
 用蒸馏让小模型掌握专业能力
用蒸馏让小模型掌握专业能力
# 4.1 用蒸馏让小模型掌握专业能力
# 🚄 前言
前面的课程中,你搭建了一个能回答问题的答疑机器人:用 RAG 让它查阅公司政策,用 Agent 让它调用工具处理复杂请求。系统已经能"做事"了,但部署到生产环境后,你发现了一个新的瓶颈。
员工不会"规规矩矩"地提问。一句话里塞两个请求、措辞模糊、不说紧急程度,系统需要先"读懂"每条提问,才能决定交给谁处理:
| 员工提问 | 系统需要理解的信息 |
|---|---|
| "我下周三要出差去杭州,顺便催一下上个月的报销" | 两个意图(差旅申请 + 报销催办)、目的地、时间、路由到多意图拆分 |
| "VPN连不上急死了" | IT支持、高紧急度、路由到直接回答 |
| "新来的实习生需要开通哪些系统权限" | 入职办理 + 权限申请、路由到 RAG 查政策 |
这个"请求理解"步骤,目前靠大模型完成,效果很好。但问题是:每条请求都先过一遍大模型,只为了"读懂问题",还没开始"回答问题",成本就花了一半。
有没有办法让一个小模型来做这件事?小模型推理成本低、速度快,但直接拿来用,JSON 格式经常崩坏,多意图识别也不准。
蒸馏就是来解决这个问题的:把大模型的判断能力"复制"给小模型。
# 🍁 课程目标
学完本节课程后,你将能够:
- 理解蒸馏的核心思想,区分蒸馏与微调的本质差异。
- 掌握数据合成蒸馏的完整流程:教师标注 → 质量过滤 → 学生训练。
- 在 PAI-DSW 上使用 ms-swift 完成 LoRA 微调。
- 用量化指标(JSON 合规率、意图 F1、路由准确率)验证蒸馏效果。
- 分析蒸馏的成本收益,做出合理的部署决策。
# 0. 环境准备
本节课需要在 GPU 环境中运行(基座模型本地推理 + LoRA 训练)。请按以下步骤创建 PAI-DSW GPU 实例。
如果你已经在课时 1.0 中创建了 CPU 型 DSW 实例,需要另外新建一个 GPU 型实例。
# 0.1 创建 GPU 型 DSW 实例
- 前往 PAI 控制台 (opens new window) → 交互式建模(DSW)→ 新建实例
- 资源规格:选择 GPU 型实例,推荐
ecs.gn7i-c8g1.2xlarge(A10,显存 30GB) - 镜像:选择
modelscope:1.35.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
💡 GPU 实例消耗免费额度较快(约 7 计算时/小时),建议在需要运行代码时开启,不用时及时停止实例避免扣费。创建实例的详细图文指引见课时 1.0。
# 0.2 安装环境依赖
实例启动后,在 DSW 顶部打开 Terminal,依次执行:
cd /mnt/workspace
wget https://developer-labfileapp.oss-cn-hangzhou.aliyuncs.com/ACP/aliyun_llm_acp_install.sh
/bin/bash aliyun_llm_acp_install.sh
2
3
脚本会自动创建 llm_learn 虚拟环境、克隆课程代码、安装基础依赖。
# 0.3 安装 Qwen Code(可选)
课时 3.2 中你在 CPU 实例上安装过 Qwen Code,但当前的 GPU 实例是独立环境,需要重新安装。在 DSW Terminal 中执行:
bash -c "$(curl -fsSL https://qwen-code-assets.oss-cn-hangzhou.aliyuncs.com/installation/install-qwen.sh)" -s --source qwenchat < /dev/null
安装完成后,在 Terminal 中执行 qwen 启动 Qwen Code(首次使用需 ApiKey 鉴权,参考课时 3.2)。本节课的多个环节提供了 Qwen Code 体验入口,安装后即可使用。
# 0.4 打开 Notebook 并切换内核
在 IDE 或 DSW 中,点击右上角内核名称 → 选择 Python (llm_learn)
# 0.5 加载 API Key 并安装训练依赖
下方两个 cell 分别加载 DashScope API Key(用于调用教师模型)和安装本章训练所需的额外依赖。
import os, json, re, sys
os.chdir(os.path.join(os.path.dirname(os.path.abspath('')), 'course_core'))
sys.path.insert(0, os.getcwd())
from config.load_key import load_key
load_key()
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
print(f'API Key 已加载:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}')
2
3
4
5
6
7
8
9
10
11
12
13
14
# 安装训练专用依赖(基础依赖已由安装脚本完成,此处仅安装 LoRA 训练所需的额外组件)
#
# 版本约束说明:
# transformers >=4.51 — Qwen3 架构支持(4.45 没有 qwen3,加载模型会报 architecture not recognized)
# transformers <5.0 — 5.x 要求 PyTorch>=2.4,但 DSW 镜像预装的是 2.3.1
# ms-swift >=3.0 — Qwen3 训练支持(2.x 不支持 Qwen3,且参数名与 4.x 不同)
# modelscope >=1.20 — 旧版 modelscope 加载 Qwen3 时会委托给 transformers 失败
%pip install -i https://mirrors.aliyun.com/pypi/simple/ 'transformers>=4.51,<5.0' 'ms-swift>=3.0' accelerate autoawq autoawq-kernels 'modelscope>=1.20.0'
2
3
4
5
6
7
8
# 0.5 下载基座模型
从 ModelScope 下载 Qwen3-0.6B 到本地。这个模型将在 Section 4 中用于基座模型评测,在 Section 6 中用于 LoRA 训练。
# 下载 Qwen3-0.6B 模型(约 1.2GB,下载约 1-2 分钟)
!modelscope download --model Qwen/Qwen3-0.6B --local_dir /mnt/workspace/model
2
# 1. 任务设计:请求理解
# 1.1 为什么需要"请求理解"
在前面的课程中,你已经构建了 RAG 系统(课时 2.2)和 Agent 工具链(课时 2.6)。但在生产环境中,系统收到一条员工提问后,第一步不是直接回答,而是要判断:这条提问应该交给谁处理? 简单的事实问题("公司WiFi密码是多少")可以直接回答;需要查政策的问题("年假可以跨年使用吗")要交给 RAG;包含多个独立请求("请假 + 催报销")需要拆分后分别处理;而"我要投诉我的主管"这类需要人工判断的情况则要转人工。
这个判断过程就是"请求理解":把一句自然语言,转成结构化的工单信息。
# 1.2 结构化工单的定义
我们定义的工单 JSON 包含五个字段:
{
"intents": ["差旅申请", "报销催办"],
"department": "行政",
"urgency": "中",
"entities": {"出差日期": "下周三", "目的地": "杭州"},
"route": "multi_intent_split"
}
2
3
4
5
6
7
| 字段 | 类型 | 取值范围 | 说明 |
|---|---|---|---|
| intents | 字符串数组 | 入职办理、考勤请假、差旅申请、报销催办、年假查询、IT支持、权限申请、制度咨询 | 可多选 |
| department | 字符串 | HR、行政、IT、财务 | 主要负责部门 |
| urgency | 字符串 | 高、中、低 | 根据时间敏感度和措辞判断 |
| entities | 对象 | 自由键值对 | 从提问中提取的关键参数(日期、金额、人名等) |
| route | 字符串 | direct_answer、rag_query、multi_intent_split、escalate | 路由决策 |
# 1.3 这个任务为什么适合蒸馏
"请求理解"有三个特点,决定了它适合用小模型来做:输出格式固定(JSON schema 确定,不需要开放式生成),不依赖外部知识(判断意图和紧急度只看输入文本本身),而且每条请求都要执行(高频调用链路,成本敏感)。
