
 部署模型
部署模型
# 4.2 部署模型
# 🚄 前言
在经过模型微调和评测后,答疑机器人的开发工作已经接近完成。本节课程将继续学习如何在计算资源上部署模型,使其成为一个可访问的应用服务。 同时还会进一步介绍在云上部署模型的常见方法,并帮助你根据自身的需求选择最合适的方式部署模型。
# 🍁 课程目标
学完本节课程后,你将能够:
- 了解如何手动部署一个模型
- 了解在云上部署模型的常见方式
- 基于自身的需求选择最合适的方式部署模型
# 1. 直接调用模型(无需部署)
部署模型是将训练好的AI模型从开发环境转移到生产环境的过程,使其能够处理实时数据并为实际应用提供服务,从而服务于真实用户,创造价值。
回顾 2.1 至 2.6 节的课程中,你已经多次调用过模型(如:qwen3-235b-a22b-thinking-2507,qwen-plus等),但并没有对模型进行部署。这是因为你所调用的模型都是阿里云的预置模型,它们已经部署在阿里云服务器上,可以直接通过 API 进行调用。
这种直接调用服务提供商(如阿里云)完全托管的API服务有几点好处:
- 直接调用:无需部署模型,只需简单地调用API即可。
- 按需计费:按token量计费,无需担心模型部署的资源消耗。
- 无需运维:你无需担心模型的部署和运维,如自动扩缩容、模型版本升级等,这部分工作均由模型服务提供商完成。
这种方式很适合业务初期或中小规模场景,可以有效降低业务初期投入成本,并避免闲置GPU资源的浪费。
需要注意的是:直接调用模型一般会被“限流 (opens new window)”,例如通过百炼API调用时,每分钟的调用次数(QPM)和消耗的Token数(TPM)均有限制。超出限制将导致请求失败,需等待限流条件解除后才能再次调用。”
同时,如果模型经过微调或服务提供商尚未支持,直接调用将无法满足需求。
# 2. 在测试环境中部署模型
在 4.1 节的课程中,你通过微调一个小参数模型(Qwen3-0.6B),在加速推理的同时保持了较高的准确度。接下来,你需要部署这个微调后的模型以提供服务。
部署模型通常包括下载模型、编写加载代码和发布为支持API访问的应用服务,这涉及较高的人工成本。vLLM是一个专为大模型推理设计的开源框架,可以简化这一流程。它通过简单的命令行参数快速部署模型,并通过内存优化和缓存策略提升推理速度和支持高并发请求。
本节将使用vLLM加载模型并启动服务。该服务提供的HTTP接口兼容OpenAI API,可以通过调用/v1/chat/completions等接口,让你快速体验大模型的推理能力。
# 2.1 环境准备
本课程实验环境需与第4.1蒸馏章节保持一致,确保在GPU环境下执行模型部署操作。
如已按课程目录顺序学习,请继续使用第4.1章节启动的PAI-DSW实例;若单独学习本章节,则按第4.1章节环境准备进行配置即可。
请在指定目录下打开Terminal终端窗口。
在本课程的目录下,即/mnt/workspace/aliyun_acp_learning/大模型ACP认证教程/C4_交付上线,打开一个新的终端窗口。
你可以在终端窗口中输入pwd命令查看终端窗口所在的目录位置。可通过执行如下命令,将终端窗口切换到本课程目录下。
1 |
# 2.2 使用vLLM部署模型
# 2.2.1 部署开源模型
推荐你在ModelScope模型库 (opens new window)中下载Qwen3-0.6B模型进行部署。(境外开发者也可以访问HuggingFace模型库 (opens new window)下载开源模型进行部署,暂不在此演示。)
