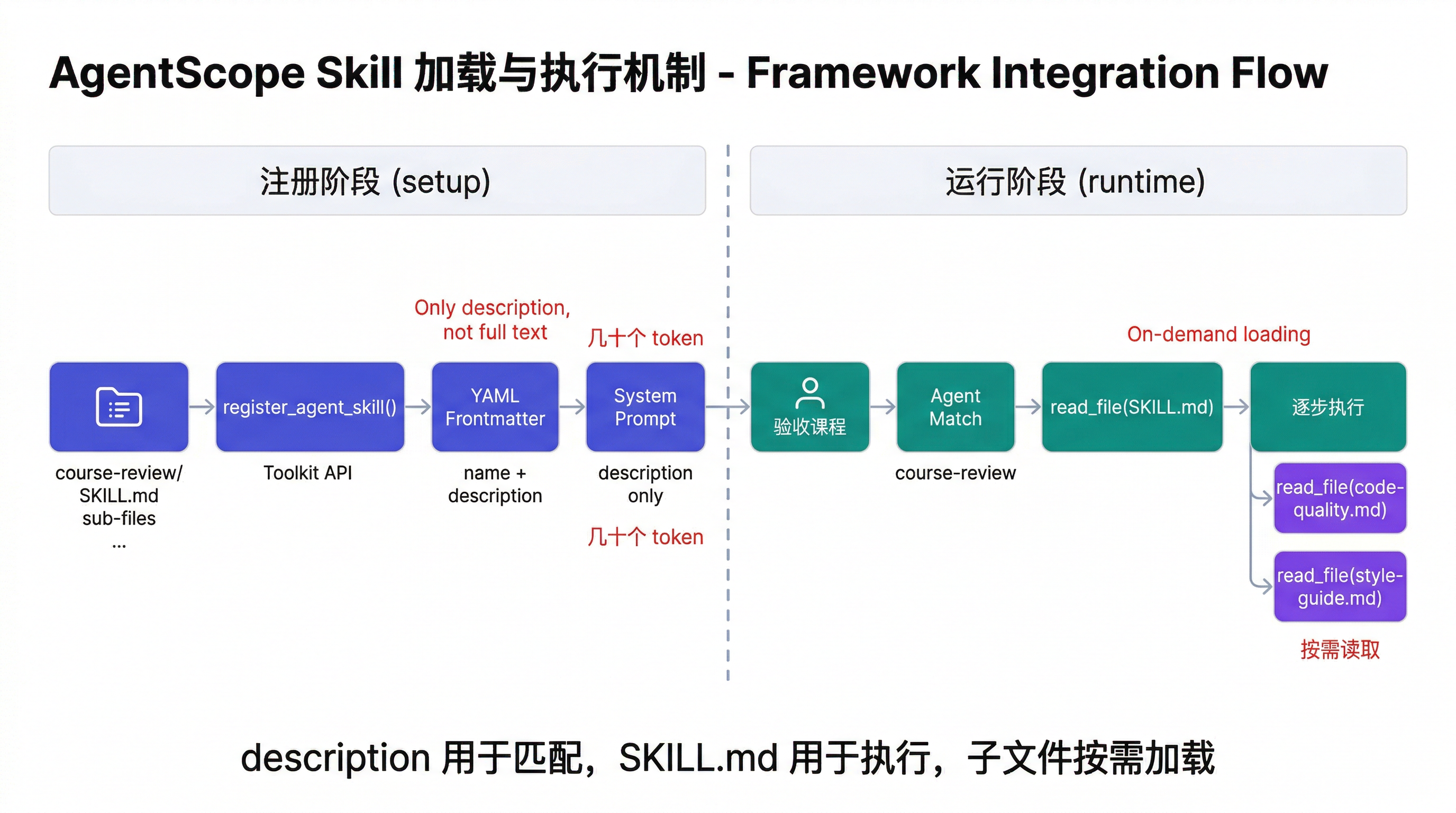
好消息是,你不需要自己写加载逻辑。AgentScope 框架已经内置了对 Skill 目录结构的支持——它的 Toolkit 类除了注册普通工具函数外,还提供了 register_agent_skill 方法,可以直接读取一个 Skill 目录(包含 SKILL.md 和相关资源文件),自动解析元数据并生成 Agent 可用的提示。
在注册之前,需要先完成一项准备工作:register_agent_skill 要求入口文件名为 SKILL.md(而非 1.2.2 中创建的 README.md),并且文件顶部必须包含 YAML frontmatter——框架正是从中提取 name 和 description 来生成 Agent 可见的 Skill 提示。
下面的脚本将 1.2.2 的 README.md 升级为符合规范的 SKILL.md:在原有内容前添加 YAML frontmatter,然后重命名文件。
import os
# 读取 1.2.2 创建的 README.md
with open("course-review/README.md", "r", encoding="utf-8") as f:
original_content = f.read()
# 添加 YAML frontmatter
frontmatter = """\
---
name: course-review
description: |
审查课程内容的技术准确性、代码正确性和教学质量。
当用户要求审查、审计或评估现有的课程或培训材料时使用此技能。
---
"""
with open("course-review/SKILL.md", "w", encoding="utf-8") as f:
f.write(frontmatter + original_content)
# 删除旧的入口文件
os.remove("course-review/README.md")
print("已将 README.md 升级为 SKILL.md(含 YAML frontmatter)")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
第一步:注册 Skill 并查看生成的 Prompt
from agentscope.tool import Toolkit
# 1. 注册工具函数(复用 1.1 节定义的 read_file)
toolkit = Toolkit()
toolkit.register_tool_function(read_file)
# 2. 注册 Skill:传入包含 SKILL.md 的目录路径
toolkit.register_agent_skill("course-review")
# 3. 查看框架为 Agent 生成的 Skill 提示
print(toolkit.get_agent_skill_prompt())
2
3
4
5
6
7
8
9
10
11
框架自动读取了 SKILL.md 的 YAML frontmatter,提取 name 和 description,生成了一段精炼的提示。提示告诉 Agent "这里有一个 Skill,要用的时候去读 SKILL.md"——而不是把整个文件内容塞进 system prompt。
第二步:集成到 ReActAgent 并执行审查
1.2.3 中已经用 jupytext 将 Notebook 转为了 Markdown 格式。.md 文件去掉了 JSON 元数据和单元格输出,体积远小于 .ipynb,Agent 读取更快、消耗的 token 也更少。这里直接审查转换后的 .md 文件:
from agentscope.agent import ReActAgent