大模型已经能做好这件事了。蒸馏的目标是:把大模型在这个任务上的判断能力,迁移给一个推理成本更低的小模型。
# 2. 蒸馏原理
# 2.1 蒸馏的核心思想
微调是"让模型学会做这件事",训练数据通常由人工标注。蒸馏是"把另一个更强模型的判断方式复制给你的模型",训练数据由教师模型生成。两者的训练流程几乎相同(都是 SFT),区别在于训练数据的来源:
| 微调 | 蒸馏 | |
|---|---|---|
| 数据来源 | 人工标注 | 教师模型生成 |
| 数据成本 | 高(需要领域专家) | 低(API 调用费) |
| 数据规模 | 通常有限 | 可大规模生成 |
| 质量上限 | 取决于标注者水平 | 取决于教师模型能力 |
蒸馏的核心逻辑很简单:大模型已经"会做"这件事了,我们只需要把它的输出当作训练数据,教给小模型。 蒸馏的本质是在微调之前增加一步高质量数据构建环节。你不需要先把教师模型微调到极致再做蒸馏,直接用当前最强的 API 模型(如 qwen3.6-plus)生成数据即可。重点在于数据质量,而非复杂流程。
蒸馏在生产降本中已有大量应用。阿里巴巴发布的 DistilQwen2.5 系列 (opens new window)(0.5B-7B)通过多个大模型协作做教师蒸馏,蒸馏后的轻量模型在指令遵循能力上显著优于同参数量的原始基座。DeepSeek-R1 (opens new window) 将 671B 参数模型的 80 万条推理轨迹蒸馏到 7B 学生模型,使其在数学推理上超越了 LLaMA-2 70B。
# 2.2 三条蒸馏路径
根据"复制"的内容不同,蒸馏可以分为三种方式:
路径一:数据合成蒸馏 / 黑盒蒸馏(本章实操)
用教师模型的 API 生成标注数据,再用这些数据训练学生模型。只需要 API 访问权限,不需要教师模型的权重,因此称为"黑盒"——你只能看到教师的输出,看不到它内部的计算过程。这是最实用的蒸馏方式,适合教师模型是商业 API 的场景。
路径二:知识蒸馏 KD / 白盒蒸馏(概念了解)
学生不仅学习教师的最终输出,还学习教师输出每个 token 时的概率分布(软标签)。比如教师在判断部门时,内部可能给出"HR 70%、行政 25%、IT 5%"这样的概率分布,最终输出选概率最高的"HR",但这个分布本身包含了"HR 和行政有点像"这种隐含知识(暗知识),比只看最终答案信息量更大。白盒蒸馏就是让学生去拟合教师的概率分布,而不仅仅学最终答案。之所以叫"白盒",是因为需要访问教师模型的权重和内部状态。商业 API 拿不到权重,用不了这种方式,但如果教师模型开源,白盒蒸馏的精度通常更高。
路径三:推理压缩(概念了解)
学生学习教师的思维链(Chain-of-Thought)轨迹,而非仅学最终答案。DeepSeek-R1 就是用这种方式,将 800K 条推理轨迹蒸馏给 7B 学生模型,使其在推理任务上超越了 70B 基座模型。适合需要多步推理的任务。
| 路径 | 别名 | 需要什么 | 适用场景 |
|---|---|---|---|
| 数据合成蒸馏 | 黑盒蒸馏 | 只需教师 API | 结构化任务、教师是商业 API |
| 知识蒸馏 KD | 白盒蒸馏 | 需要教师权重 | 开源教师、需要更高精度 |
| 推理压缩 | — | 需要教师推理输出 | 多步推理任务 |
# 2.3 本章为什么选数据合成
回到我们的"请求理解"任务:教师模型(qwen3.6-plus)是 API 服务,无法访问权重,白盒 KD 行不通;任务是单步判断(从输入直接到结构化输出),不需要多步推理,CoT 轨迹没有必要;而结构化输出可以用 JSON schema 自动校验质量,数据质量有保障。因此,数据合成蒸馏(黑盒蒸馏)是最合适的选择。
# 3. 数据合成
蒸馏的第一步是用教师模型生成训练数据。流程分三步:
- 生成多样化的员工提问
- 用教师模型标注结构化工单
- 质量过滤 + 格式化为训练数据
💡 小贴士:训练数据已预先生成在
resources/4_1/目录下,你可以直接使用。下面的代码展示数据是如何生成的,帮助你理解蒸馏数据合成的完整流程。如果你想自己尝试生成,运行这些代码会产生少量 API 调用费用。
# 🤖 用 Qwen Code 合成训练数据(可选)
如果你在 Section 0 中安装了 Qwen Code,现在可以让它帮你完成数据合成的全过程——生成提问、教师标注、质量过滤、格式化保存,一气呵成。如果你不想使用 Qwen Code,可以跳过这一步,直接使用 resources/4_1/train.jsonl 中的预生成数据,阅读下方代码理解流程。
将以下提示词复制到 Qwen Code 中执行:
我正在做模型蒸馏的训练数据合成。请帮我完成以下任务,每步完成后向我展示结果。
## 环境信息
- 工作目录:cd /mnt/workspace/aliyun_acp_learning/大模型ACP认证教程/C4_交付上线
- 虚拟环境:source /mnt/workspace/llm_learn/bin/activate
- API Key 已配置在环境变量 DASHSCOPE_API_KEY 中(通过 config/load_key.py 加载)
- 教师模型:qwen3.6-plus(通过 DashScope 兼容 OpenAI 接口调用)
- API 地址:https://dashscope.aliyuncs.com/compatible-mode/v1
## 任务背景
我们要为一个"员工请求理解"任务生成蒸馏训练数据。任务是把员工的自然语言提问转成结构化 JSON 工单,包含 5 个字段:intents(意图)、department(部门)、urgency(紧急度)、entities(实体)、route(路由)。
## 第 1 步:加载 API Key
运行以下 Python 代码加载 API Key 并初始化 client:
```python
import os, json, re, sys
os.chdir(os.path.join(os.path.dirname(os.path.abspath('')), 'course_core'))
sys.path.insert(0, os.getcwd())
from config.load_key import load_key
load_key()
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
print(f"API Key 已加载:{os.environ['DASHSCOPE_API_KEY'][:5]}*****")
```
## 第 2 步:用大模型生成 30 条员工提问
调用 qwen3.6-plus 生成多样化的员工提问。要求:
- 覆盖 8 种意图:入职办理、考勤请假、差旅申请、报销催办、年假查询、IT支持、权限申请、制度咨询
- 混合正式、口语化、含糊等表达风格
- 约 30% 为多意图问题(一句话包含两个请求)
- 部分问题包含具体日期、金额、人名、地点
生成完后展示前 10 条给我看看。
## 第 3 步:用教师模型标注
对每条提问调用 qwen3.6-plus 进行标注,使用以下 system prompt:
"""
你是一个请求理解助手。分析用户的提问,提取结构化工单信息。
严格按以下 JSON 格式输出,不要输出任何其他内容:
{
"intents": ["意图"],
"department": "部门",
"urgency": "紧急度",
"entities": {},
"route": "路由"
}
字段取值范围:
- intents(可多选):入职办理、考勤请假、差旅申请、报销催办、年假查询、IT支持、权限申请、制度咨询
- department:HR、行政、IT、财务
- urgency:高、中、低
- entities:从提问中提取的关键参数(日期、金额、人名、地点、系统名称等),如无则为空对象 {}
- route:direct_answer(简单事实问题)、rag_query(需要查阅政策文档)、multi_intent_split(包含多个独立意图)、escalate(需要人工介入)
"""
调用时设 temperature=0.1。标注完后展示 3 条标注结果给我看看。
## 第 4 步:质量过滤
对每条标注做三项检查:
1. JSON 能否正常解析
2. 5 个必填字段(intents、department、urgency、entities、route)是否齐全
3. 每个字段的值是否在上面 system prompt 定义的取值范围内
过滤掉不合格的样本,告诉我总共生成了多少条、过滤了多少条、保留了多少条。
## 第 5 步:格式化并保存
将合格样本转成 ms-swift 的 messages 训练格式:
```json