首先,下载模型文件到本地。
!mkdir -p ./model/qwen3-0.6b
!modelscope download --model qwen/Qwen3-0.6B --local_dir './model/qwen3-0.6b'
2
下载成功后,模型文件会保存在./model/qwen3-0.6b文件夹下。
接着安装依赖项,在终端窗口执行以下指令安装vllm(如果你遇到版本冲突,你也可以尝试安装vllm==0.6.2版本)
1 |
安装好vllm后,在终端窗口执行vllm命令启动一个模型服务。
vllm serve "./model/qwen3-0.6b" --load-format "safetensors" --port 8000
- vllm serve:表示启动模型服务。
- "./model/qwen3-0.6b":表示加载的模型路径,通常包含模型文件、版本信息等。
- --load-format "safetensors":指定加载模型时使用的格式。
- --port 8000:指定端口号,如果端口被占用,请切换为其他端口,如8100等。
服务启动成功后,终端窗口会打印 “INFO: Uvicorn running on socket ('0.0.0.0', 8000) (Press CTRL+C to quit)” 信息。
请注意,关闭终端窗口将会立即终止服务。后续的测试和评估性能将依赖于该服务进行,因此请不要关闭此终端窗口。
如果你希望在后台持续运行服务而不受终端窗口关闭的影响,可以使用这条命令。
# 后台运行服务,且服务的运行日志存储到vllm.log nohup vllm serve "./model/qwen3-0.6b" --load-format "safetensors" --port 8000 > vllm.log 2>&1 &1
2
# 2.2.2 部署微调模型(可选)
第 4.1 节的微调模型默认放在output目录。下面示例选择微调后的merge模型进行部署。请打开一个新的终端窗口执行vllm命令。
1 |
- "./output/qwen3-0.6b/v0-202xxxxx-xxxxxx/checkpoint-xxx-merged":替换为真实的微调模型路径。
- --port 8001:设置与步骤2.1中不同的端口号,避免端口占用。
# 2.3 测试服务运行状态
vLLM 支持启动兼容OpenAI API的本地服务器,即按照OpenAI API标准返回结果。
通过cURL发送HTTP请求,测试 2.2.1 中部署的qwen3-0.6b模型服务是否能够正常响应。如果使用微调模型服务,请确保将请求的URL端口号从8000修改为8001。
%%bash
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "./model/qwen3-0.6b",
"messages": [
{"role": "system", "content": "你是一个帮助助手。"},
{"role": "user", "content": "请告诉我2008年北京奥运会,中国队总共获得了多少枚金牌?"}
]
}'
2
3
4
5
6
7
8
9
10
上述接口正常响应即表示服务正常运行。
此外,还兼容了 /v1/models 接口,支持查看部署的模型列表。更多信息请查看vLLM兼容的OpenAI API (opens new window)。
%%bash