from agentscope.formatter import DashScopeChatFormatter
from agentscope.memory import InMemoryMemory
from agentscope.message import Msg
from agentscope.model import DashScopeChatModel
reviewer = ReActAgent(
name="CourseReviewer",
sys_prompt="你是一个课程质量审核员。",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit, # Skill 提示会自动附加到 system prompt
memory=InMemoryMemory(),
max_iters=12,
)
reviewer.set_console_output_enabled(False)
# 审查转换后的 Markdown 文件,体积更小、响应更快
response = await reviewer(Msg("user", "审查 docs/Python数据分析实战.md", "user"))
print(response.get_text_content())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这次 Agent 不会再给出"整体不错,建议发布"的敷衍结论。它会先通过 read_file 读取 SKILL.md 获取工作流程框架,然后按步骤逐项执行——检查代码时读取 code-quality.md,核对准确性时读取 content-accuracy.md,校对风格时读取 style-guide.md,最后按输出格式模板生成结构化报告。
三个设计决策
为什么只注入 description 而非全文? 上下文窗口是公共资源。框架只把
description(几十个 token)注入 system prompt,告诉 Agent 这个 Skill 的存在和用途。完整的工作流程、反模式清单等内容,由 Agent 在决定使用 Skill 时通过read_file按需加载。为什么 Agent 需要文件读取工具? 这是 Skill 机制的核心:Agent 先从
description判断是否需要这个 Skill,再读取SKILL.md获取详细指令,需要更细节时再读取子文件(如style-guide.md)。这就是渐进式披露在框架层的落地。
description字段的质量为什么关键? 当 Agent 装备了多个 Skill 时,它根据description判断当前任务应该使用哪个 Skill。模糊的描述(如"处理课程相关任务")会导致匹配失败;具体的描述(说明做什么、什么时候触发)才能确保正确激活。
📚 扩展阅读:AgentScope 的 Skill 机制完整文档参见 Task Agent Skill (opens new window),其中包含更多注册方式和高级用法。
# 4.2 让 Agent 自动生成 Skill
手动编写 Skill 是必要的学习过程,但熟练之后,可以让 Agent 辅助完成初稿。resources/2_6/skill-creator/ 目录下提供了一个 skill-creator Skill,它基于开源版本裁剪而成。原版面向完整的 Coding Agent 工作流,我们保留了核心的编写指导——意图捕获、需求调研、SKILL.md 编写规范、渐进式披露——移除了 CLI 工具链等环境依赖。
加载 skill-creator 并生成新 Skill
from agentscope.tool import Toolkit, ToolResponse