{"messages": [{"role": "system", "content": "system prompt 内容"}, {"role": "user", "content": "员工提问"}, {"role": "assistant", "content": "JSON 标注结果"}]}
```
每条一行,保存到 resources/4_1/my_train.jsonl。保存完后告诉我文件路径和样本数量。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
💡 Qwen Code 生成的数据保存在
resources/4_1/my_train.jsonl。后续训练时,如果你想用自己生成的数据,将训练命令中的train.jsonl替换为my_train.jsonl即可。课程预生成的train.jsonl(约 1400 条)覆盖更全面,建议正式训练时仍使用预生成数据。
无论你是否使用了 Qwen Code,下面我们来详细拆解数据合成的每一步,理解背后的设计思路。
# 3.1 教师模型的 System Prompt
教师模型(qwen3.6-plus)需要一个精确的 system prompt 来规范输出格式。这个 prompt 定义了 JSON schema 和每个字段的取值范围:
SYSTEM_PROMPT = """你是一个请求理解助手。分析用户的提问,提取结构化工单信息。
严格按以下 JSON 格式输出,不要输出任何其他内容:
{
"intents": ["意图"],
"department": "部门",
"urgency": "紧急度",
"entities": {},
"route": "路由"
}
字段取值范围:
- intents(可多选):入职办理、考勤请假、差旅申请、报销催办、年假查询、IT支持、权限申请、制度咨询
- department:HR、行政、IT、财务
- urgency:高、中、低
- entities:从提问中提取的关键参数(日期、金额、人名、地点、系统名称等),如无则为空对象 {}
- route:direct_answer(简单事实问题)、rag_query(需要查阅政策文档)、multi_intent_split(包含多个独立意图)、escalate(需要人工介入)"""
print("System Prompt 已定义")
print(f"Prompt 长度:{len(SYSTEM_PROMPT)} 字符")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 3.2 生成多样化的员工提问
数据多样性是蒸馏质量的关键。我们从多个维度设计 prompt 模板来生成提问:覆盖 8 种意图类型 × 4 个部门的场景组合,混合正式请求、口语化、含糊省略等多种表达风格,约 30% 为多意图问题(一句话包含两个请求),部分问题包含具体日期、金额、人名、地点等实体信息。
# 以下是其中一个生成模板的示例
query_prompt_example = """请生成15条不同员工向公司内部答疑机器人提出的问题。要求:
1. 覆盖场景:入职办理、考勤请假、差旅申请、报销催办
2. 表达风格多样:正式、口语化、含糊、简短、详细
3. 约30%为多意图问题(一句话包含两个请求)
4. 部分问题包含具体的日期、金额、人名、地点
每条问题单独一行,不要编号,不要其他说明。
注意:场景中涉及的系统、工具、平台只能使用虚拟名称或阿里系产品(如钉钉、阿里云等),不要提及任何非阿里旗下的真实公司或产品名称。"""
# 实际使用了 5 个不同侧重的模板,覆盖所有意图类型和表达风格
# 完整的数据生成脚本见 resources/4_1/generate_data.py
print("生成模板示例:")
print(query_prompt_example)
2
3
4
5
6
7
8
9
10
11
12
13
14
# 3.3 教师标注
对每条生成的提问,用教师模型(qwen3.6-plus)生成结构化标注。标注时使用 system prompt 严格约束输出格式,temperature=0.1 降低随机性以确保标注一致性,每条标注都经过 JSON schema 校验后才能进入训练集。
# 如果重启了内核但没有重新运行 Section 0,自动重新初始化
import os, json, re, sys
os.chdir(os.path.join(os.path.dirname(os.path.abspath('')), 'course_core'))
sys.path.insert(0, os.getcwd())
if 'client' not in globals():
from config.load_key import load_key
load_key()
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
print("⚠️ client 未找到,已自动重新初始化。建议从 Section 0 开始按顺序运行。")
def teacher_label(query, system_prompt=SYSTEM_PROMPT):
"""用教师模型标注一条查询"""
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
temperature=0.1
)
return response.choices[0].message.content
# 试标注一条
test_query = "我下周三要出差去杭州,顺便催一下上个月的报销"
result = teacher_label(test_query)
print(f"输入:{test_query}")
print(f"教师标注:")
print(json.dumps(json.loads(result), ensure_ascii=False, indent=2))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 3.4 质量过滤
教师模型不是 100% 完美的。即使是 qwen3.6-plus 这样的强模型,在批量标注几百条数据时也会出错:JSON 写到一半截断、漏掉某个字段、把部门写成不存在的值。这些"坏样本"如果混进训练集,学生模型会把错误也学进去。因此,我们需要对教师的输出做一轮自动化质量校验,把不合格的样本过滤掉。
以下是实际生产中最常见的三类问题:

过滤用的是"结果校验"(检查输出是否符合 schema),而非"过程校验"(检查推理过程是否合理),对于结构化提取任务这种方式简单有效。下面分别用 Qwen Code 和 Python 代码两种方式实现同样的过滤逻辑。
# 🤖 用 Qwen Code 完成质量过滤(可选)
质量过滤的逻辑并不复杂,但手写校验代码仍然需要逐字段处理。换一种思路:用自然语言把过滤规则描述清楚,让 Qwen Code 帮你生成并执行过滤代码。
resources/4_1/labeled_raw.jsonl 是一份预置的体验数据(35 条),其中故意混入了 5 条有问题的样本(JSON 截断、字段缺失、取值越界等),方便你观察过滤效果。将以下提示词复制到 Qwen Code 中执行:
我有一批教师模型标注的数据需要质量过滤。请帮我完成以下任务:
## 环境信息
- 工作目录:/mnt/workspace/aliyun_acp_learning/大模型ACP认证教程/C4_交付上线
- 数据文件:resources/4_1/labeled_raw.jsonl(每行是一个JSON,包含 query 和 label 字段)
## 过滤规则
对每条样本的 label 字段进行三项检查:
1. **JSON 格式检查**:label 必须是合法 JSON,如果包含 markdown 代码块标记(```),需要先提取其中的 JSON 内容
2. **必填字段检查**:必须包含以下 5 个字段,缺一不可
- intents(数组)
- department(字符串)
- urgency(字符串)
- entities(对象)
- route(字符串)
3. **取值范围检查**:
- intents 必须是以下之一或多个:入职办理、考勤请假、差旅申请、报销催办、年假查询、IT支持、权限申请、制度咨询
- department 必须是:HR、行政、IT、财务
- urgency 必须是:高、中、低
- route 必须是:direct_answer、rag_query、multi_intent_split、escalate
- entities 必须是对象类型
## 任务要求
1. 读取 labeled_raw.jsonl 文件
2. 对每条样本应用上述过滤规则
3. 统计并报告:总样本数、合格数、过滤数、过滤原因分布
4. 将合格样本保存为 resources/4_1/train_filtered.jsonl