curl -X GET http://localhost:8000/v1/models
2
# 2.4 评估服务性能
为了评估部署后的模型服务性能,这里使用一个简单的HTTP性能测试工具wrk来快速模拟压测请求并生成报告。下面以压测 POST /v1/chat/completions 接口为例,展示服务的相关性能指标。
首先,打开一个新的终端窗口,安装压测工具wrk的依赖包。注意:终端窗口是在步骤1中指定的目录下。
sudo apt update
sudo apt install wrk
2
接着,准备POST请求所需要的Body数据。数据已放在./resources/2_9/post.lua文件,文件内容如下所示。
wrk.method = "POST"
wrk.headers["Content-Type"] = "application/json"
wrk.body = [[
{
"model": "./model/qwen3-0.6b",
"messages": [
{"role": "system", "content": "你是一个帮助助手。"},
{"role": "user", "content": "请告诉我2008年北京奥运会,中国队总共获得了多少枚金牌?"}
]
}
]]
2
3
4
5
6
7
8
9
10
11
然后,在终端窗口执行wrk压测命令,分别设置chat接口的并发量(-c)为1和10,压测时间(-d)均为10s,观察两个实验的压测结果。
wrk -t1 -c1 -d10s -s ./resources/2_9/post.lua http://localhost:8000/v1/chat/completions
wrk -t1 -c10 -d10s -s ./resources/2_9/post.lua http://localhost:8000/v1/chat/completions
2
3
wrk压测结果如下所示:
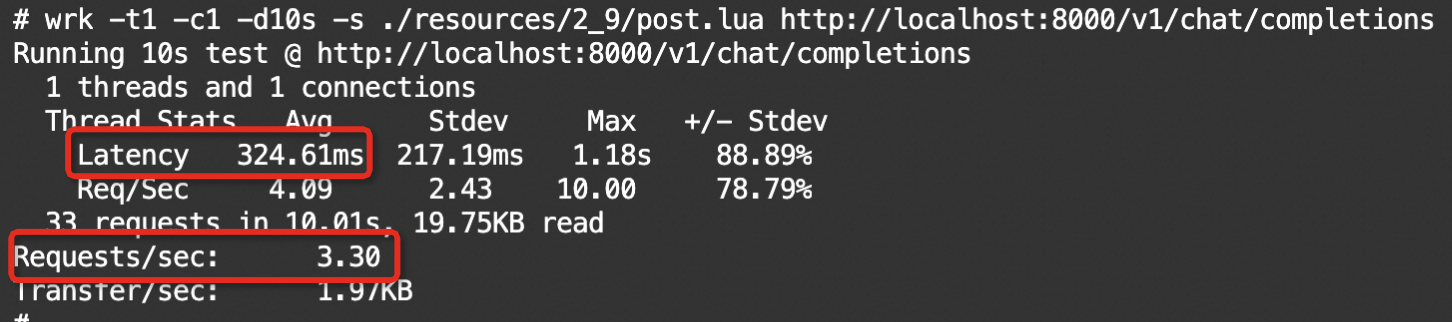
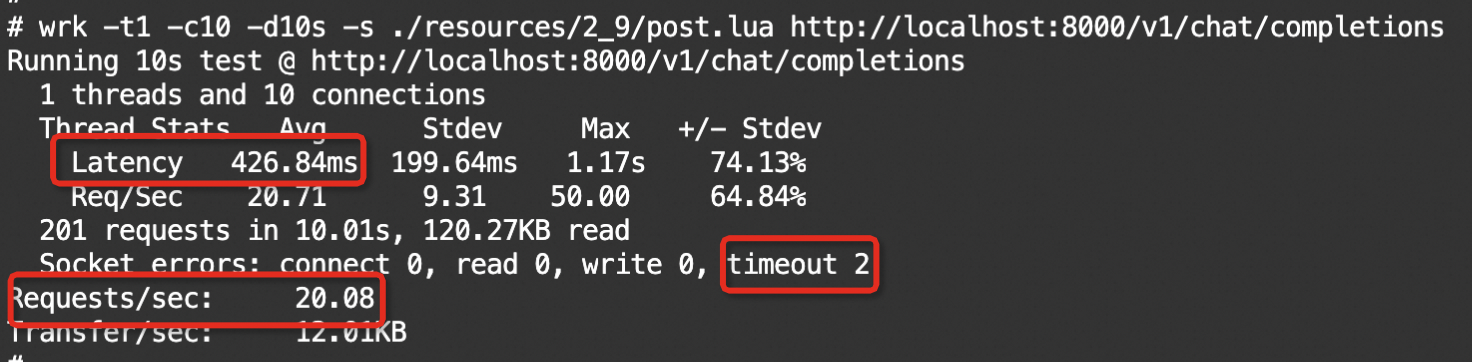
根据压测结果可见,随着并发量增加(1 -> 10),QPS提升了约6倍(3.30 -> 20.08),平均延迟增加了约30%(324.61ms -> 426.84ms)。特别地是,第二个压测实验中出现了2个超时错误。这是因为在并发量较高情况下,服务器的负载超过了其处理能力,性能的不足导致了部分请求超时。
# ☁3. 在云上部署模型
上述压测结果显示,由于部署模型的设备算力有限,模型服务无法满足低延迟和高并发的推理需求。
传统的解决方式是通过购买更高性能的“服务器”,并重新将模型部署到服务器上。但是这种方式的问题在于:
资源成本:需要一次性购买大量高性能的“服务器”。
运维成本:日常维护服务器,包括监控、升级、故障排查等,需要较高的专业技能。
可靠性:服务的稳定可靠一方面依赖于维护人员的能力,另一方面依赖于项目成本,在有限的成本下,很难建立高可用、稳定可靠的模型服务。
灵活性较低:受限于固有的硬件资源,无法根据实际需要动态调整资源,从而导致模型服务性能不足或资源浪费。
相对于购买服务器部署模型,使用云服务部署模型 通常是一种更好的选择。云服务可以为你提供更多灵活的部署方式,你可以根据自身能力和需求,选择大模型服务平台百炼 (opens new window)、函数计算FC (opens new window)、人工智能平台PAI-EAS (opens new window)、GPU云服务器 (opens new window)、容器服务ACK (opens new window)、容器计算服务ACS (opens new window)等云服务,以获得可扩展、高并发、低延迟、灵活管理以及稳定的服务,快速适应业务变化。