from agentscope.message import TextBlock
# 定义写文件工具(与 1.1 的 read_file 对称)
async def write_file(path: str, content: str) -> ToolResponse:
"""将内容写入指定路径的文件。如果目录不存在则自动创建。"""
import os
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
return ToolResponse(content=[TextBlock(type="text", text=f"已写入 {path}")])
# 1. 注册工具和 Skill
# read_file 让 Agent 能读取 SKILL.md 获取创建指南
# write_file 让 Agent 能将生成的 Skill 写入文件
toolkit = Toolkit()
toolkit.register_tool_function(read_file)
toolkit.register_tool_function(write_file)
toolkit.register_agent_skill("resources/2_6/skill-creator")
# 2. 创建 Skill 生成 Agent
creator = ReActAgent(
name="SkillCreator",
sys_prompt="你是一个 Agent Skill 设计师。",
model=DashScopeChatModel(
model_name="qwen-plus",
api_key=os.environ.get("DASHSCOPE_API_KEY"),
),
formatter=DashScopeChatFormatter(),
toolkit=toolkit,
memory=InMemoryMemory(),
max_iters=12,
)
# 3. 用自然语言描述需求,Agent 自动生成 Skill
creator.set_console_output_enabled(False)
response = await creator(Msg(
"user",
"帮我创建一个审核 REST API 文档的 Skill。"
"要检查:1. 所有端点是否有示例请求和响应;"
"2. 错误码是否有说明;3. 参数是否有类型标注。",
"user",
))
print(response.get_text_content())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
Agent 会生成一个完整的 api-doc-review/ 目录,包含符合标准结构的 SKILL.md 和检查清单。
不过,这是加速而非替代。你仍然需要理解 1.3 节的设计原则,才能判断 Agent 生成的内容是否合理。专家用 skill-creator 可以快速产出高质量 Skill,而不理解设计原则的新手,即使有 skill-creator 也很难产出可用的结果。
💡 小贴士:生成的 Skill 初稿一定要配合 1.3.5 的"双 Agent"评测流程验证。自动生成只解决了"写出来"的问题,"写得对不对"仍然需要评测驱动的迭代。
# 4.3 Skill 市场:复用社区的专家知识
前两节介绍了在 AgentScope 中注册和生成自建 Skill 的方法。在更广泛的 Coding Agent 生态中,社区已经形成了成熟的 Skill 共享平台。
发现 Skill
假设你正在开发一个 TypeScript 项目,想找找有没有现成的代码规范 Skill。skills find 命令支持按关键词搜索:
# 按关键词搜索
npx skills find typescript