5. 展示前 3 条合格样本和 3 条被过滤的样本(说明原因)
请用 Python 实现并执行。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
体验完 Qwen Code 的过滤结果后,继续阅读下方代码,理解过滤逻辑的具体实现。
AI 辅助编程与传统编程的对比:
| 维度 | Qwen Code(自然语言驱动) | Python 代码(手写逻辑) |
|---|---|---|
| 上手难度 | 低,用自然语言描述规则 | 中,需要编写 Python 代码 |
| 灵活性 | 高,可随时调整规则描述 | 中,需要修改代码逻辑 |
| 可维护性 | 适合快速原型和实验 | 适合生产环境长期维护 |
| 执行效率 | 依赖 AI 的代码生成能力 | 直接执行,效率确定 |
| 适用场景 | 规则频繁变化、快速验证 | 规则稳定、需要版本控制 |
💡 在实际工作中,你可以先用 Qwen Code 快速验证过滤规则的效果,确认规则设计合理后,再将其固化为 Python 代码用于生产环境。两种方式是互补关系,不是二选一。
# 过滤代码实现
下面用 Python 实现同样的三条过滤规则。理解这段代码的逻辑,也有助于你在使用 Qwen Code 时写出更精确的过滤规则描述:
VALID_INTENTS = {"入职办理", "考勤请假", "差旅申请", "报销催办", "年假查询", "IT支持", "权限申请", "制度咨询"}
VALID_DEPARTMENTS = {"HR", "行政", "IT", "财务"}
VALID_URGENCY = {"高", "中", "低"}
VALID_ROUTES = {"direct_answer", "rag_query", "multi_intent_split", "escalate"}
def validate_label(label_str):
"""校验教师标注是否合格"""
try:
# 处理可能的 markdown 代码块包裹
if '```' in label_str:
match = re.search(r'```(?:json)?\s*(.*?)\s*```', label_str, re.DOTALL)
if match:
label_str = match.group(1)
label = json.loads(label_str.strip())
except json.JSONDecodeError:
return None # JSON 解析失败
# 检查必填字段
required = ["intents", "department", "urgency", "entities", "route"]
if not all(k in label for k in required):
return None
# 检查取值范围
if not isinstance(label["intents"], list) or len(label["intents"]) == 0:
return None
if not all(i in VALID_INTENTS for i in label["intents"]):
return None
if label["department"] not in VALID_DEPARTMENTS:
return None
if label["urgency"] not in VALID_URGENCY:
return None
if label["route"] not in VALID_ROUTES:
return None
if not isinstance(label["entities"], dict):
return None
return label
# 用一条测试数据验证校验函数
test_label = '{"intents": ["差旅申请", "报销催办"], "department": "行政", "urgency": "中", "entities": {"目的地": "杭州"}, "route": "multi_intent_split"}'
print("校验合格样本:", "通过 ✓" if validate_label(test_label) else "失败 ✗")
bad_label = '{"intents": ["不存在的意图"], "department": "HR", "urgency": "高", "entities": {}, "route": "direct_answer"}'
print("校验不合格样本:", "通过 ✓" if validate_label(bad_label) else "过滤 ✓(意图不在取值范围内)")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 3.5 查看预生成数据
训练数据已经预先生成好了,我们来看看数据的内容和分布:
# 加载预生成的训练数据
train_data = []
with open("resources/4_1/train.jsonl", "r", encoding="utf-8") as f:
for line in f:
train_data.append(json.loads(line))
# 加载预生成的测试数据
test_data = []
with open("resources/4_1/test_30.jsonl", "r", encoding="utf-8") as f:
for line in f:
test_data.append(json.loads(line))
print(f"训练集:{len(train_data)} 条")
print(f"测试集:{len(test_data)} 条")
# 展示几条训练样本
print("\n--- 训练样本示例 ---")
for i, sample in enumerate(train_data[:3]):
query = sample["messages"][1]["content"]
label = json.loads(sample["messages"][2]["content"])
print(f"\n[样本 {i+1}]")
print(f" 提问:{query}")
print(f" 意图:{label['intents']}")
print(f" 部门:{label['department']} 紧急度:{label['urgency']} 路由:{label['route']}")
if label['entities']:
print(f" 实体:{label['entities']}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 数据分布统计
all_intents = {}
all_routes = {}
all_depts = {}
multi_intent = 0
for sample in train_data:
label = json.loads(sample["messages"][2]["content"])
for intent in label["intents"]:
all_intents[intent] = all_intents.get(intent, 0) + 1
all_routes[label["route"]] = all_routes.get(label["route"], 0) + 1
all_depts[label["department"]] = all_depts.get(label["department"], 0) + 1
if len(label["intents"]) > 1:
multi_intent += 1
print("--- 意图分布 ---")
for k, v in sorted(all_intents.items(), key=lambda x: -x[1]):
print(f" {k}: {v}")
print(f"\n--- 路由分布 ---")
for k, v in sorted(all_routes.items(), key=lambda x: -x[1]):
print(f" {k}: {v}")
print(f"\n--- 部门分布 ---")
for k, v in sorted(all_depts.items(), key=lambda x: -x[1]):
print(f" {k}: {v}")
print(f"\n多意图样本:{multi_intent}/{len(train_data)} ({multi_intent/len(train_data)*100:.0f}%)")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 3.6 训练数据格式