# 3.1 使用大模型服务平台百炼部署模型
你可以使用百炼的控制台页面完成模型的快速部署,这种方式简单、直接,你无需掌握复杂的部署模型方法,也可以轻松拥有独占的模型服务。同时也可以通过简单的API部署模型 (opens new window)。
部署过程如下所示:

- 选择模型:选择预置模型或自定义模型。
预置模型:百炼支持的标准模型,根据需要选择合适的模型进行部署,可在部署新模型 (opens new window)时查看支持的模型。
自定义模型:百炼平台调优后的模型,可参考:调优支持的模型 (opens new window)。
- 一键部署模型:控制台上支持一键部署模型,也可以通过API快速部署。
- 基于百炼生态使用模型:部署后的模型可无缝集成百炼生态,支持在百炼控制台直接使用,并可通过HTTP和DashScope调用复用百炼API。
模型部署操作可参考百炼部署模型 (opens new window)文档。
虽然通过百炼平台部署模型可以大大降低模型部署和维护的难度,但因为百炼平台支持的模型种类有限,如果你的模型不在支持的范围内,可以通过接下来的几种方法进行部署。
# 3.2 使用函数计算FC部署模型
函数计算FC的部署方式支持更多类型的模型,函数计算提供Serverless GPU服务,无需运维底层资源,秒级自动扩缩容,同时通过按需付费,对于不频繁使用的模型可以节省大量的成本,尤其适合计算资源要求高的临时任务。
通过函数计算来部署模型也不是没有缺点:
- 冷启动延迟:如果一段时间内没有请求到达,则函数可能会进入“冷”状态,在接收到新的调用请求时需要重新启动实例,这可能导致首次响应时间较长。
- 调试难度增加:基于函数的应用可能更难于调试和监控。在多步骤处理流程中定位问题较难。
综上,使用函数计算FC部署模型的方式非常适合轻量级推理任务、对实时性要求不高的低频访问场景(如离线批处理、定时或事件触发任务)。
但是,如果你的任务场景对实时性要求较高,或需要加强复杂的模型推理的监控和调试,可以尝试使用接下来的集中方式部署模型。
部署参考:你可以一键部署Qwen3推理模型 (opens new window)体验函数计算提供的部署能力,更多部署实践可参见函数计算3.0-实践教程 (opens new window)。
# 3.3 使用 PAI-EAS 部署模型
你还可以通过人工智能平台PAI的模型在线服务(EAS)将从开源社区下载的模型或自己训练获得的模型部署为在线服务。它提供的弹性扩缩容、蓝绿部署、资源组管理、版本控制以及资源监控等功能,帮助你更好地管理模型应用。
EAS非常适合于实时同步推理场景,为了解决模型初次请求耗时较长的问题,EAS提供了模型预热功能,使模型服务在上线之前得到预热,从而实现模型服务上线后即可进入正常服务状态。
相比较于函数计算,PAI-EAS可能会有更高的固定成本,对于低频使用的场景,可能不如函数计算FC经济实惠,你可以尝试通过 Spot Instance 模式帮助节省成本,详见:PAI-EAS Spot最佳实践 (opens new window)。
部署参考:你可以参考5分钟使用EAS一键部署LLM大语言模型应用 (opens new window)来快速部署一个通用模型,立即体验PAI-EAS所提供的模型服务能力。若你希望部署自定义模型,建议参考如何挂载自定义模型? (opens new window)。