# 输出示例:
# Install with npx skills add <owner/repo@skill>
#
# vercel-labs/agent-skills@typescript-best-practices
# https://github.com/vercel-labs/agent-skills/tree/main/skills/typescript-best-practices
#
# acme/skills@typescript-linter
# https://github.com/acme/skills/tree/main/typescript-linter
2
3
4
5
6
7
8
9
10
11
不带参数运行 npx skills find 会进入交互式模糊搜索界面,适合你还不确定关键词的探索场景。找到感兴趣的 Skill 后,点击链接可以在相关平台上查看完整内容和安全审计评级。
安装和使用
# 安装特定 Skill
npx skills add vercel-labs/agent-skills --skill vercel-react-best-practices
# 更新所有已安装的 Skill
npx skills update
2
3
4
5
安装后,Skill 文件会下载到项目目录中。Coding Agent(如 Cursor 等)会自动读取并遵循其中的指导。每个 Skill 本质上就是一组 Markdown 文件,与你在 1.3 节学到的结构完全一致。安装前务必在相关平台详情页查看安全审计评级——虽然 Skill 只是 Markdown 文件,但其中的指令会直接影响 Agent 的行为。
社区 Skill 与自建 Skill 的分工
| 场景 | 推荐方式 |
|---|---|
| 通用技术最佳实践(React 性能优化、代码规范) | 社区 Skill |
| 成熟的行业标准流程(安全审计、SEO 优化) | 社区 Skill |
| 企业内部业务流程和质量标准 | 自建 Skill |
| 团队特有的代码规范和架构约定 | 自建 Skill |
| 领域专家的隐性知识(如本章的课程审核 Skill) | 自建 Skill |
两者并不互斥:社区 Skill 覆盖通用技术能力,自建 Skill 封装业务特有的专家知识,组合使用效果最好。
使用时的注意事项
- 避免 Skill 过多:安装了过多 Skill 会撑满 system prompt,反而稀释核心指令的注意力权重
- 注意版本匹配:Skill 依赖的工具或框架更新后,Skill 中的命令和路径可能已过时
- 合理预期:Skill 提升的是下限(让 Agent 不犯低级错误),而不是上限(让 Agent 产出超越专家水平的成果)
# 4.4 本节回顾
本节围绕 Skill 的"用起来"展开了三个层次:
- 注册与加载(1.4.1):AgentScope 的
register_agent_skill方法将 Skill 目录转化为 Agent 可用的提示,框架只注入description而非全文,由 Agent 按需读取详细指令——这是渐进式披露在框架层的落地。 - 自动生成(1.4.2):借助
skill-creator这个"元 Skill",Agent 可以根据自然语言需求生成 Skill 初稿,但生成结果仍需通过评测流程验证。 - 社区复用(1.4.3):相关平台提供了现成的通用 Skill,与自建 Skill 形成互补——社区覆盖通用能力,自建封装业务知识。
# 5 当 Skill 遇上团队
# 5.1 一个人的成功,十个人的混乱
你在 1.4 中成功构建了 CourseReviewSkill,它帮你把课程审核时间从 2 小时缩短到 20 分钟。主管很满意,让你把这个 Skill 推广给整个教学设计团队——10 个人。你把 SKILL.md 文件发到群里,附了一段简短的使用说明。