训练数据采用 ms-swift 框架要求的 messages 格式,每条样本包含三个角色的对话:
{
"messages": [
{"role": "system", "content": "你是一个请求理解助手..."},
{"role": "user", "content": "我下周三要出差去杭州..."},
{"role": "assistant", "content": "{\"intents\": [\"差旅申请\"], ...}"}
]
}
2
3
4
5
6
7
模型训练时,system 和 user 部分作为输入,assistant 部分作为期望输出。模型学习的是:给定 system prompt 和用户提问,生成正确的结构化 JSON。
# 4. 评测方法
在训练之前,我们先定义评测指标,然后摸清基座模型和教师模型各自的表现水平。
# 4.1 评测指标
结构化提取任务不适合用 BLEU 或 RAGAS 这类文本相似度指标,因为输出是严格定义的 JSON。我们从不同层面衡量模型表现:
- JSON 合规率:输出能否解析为合法 JSON 且包含所有必填字段。这是最基本的门槛,格式都不对就没法用。
- intents F1:意图识别的 F1 值,综合考虑精确率和召回率。为什么用 F1 而不是准确率?因为意图是多选的(一句话可能包含两个意图),单纯的准确率无法区分"漏了一个意图"和"全部答错"。F1 能同时反映模型是否"找全了"(召回率)又"没找错"(精确率)。计算方式是对每条样本的预测意图集合和真实意图集合分别求精确率和召回率,取调和平均得到该样本的 F1,最后对所有样本取算术平均。
- route 准确率:路由决策是否正确。路由决定了这条请求交给谁处理(直接回答、查 RAG、拆分多意图、转人工),是整个请求理解任务中最直接影响下游系统行为的字段,判断错了后续处理就全跑偏了。
💡 对于结构化提取任务,我们关注的是语义正确(每个字段的值在预定义范围内且符合语义),而非字符串完全匹配。比如一条包含"差旅申请"和"报销催办"两个意图的提问,只要模型正确识别出这两个意图,无论输出顺序如何,都算正确。
def compute_intent_f1(pred_intents, true_intents):
"""计算意图列表的 F1 值"""
pred_set = set(pred_intents)
true_set = set(true_intents)
if len(pred_set) == 0 and len(true_set) == 0:
return 1.0
if len(pred_set) == 0 or len(true_set) == 0:
return 0.0
precision = len(pred_set & true_set) / len(pred_set)
recall = len(pred_set & true_set) / len(true_set)
if precision + recall == 0:
return 0.0
return 2 * precision * recall / (precision + recall)
def evaluate_predictions(predictions, ground_truths):
"""
评测结构化提取结果,返回原始数值 dict:
- json_valid: JSON 合规的样本数
- intent_f1: 平均意图 F1(0~1)
- route_accuracy: 路由正确的样本数
- total: 样本总数
"""
n = len(ground_truths)
json_valid = 0
intent_f1_sum = 0
route_correct = 0
for pred, truth in zip(predictions, ground_truths):
parsed = pred["parsed"]
if parsed is None:
continue
json_valid += 1
# 意图 F1
f1 = compute_intent_f1(parsed.get("intents", []), truth["intents"])
intent_f1_sum += f1
# 路由准确率
if parsed.get("route") == truth["route"]:
route_correct += 1
return {
"json_valid": json_valid,
"intent_f1": intent_f1_sum / n if n > 0 else 0,
"route_accuracy": route_correct,
"total": n
}
def print_eval_results(results, model_name):
"""格式化打印评测结果"""
r = results
n = r["total"]
print(f"\n=== {model_name} 评测结果 ===")
print(f" JSON 合规率: {r['json_valid']}/{n} ({r['json_valid']/n*100:.0f}%)")
print(f" intents F1: {r['intent_f1']*100:.1f}%")
print(f" route 准确率: {r['route_accuracy']}/{n} ({r['route_accuracy']/n*100:.0f}%)")
def render_comparison_table(results_list, model_names):
"""将多组评测结果渲染为 Markdown 对比表格"""
from IPython.display import display, Markdown
header = "| 指标 | " + " | ".join(model_names) + " |"
sep = "| --- | " + " | ".join(["---"] * len(model_names)) + " |"
rows = []
for metric, label in [("json_valid", "JSON 合规率"), ("intent_f1", "intents F1"), ("route_accuracy", "route 准确率")]:
cells = []
for r in results_list:
n = r["total"]
if metric == "json_valid":
cells.append(f"{r['json_valid']}/{n} ({r['json_valid']/n*100:.0f}%)")
elif metric == "intent_f1":
cells.append(f"{r['intent_f1']*100:.1f}%")
else:
cells.append(f"{r['route_accuracy']}/{n} ({r['route_accuracy']/n*100:.0f}%)")
rows.append(f"| {label} | " + " | ".join(cells) + " |")
display(Markdown("\n".join([header, sep] + rows)))
def predict_batch(model_name, test_data, system_prompt=SYSTEM_PROMPT):
"""用指定模型对测试集批量预测"""
predictions = []
for item in test_data:
query = item["query"]
try:
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
extra_body={"enable_thinking": False},
temperature=0.1
)
raw = response.choices[0].message.content
except Exception as e:
raw = str(e)
parsed = validate_label(raw)
predictions.append({"raw": raw, "parsed": parsed})
return predictions
print("评测函数已定义")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
# 4.2 教师模型评测(qwen3.6-plus)
先看看教师模型在测试集上的表现,这是蒸馏的"能力上限":
ground_truths = [item["ground_truth"] for item in test_data]
print("正在评测教师模型(qwen3.6-plus)...")