# 3.4 使用云服务器ECS或容器服务部署模型
通过云服务器ECS部署模型是比较通用的部署方式,可以完全控制服务器的配置、操作系统和环境设置,这对于需要高度定制化和特定依赖项的模型非常有用。
同时ECS提供了稳定的计算资源,不会像函数计算那样有冷启动延迟的问题。ECS可以结合弹性伸缩服务ESS实现实例的弹性扩容和缩容,结合负载均衡器(如SLB)来实现高可用性和负载均衡。还可以通过安全组、访问控制、数据加密等,确保数据和服务的安全性。
但是这些功能的配置和管理需要一定的技能和经验,维护成本较高。
- 适合场景:需要高度定制化、稳定性能和长期运行的大型模型;对成本可预测性和资源控制有较高要求的企业。
- 不适合场景:需要快速部署和弹性伸缩的小型项目;对运维复杂性敏感且资源有限的团队。
部署参考:你可以参考使用vLLM容器镜像快速构建大语言模型在GPU上的推理环境 (opens new window)执行具体操作。如果你要部署的模型是Llama模型、ChatGLM模型、百川模型、千问模型及其微调模型,推荐安装并使用DeepGPU-LLM进行模型的推理服务 (opens new window)以加速模型推理能力。
如果你的组织已经积累了基于容器的模型部署经验,也可以使用 ACK 结合 GPU 云服务器节点,无需学习过多新概念。
另外,你也可以考虑使用 ACS,可以帮助你在熟悉的 Kubernetes 容器集群环境中,直接获取 GPU 算力容器,同时无需关注集群的运维。
部署参考:
# 3.5 云服务方案对比和决策推荐
在阿里云上部署模型时,选择不同的服务需要综合考虑业务需求、模型特性、技术能力、运维复杂度、成本等因素。以下是对上面几种常见的云服务部署方式的对比分析及选择建议:
| 服务名称 | 特点 | 适用场景 |
|---|---|---|
| 阿里云百炼 | 大模型专属平台,提供一键部署、模型优化、API调用管理,封装底层复杂性。 | 快速部署大模型(如千问系列),无需关注基础设施。 |
| 函数计算(FC) | Serverless 架构,按请求量计费,自动扩缩容,免运维。 | 适用于需要轻量级推理任务、低频访问场景(如定时任务、事件触发)。 |
| PAI-EAS | 模型在线服务平台,支持自定义模型部署,弹性扩缩容,监控等能力。 | 中小型深度学习模型(如图像分类、NLP),需弹性扩缩容和细粒度资源管理。 |
| GPU云服务器 | IaaS层资源,灵活安装任意框架和依赖,需手动管理运维。 | 自定义模型训练/推理,需要完全掌控环境(如复杂依赖、特殊硬件需求)。 |
| 容器服务ACK/容器计算服务ACS | Kubernetes集群部署,集成CI/CD、自动扩缩容、负载均衡。 | 复杂微服务架构、混合工作负载、大规模分布式推理或训练。 |
模型部署服务选择建议:
你的核心需求是什么?
- 快速上线大模型 → 百炼(如对话机器人、生成式AI)。
- 低成本轻量级服务/低频非实时任务 → 函数计算FC(如每天数百次查询的小工具)。
- 常规模型部署(图像/文本/NLP) → PAI-EAS(平衡性能与易用性)。
- 自定义环境或复杂依赖 → GPU云服务器 或 ACK。
服务部署模型兼容性
- 千问系列模型优先选:百炼。
- 通用模型:函数计算FC、PAI-EAS、GPU云服务器(支持TensorFlow/PyTorch/ONNX等全生态)、容器化部署(ACK/ACS)。
运维复杂度与团队技术能力?