一个月后,问题接踵而至。
版本混乱:你根据最新的课程标准更新了评分权重,但有 3 位同事还在用旧版 Skill。同一门课程被审出矛盾的结论——你的报告说"结构合理",同事的报告说"章节划分不当"。团队不得不花半天时间排查,才发现是 Skill 版本不一致。
误修改:实习生觉得 SKILL.md 中"避免使用 print() 进行调试"这条规则太严格,自行改成了"允许在开发阶段使用 print()"。结果 Agent 开始把所有 print() 调试代码标记为"符合规范",三周后才被发现。
知识断档:你休假两周,团队遇到 3 个审核边界问题——"代码示例中的注释算不算教学内容?""引用外部 API 文档需不需要检查链接有效性?"——没人能回答,因为这些判断逻辑只存在于你的经验中,没有写进 Skill。
这三个问题有一个共同点:CourseReviewSkill 作为一个人的作品运转良好,但它没有为团队协作而设计。
# 5.2 朴素修补:为什么"群里发一下"行不通
面对这些问题,你可能会想到几个直觉性的修补方案。
统一存放位置。把 Skill 文件放到共享网盘,大家都从同一个地方拿。但问题随之而来:谁有权修改这个文件?如果 10 个人都能改,就等于没人负责——任何人的一次"顺手改改"都可能影响整个团队的审核结果。
发一份使用说明文档。写一个详细的操作指南,说明 Skill 的使用方法和注意事项。但文档和 Skill 是分离的,两周后 Skill 迭代了,文档还停留在旧版本。文档越详细,过时得越快。
由你一个人负责所有修改。任何改动都必须经过你。这确实能保证质量,但你成了瓶颈——团队的 10 个需求排队等你处理,而且你不是所有审核领域的专家,有些改进你没有能力做出正确判断。
这些修补方案失败的根本原因在于:Skill 不是一个普通的配置文件,而是封装了专家知识的可执行资产。它直接决定 Agent 的行为和产出质量。管理这类资产,需要明确的所有权和工程化的生命周期——这正是软件工程几十年来解决类似问题的方式。
换一个角度看,Skill 的真正价值是作为能力放大器:一位资深课程设计师每周只能审核 10 门课程,但她把审核经验封装成 Skill 后,团队里的 10 个初级成员都能调用——她的专业能力被规模化复制了。但要让这个放大器在团队中稳定运转,需要解决所有权、协作流程和质量保障三个问题。

# 5.3 领域团队所有权:让最懂业务的人管 Skill
谁最有能力定义和维护 CourseReviewSkill 的审核标准?不是 IT 部门,不是某一个人,而是教学设计团队——他们最了解"什么样的课程才算好",也最有能力判断审核标准是否需要更新。
这就是领域团队所有权的核心思想:最有度量能力的团队,拥有并维护该领域的 Skill。
新的分工模式
| 角色 | 职责 |
|---|---|
| 专家 (Expert) | 定义标准、封装 Skill、审核变更 |
| 团队成员 (Member) | 调用 Skill、反馈问题、提交改进建议 |
这种分工的价值不在于"谁写谁用"的简单分配,而在于规模化复制:专家的时间有限,但 Skill 可以被无限次调用。专家从"亲自执行每一次审核"转变为"维护审核标准",其影响力从线性增长变为指数增长。
在实际组织中,不同领域的 Skill 应由对应的业务团队负责:
| 领域 | 所有权团队 | 维护的 Skill 示例 |
|---|---|---|
| 课程质量 | 教学设计团队 | CourseReviewSkill、LearningObjectiveSkill |
| 数据分析 | 数据团队 | DataCleaningSkill、ABTestAnalysisSkill |