teacher_preds = predict_batch("qwen3.6-plus", test_data)
teacher_results = evaluate_predictions(teacher_preds, ground_truths)
print_eval_results(teacher_results, "教师模型(qwen3.6-plus)")
2
3
4
5
6
# 4.3 基座小模型评测(Qwen3-0.6B)
再看看未经训练的小模型的表现,这是蒸馏前的"起点"。基座模型在 Section 0 中已下载到 /mnt/workspace/model,下方代码通过 ModelScope 加载并进行本地推理。
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
model_path = '/mnt/workspace/model'
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
base_model = AutoModelForCausalLM.from_pretrained(
model_path, dtype=torch.float16, device_map='auto',
trust_remote_code=True
)
print("正在评测基座模型(Qwen3-0.6B 本地推理)...")
base_preds = []
for i, item in enumerate(test_data):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": item["query"]}
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
enable_thinking=False
)
inputs = tokenizer(text, return_tensors="pt").to(base_model.device)
with torch.no_grad():
outputs = base_model.generate(
**inputs, max_new_tokens=512,
temperature=0.1, do_sample=True
)
response = tokenizer.decode(
outputs[0][inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
parsed = validate_label(response)
base_preds.append({"raw": response, "parsed": parsed})
status = "OK" if parsed else "FAIL"
print(f" [{i+1}/{len(test_data)}] {status} | {item['query'][:50]}...")
ground_truths = [item["ground_truth"] for item in test_data]