- 免运维:非技术团队 → 百炼(可视化操作)。
- 运维复杂度底:算法工程师 → PAI-EAS、开发团队 → 函数计算FC。
- 运维复杂度高:DevOps成熟团队 → ACK(需维护复杂流水线) 或 GPU云服务器(需自行管理环境)。
成本控制
- 低成本轻量级场景:函数计算FC(按请求数和资源消耗付费,无闲置成本)。
- 中等成本:PAI-EAS(按实例规格和时长付费,适合稳定流量,可通过)。
- 高成本但灵活:GPU云服务器(按量付费/包年包月,需自行优化资源利用率)。
- 综合成本较高:ACK(涉及集群管理费用和资源调度复杂度)。
# ✅本节小结
本节课程详细介绍了模型部署的基本方法,你学习了:
部署模型的实操步骤,即如何将模型部署为一个可访问的模型推理服务,部署模型可以是开源模型或微调后的模型。
部署模型并不是必须的,你可以直接调用服务提供商(如阿里云)完全托管的API服务,从而有效降低业务初期投入成本,避免闲置GPU资源的浪费。
根据自身的需求和能力选择不同的云服务(如百炼平台、函数计算FC、PAI-EAS、云服务器ECS、ACK/ACS等方式)部署模型,从而实现业务需求和资源利用的平衡。
通过本课程的学习,你已经掌握了模型部署的基本方法,为构建高性能、可扩展的大模型应用打下了坚实的基础。
接下来,你将进一步学习在大模型应用的生产环节中如何更好地保障模型的可用性、安全性和性能。
⚠️ 注意:完成本节学习后,请及时停止当前的 PAI-DSW GPU 实例,以避免产生额外费用。
# 扩展阅读
本课程介绍了云端部署,在实际部署中可分为公共云部署和专有云部署。
公共云部署:将模型封装为API供用户调用,类似SaaS模式。这种方式降低了使用门槛,便于集成,但需要确保API稳定和安全。
专有云部署:在企业内部搭建专有云平台,并将模型部署在专有云上。它能提供更高的数据安全性和控制权,支持定制化,但需投入一定的维护成本。
此外,端云协同部署也是一种常见的部署方式。
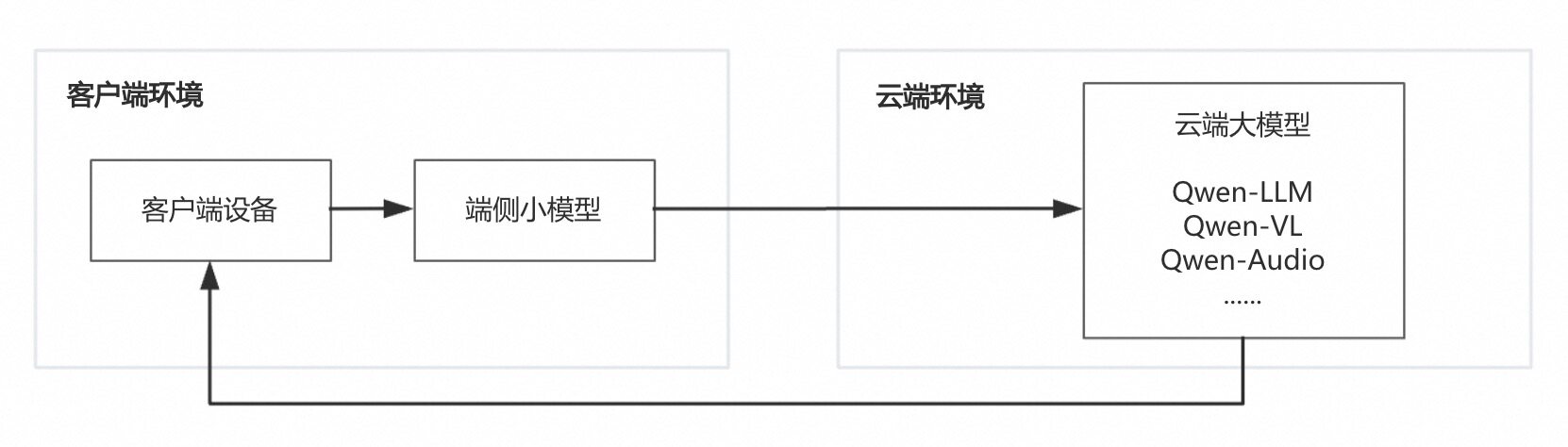
端云协同部署结合云端和边缘部署的优势,部分计算在边缘设备上进行,复杂计算任务则上传到云端处理,能够在保证用户体验的同时处理复杂的计算任务。
端云协同部署适用于需要实时响应但计算资源有限的场景,如乐天派与千问大模型合作打造端侧陪伴智能语音机器人,见下图。这里的“端”指客户端部署的小模型,“云”指云端部署的大模型。这些小模型需要微调以适配不同客户端设备,并与客户端应用在同一个环境中,负责初步处理数据预处理等简单任务,然后将处理后的信息传输给云端,由云端大模型进行深入处理,以快速且高质量响应端侧用户需求。