| 安全合规 | 安全团队 | CodeSecurityScanSkill、ComplianceCheckSkill |
"最有度量能力"意味着这个团队不仅了解业务规则,还能设计评测方案来验证 Skill 的产出质量。教学设计团队能判断一份审核报告是否到位,数据团队能判断一次清洗是否遗漏了异常值——这种判断力是 Skill 持续改进的基础。
编写高质量 Skill 通常需要业务专家和技术人员的协作:
| 角色 | 职责 |
|---|---|
| 业务专家 (SOP Owner) | 制定流程标准与边界条件 |
| 技术人员 (Agent Architect) | Prompt 结构调优与工具挂载 |
协作流程分三步:
- 业务专家用自然语言描述"一个优秀的审核员会怎么做"
- 技术人员将其转化为结构化的 Skill 格式
- 双方一起测试、迭代、根据 Agent 实际产出调整指令
为了在 Skill 文件中明确所有权信息,可以在 YAML frontmatter 中添加管理元数据:
---
name: course-review
description:
审核课程内容的质量和结构完整性。
当用户要求检查、审核或评估课程材料时触发。
owner: 教学设计团队
maintainers:
- zhang-wei # 课程质量负责人
- li-na # 资深教学设计师
version: 2.1.0
last-reviewed: 2026-01-15
---
2
3
4
5
6
7
8
9
10
11
12
这些字段让任何人打开文件就能知道:有问题找谁、当前是什么版本、上次审查是什么时候。
小贴士:如果你的团队使用 GitHub 管理 Skill 仓库,可以配置
CODEOWNERS文件来自动化审核权限。例如,在.github/CODEOWNERS中添加/skills/course-review/ @teaching-design-team,这样任何对该 Skill 的修改都会自动要求教学设计团队成员审批,从制度上防止未经授权的变更。
# 5.4 Skills-as-Code:用工程方法管理 Skill 资产
所有权明确后,下一个问题是:团队如何协作迭代 Skill?答案是把 Skill 当作代码来管理——version control、code review、CI/CD,这些软件工程的成熟实践同样适用于 Skill。
Skills-as-Code 生命周期
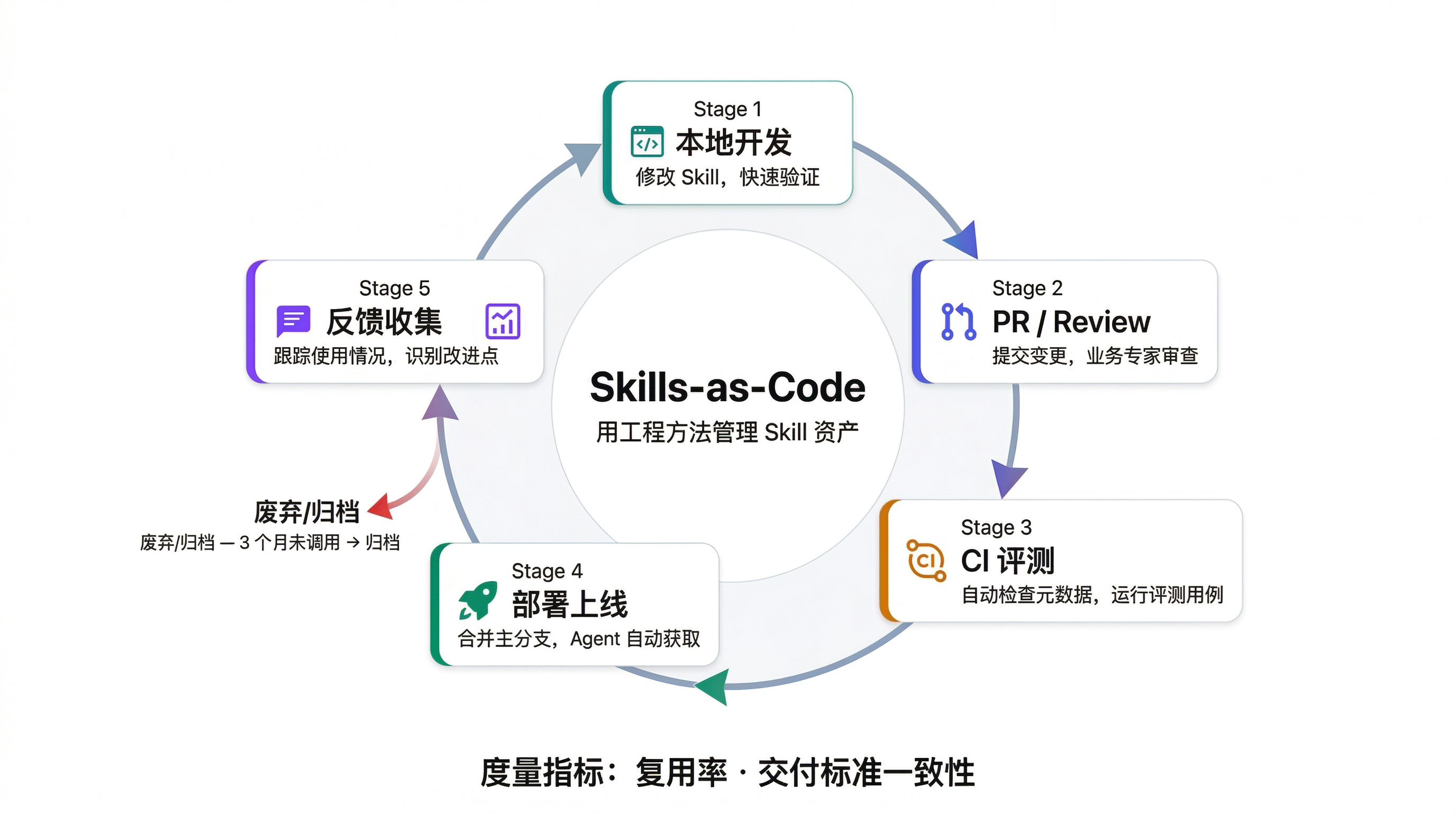
- 本地迭代:维护者在本地修改 Skill,用几个代表性案例快速验证效果
- PR / Review:提交 Pull Request,由团队其他成员(尤其是业务专家)审查变更
- CI 评测:自动化流水线运行评测用例,确保修改没有引入回归问题
- 部署上线:合并到主分支后,所有使用该 Skill 的 Agent 自动获取最新版本
- 反馈收集:跟踪线上使用情况,收集用户反馈,识别需要改进的地方
下面是一个 GitHub Actions 配置示例,用于在 PR 阶段自动检查 Skill 的元数据完整性并运行评测用例:
# .github/workflows/skill-review.yml
name: Skill Review
on:
pull_request:
paths:
- 'skills/**/SKILL.md'
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Check SKILL.md metadata
run: |
for skill_file in $(git diff --name-only origin/main | grep 'SKILL.md'); do
echo "Checking $skill_file..."