base_results = evaluate_predictions(base_preds, ground_truths)
print_eval_results(base_results, "基座模型(Qwen3-0.6B)")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
评测分数是一个总体概括,更有价值的是看看基座模型具体错在哪里。下面展示几条典型的失败案例,直观感受 0.6B 模型在未经训练时的输出质量:
# ⚠️ 需要先在 DSW 上运行 Section 4.3 的基座模型评测代码
# 如果 base_preds 不存在,跳过此 cell
if 'base_preds' in dir():
print("--- 基座模型典型失败案例 ---")
shown = 0
for i, (pred, truth) in enumerate(zip(base_preds, ground_truths)):
if pred["parsed"] is None and shown < 3:
print(f"\n[案例 {shown+1}] JSON 解析失败")
print(f" 提问:{test_data[i]['query']}")
print(f" 模型输出(前200字):{pred['raw'][:200]}")
print(f" 期望:{json.dumps(truth, ensure_ascii=False)[:100]}...")
shown += 1
if shown == 0:
for i, (pred, truth) in enumerate(zip(base_preds, ground_truths)):
if pred["parsed"] and pred["parsed"].get("department") != truth["department"] and shown < 3:
print(f"\n[案例 {shown+1}] 字段错误")
print(f" 提问:{test_data[i]['query']}")
print(f" 预测部门:{pred['parsed'].get('department')} 实际部门:{truth['department']}")
shown += 1
else:
print("base_preds 未定义,请先在 DSW 上运行 Section 4.3 的基座模型评测")
print("或查看 Section 4.4 的预生成对比结果")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
看完具体案例后,把基座模型和教师模型的结果放在一起对比。这两组数据分别代表蒸馏的起点和天花板:
# 渲染 Baseline 对比表格
# 如果已运行评测代码,使用实际结果;否则显示预生成参考数据
from IPython.display import display, Markdown
if 'base_results' in dir() and 'teacher_results' in dir():