在一些特定场景,嵌入式系统部署是更为合适的选择,如汽车、机器人和医疗设备等。这种方式将模型部署在硬件平台上,能够实现实时控制和决策,但对模型和硬件的优化要求较高。
因此,在面对实际业务需求时,你需要考虑系统的性能要求、数据隐私和安全性,以及实施的复杂性,从而确保部署方案的高效与可持续性。
# 🔥 课后小测验
# 🔍 单选题 4.2.1
选择云服务API还是自托管部署的关键判断因素是什么❓ - A. 自托管一定比云服务便宜
- B. 要算账:月调用量、GPU运维成本、盈亏平衡点
- C. 云服务一定比自托管快
- D. 只有大公司才能自托管
【点击查看答案】
✅ 参考答案:B
📝 解析:
没有绝对的好坏之分。云服务零运维、按量付费,适合规模不确定的早期阶段;自托管成本低但需要GPU运维能力,适合流量稳定、规模够大的场景。选型的本质是算一笔账:月调用量多少时自托管成本低于云服务?这个盈亏平衡点因场景而异。
# 🔍 单选题 4.2.2
一个三人创业团队正在开发 AI 客服产品,目前日均调用量约 500 次,没有专职运维人员,使用的是千问系列模型。团队希望尽快上线验证商业模式。最合适的部署方式是?❓ - A. 租用 GPU 云服务器自行部署 vLLM,完全掌控推理环境和性能调优
- B. 使用百炼平台一键部署,通过 API 直接集成到产品中
- C. 使用容器服务 ACK 搭建 Kubernetes 集群,方便后续扩展微服务架构
- D. 使用函数计算 FC 部署模型,利用 Serverless 按需计费降低成本
【点击查看答案】
✅ 参考答案:B 📝 解析: 三个关键约束决定了选型:千问系列模型(百炼原生支持)、无运维人员(排除需要运维能力的 GPU 服务器和 ACK)、快速上线(百炼一键部署最快)。GPU 云服务器和 ACK 都需要较强的运维能力,不适合三人团队。函数计算 FC 虽然也免运维,但它更适合低频离线任务且有冷启动延迟问题,对客服这种需要实时响应的场景不够理想。百炼平台零运维、可视化操作、API 直接调用,是这个阶段的最优选择。
# ✉️ 评价反馈
感谢你学习阿里云大模型ACP认证课程,如果你觉得课程有哪里写得好、哪里写得不好,期待你通过问卷提交评价和反馈 (opens new window)。
你的批评和鼓励都是我们前进的动力。