# 验证必需的 frontmatter 字段
for field in name description owner version last-reviewed; do
if ! grep -q "^${field}:" "$skill_file"; then
echo "ERROR: Missing required field '${field}' in $skill_file"
exit 1
fi
done
done
- name: Run skill evaluation
run: |
# 运行评测用例(详见第 3.6 课“用评测驱动Agent开发”)
python scripts/evaluate_skill.py --changed-only
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这个流水线做两件事:检查每个被修改的 SKILL.md 是否包含必需的管理字段(name、description、owner、version、last-reviewed),然后运行评测脚本验证 Skill 的实际效果。
废弃与清理
Skill 不是写完就永远有效的。建议每季度审查一次,按以下标准决定处置方式:
- 过去 3 个月未被调用 → 考虑归档
- 对应的业务流程已取消 → 立即删除
- 与其他 Skill 功能重叠 → 合并精简
核心度量指标
| 指标 | 定义 | 意义 |
|---|---|---|
| 复用率 | Skill 被不同团队成员调用的频次 | 只有被反复调用的 Skill 才是有效资产 |
| 交付标准一致性 | 新手使用 Skill 后的产出质量 vs 专家基线 | 衡量 Skill 是否真正传递了专家能力 |
这两个指标帮助你判断一个 Skill 是否值得继续投入维护。如果复用率低,说明这个 Skill 解决的不是高频问题;如果交付标准一致性低,说明 Skill 的指令还不够清晰,需要继续迭代。
扩展阅读:你可能注意到,上面的 CI 流水线中包含"运行评测用例"这一步。如何为 Agent 这种概率性输出建立可靠的评测体系?这正是第 3.6 课“用评测驱动Agent开发”的主题。Skill 的质量保障与评测驱动开发密不可分——没有评测,你无法判断一次 Skill 修改是改进还是回归。
# 5.5 落地路径:从种子团队到全面推广
理解了所有权和工程化管理之后,最后一个问题是:如何在组织中实际推进?直接全员铺开几乎必然失败。推荐采用"种子 Skill"策略:
- 选一个 3-5 人的先锋队:找到对 AI 工具有兴趣、有一定技术基础的种子成员
- 聚焦一个高价值痛点:比如 Code Review、课程审核、数据清洗——选团队最痛的那个
- 跑通完整闭环:从"识别专家知识 → 封装 Skill → 评测验证 → 团队试用"走完一轮
- 用结果说服其余团队:拿出具体数据(审核时间缩短 X%、产出质量达到专家水平的 Y%)
随着 Skill 数量和使用范围扩大,治理机制也需要相应演进:
| 维度 | 试点期 | 推广期 |
|---|---|---|
| 谁写 | 技术骨干 + 业务专家 | 任何团队成员可提交 |
| 谁审 | 同行 Code Review | 专门的 Skill 审核组 |
| 谁批准 | 团队负责人 | 领域知识工程师 |
试点期的重点是验证模式可行、积累最佳实践;推广期的重点是降低参与门槛、建立标准化流程。从试点到推广的标志是:种子团队能用数据证明 Skill 带来了可量化的价值提升。
引入 Skill 的初期(通常 1-3 个月),整体效率可能不升反降。这是正常的——学习 Skill 编写规范、调试 Agent 行为、建立评测体系都需要时间。关键是让管理层对此有预期,用试点期的数据建立信心,而不是在第一个月就下结论。
最后,关于责任归属:当 Agent 调用 Skill 产出代码或文档时,谁负责?Merge 即负责——点下合并按钮的人,对产出承担最终责任。这条规则清晰、可执行,避免了"AI 做的,不关我事"的推诿。
# 5.6 本节回顾
- 推广困境:个人构建的 Skill 在团队中使用时,会遇到版本混乱、误修改和知识断档三类问题
- 能力放大器:Skill 的核心价值是将专家能力规模化复制,但需要所有权和工程化流程来保障
- 领域团队所有权:最有度量能力的团队拥有并维护对应领域的 Skill,通过 YAML 元数据和 CODEOWNERS 明确权责
- Skills-as-Code:将 Skill 当作代码管理,走 PR → Review → CI 评测 → 部署的完整工程生命周期
- 落地策略:从种子团队开始,聚焦高价值痛点,用数据说话,逐步推广到全组织
# 6 总结
我们从一次教程审查任务出发,逐步引出了 Agent 上下文管理的核心方法——从发现问题,到理解原因,到用 Skill 解决,再到在团队中规模化落地:
- 教程审查中的痛点(1.1):自主 Agent 能开始工作,但使用通用标准审查时,会遗漏团队特有的专业要求;而将专业标准写进 Prompt 后,又面临散落在聊天记录中、无法复用和共享的问题。
- 把审查经验沉淀下来(1.2):通过文件化→目录化→分段检查→按需加载四步,将一次性 Prompt 改造为可复用、可维护的知识库目录。主文件保持精简,详细内容拆分到子文件,按需加载避免上下文拥挤。
- Agent Skills(1.3):Skill 是预先精炼的高信噪比上下文,将 SOP、专用工具、专家经验打包成可复用模块。SKILL.md 由 YAML frontmatter(
name+description)和 Markdown body 组成,遵循简洁、自由度匹配、渐进式披露和反馈循环四条编写原则。通过"双 Agent"评测模式(设计者 + 使用者)迭代打磨 Skill 质量。 - 框架集成与生态(1.4):AgentScope 的
register_agent_skill实现 Skill 注册和按需加载;skill-creator元 Skill 可以自动生成初稿(但仍需人工审查);相关平台提供社区 Skill 的搜索(npx skills find)和安装,与自建 Skill 互补使用。 - 团队协作(1.5):个人 Skill 推广到团队时会遇到版本混乱、误修改和知识断档问题。解决方案是领域团队所有权(最懂业务的团队管 Skill)和 Skills-as-Code(用 PR、Review、CI 评测管理 Skill 生命周期)。从种子团队开始,聚焦高价值痛点,用数据驱动推广。
# 🔥 课后小测验
# 🔍 单选题 3.5.1
你的课程审查Agent总是遗漏"代码示例必须有注释"这一团队规范。你已经在多次对话中反复提醒它,但每开一个新会话又会忘记。最有效的解决方式是什么❓ - A. 将"代码必须有注释"写入Agent的长期记忆,让它在每次审查前自动检索该条经验
- B. 编写一个包含完整审查检查清单的Skill文件,让Agent在执行审查任务时加载该Skill
- C. 在每次新建对话时手动将这条要求粘贴到第一条消息中作为提示
- D. 提高模型的temperature参数,让Agent在审查时考虑更多可能性从而覆盖该规范
【点击查看答案】
✅ 参考答案:B 📝 解析: A方向对但层次不够——Memory适合记录偏好和经验片段(如"上次API报错是因为版本不对"),但一条零散的记忆缺乏执行上下文,Agent知道"要检查注释"却未必知道完整的检查流程。C是人工重复劳动,无法规模化。D与问题无关,temperature影响输出多样性而非检查覆盖面。B是正解:Skill将完整的审查SOP(包括所有检查项、检查顺序、判定标准)封装为可复用模块,Agent加载后获得系统化的工作指令,而非零散的记忆提示。
# ✉️ 评价反馈
欢迎你参与阿里云大模型ACP课程问卷 (opens new window) 反馈学习体验和课程评价。 你的批评和鼓励都是我们前进的动力!