print("### 4.4 Baseline 对比\n")
render_comparison_table(
[base_results, teacher_results],
["基座模型 (Qwen3-0.6B)", "教师模型 (qwen3.6-plus)"]
)
else:
display(Markdown("""### 4.4 Baseline 对比
> 以下为预生成参考数据,运行 Section 4.2 和 4.3 的评测代码后将显示实际结果。
| 指标 | 基座模型 (Qwen3-0.6B) | 教师模型 (qwen3.6-plus) |
| --- | --- | --- |
| JSON 合规率 | 15/31 (48%) | 31/31 (100%) |
| intents F1 | 23.7% | 83.9% |
| route 准确率 | 5/31 (16%) | 28/31 (90%) |"""))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
从测试样本的评测结果来看,基座模型与教师模型的差距非常明显:基座模型的大部分输出无法解析为合法 JSON,格式崩坏(缺括号、多余文字、字段错位)是最突出的问题。即使在格式正确的输出中,意图识别和路由准确率也很低,意味着绝大多数请求会被分发到错误的处理模块。相比之下,教师模型在各项指标上都表现稳定,说明大模型已经很好地掌握了这个任务。
蒸馏的目标:让 0.6B 模型从"几乎不可用"提升到"接近教师水平"。即使无法完全追平教师,只要在各项指标上有大幅提升,就已经具备生产部署价值。
到这里,训练数据已经就绪,基座模型和教师模型的表现差距也一目了然。接下来要用教师标注的数据训练小模型,让它从"几乎不可用"提升到"接近教师水平"。
你可能会想:用数据训练模型,这不就是微调吗?没错,蒸馏在训练流程上和微调几乎完全相同,都是准备训练数据、加载基座模型、执行 SFT 训练。唯一的区别在于数据来源:微调用人工标注的数据,蒸馏用教师模型生成的数据。所以如果你已经了解微调,接下来的内容会很熟悉;如果还不熟悉,也不用担心,下一节会从基础讲起。
# 5. 微调原理
在开始训练之前,先了解模型是如何通过训练数据学习的。
# 5.1 模型如何学习
# 损失函数
模型训练的核心是一个迭代优化过程:给定输入,模型生成预测;将预测与期望输出对比,计算损失(loss);然后调整模型参数,使损失变小。损失函数量化了"预测与期望的差距",损失越小,说明模型的输出越接近训练数据中的期望输出。
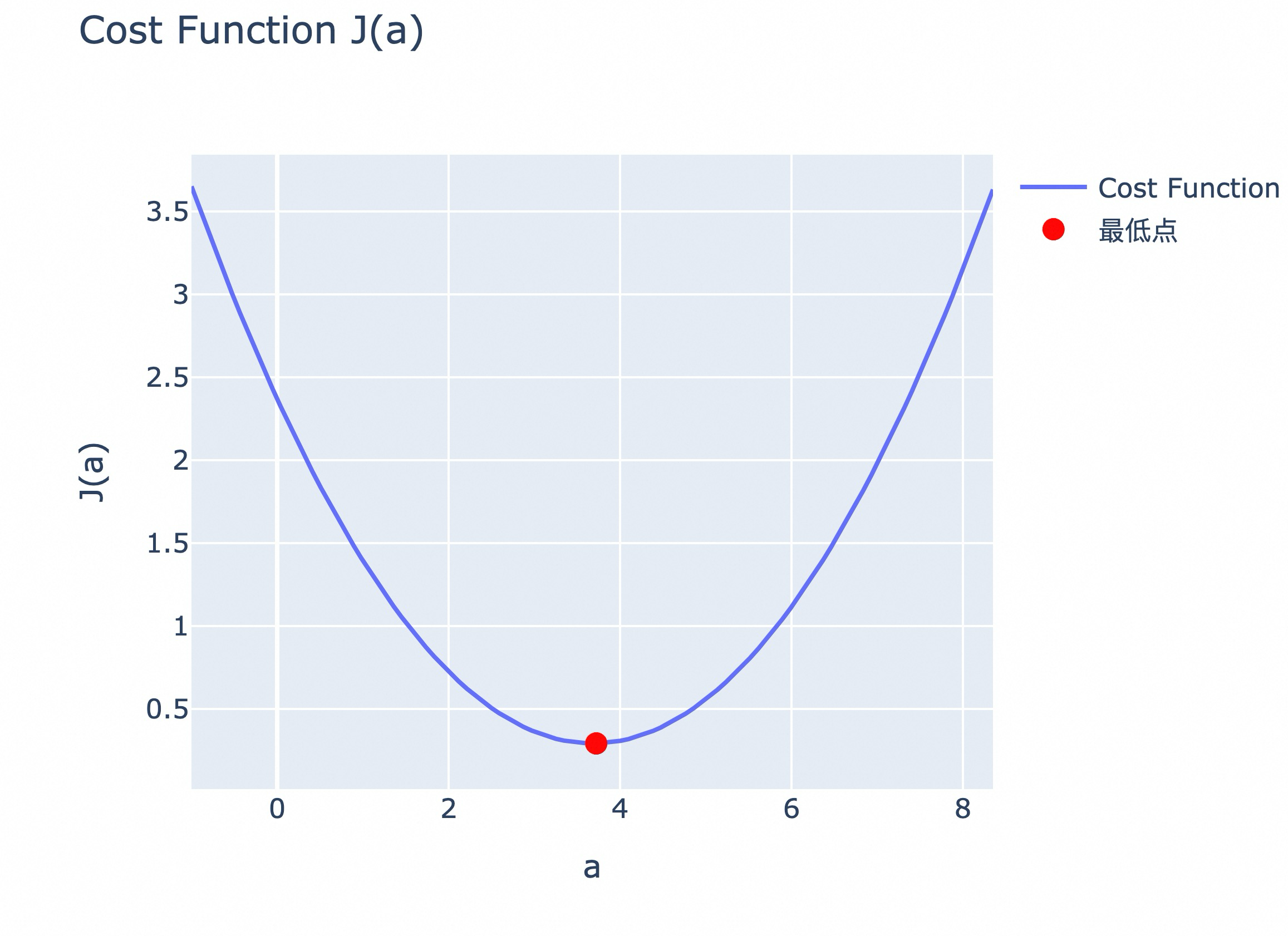
# 梯度下降
如何找到让损失最小的参数?梯度下降算法从一个随机起点出发,每一步沿着"损失下降最快的方向"调整参数,逐步逼近最优解。
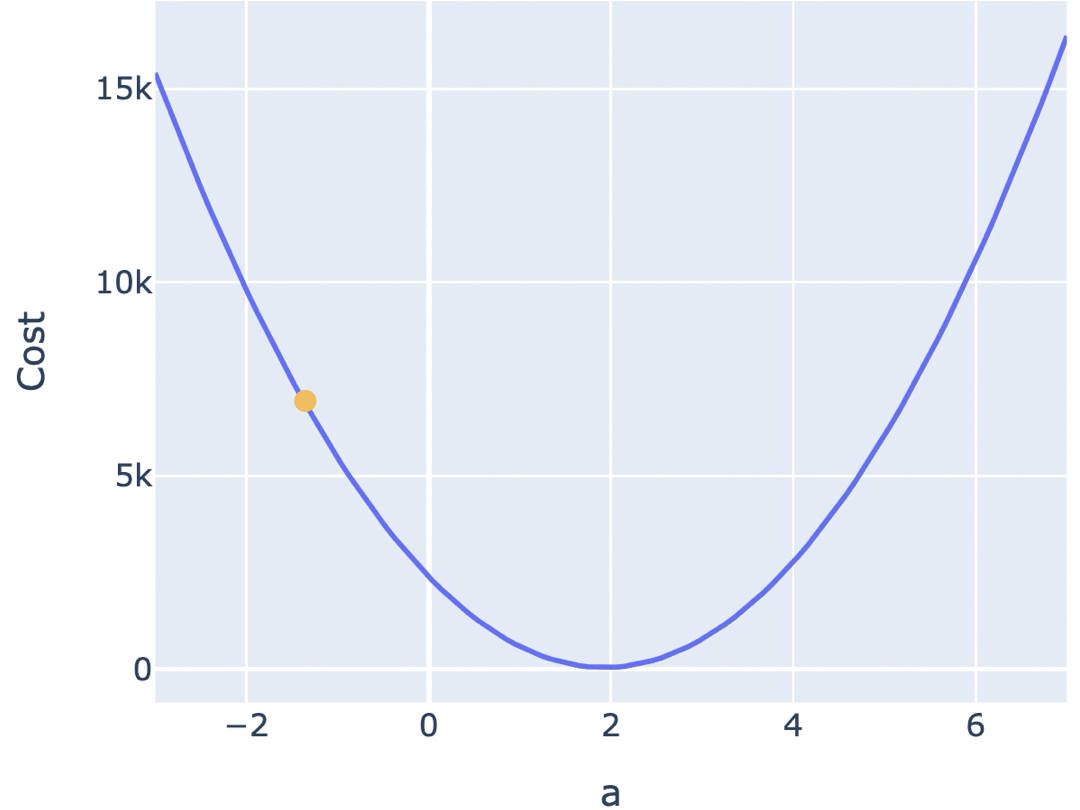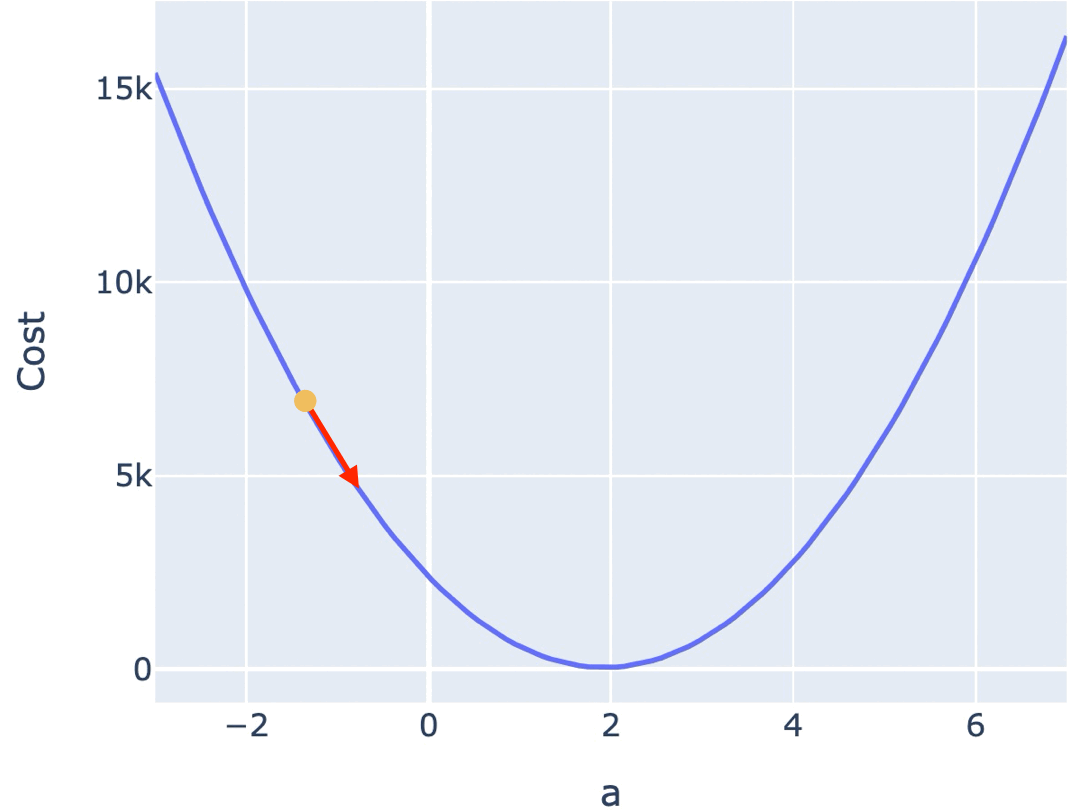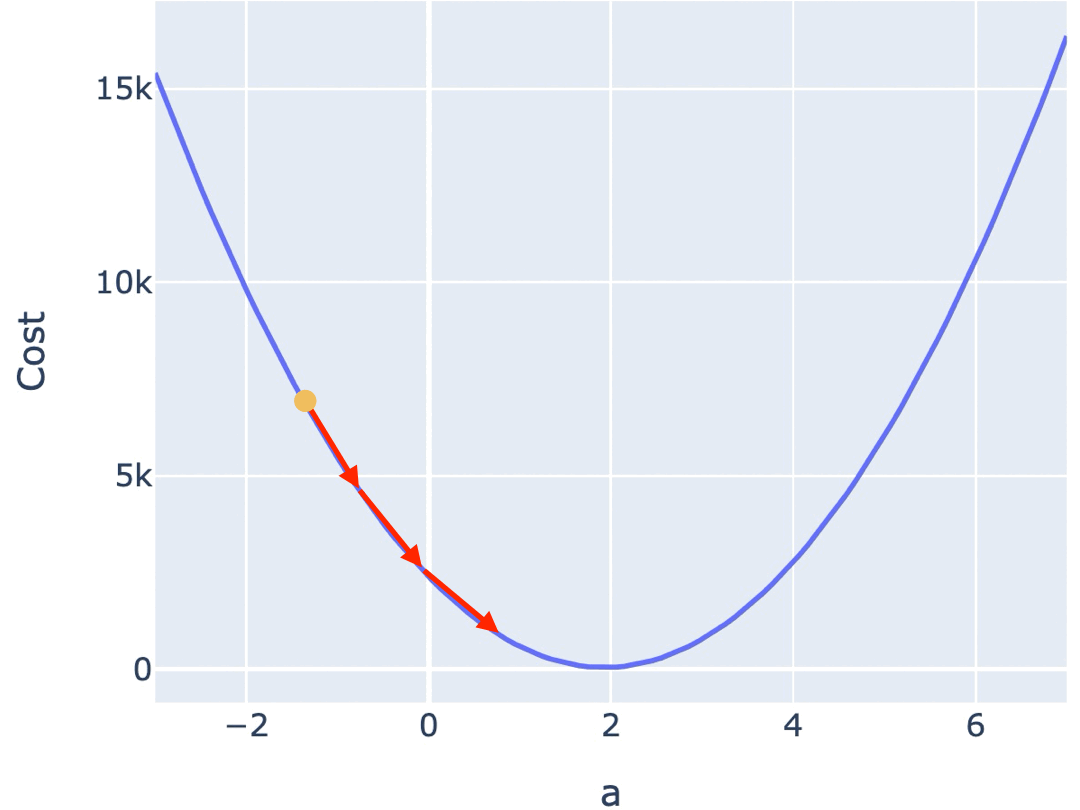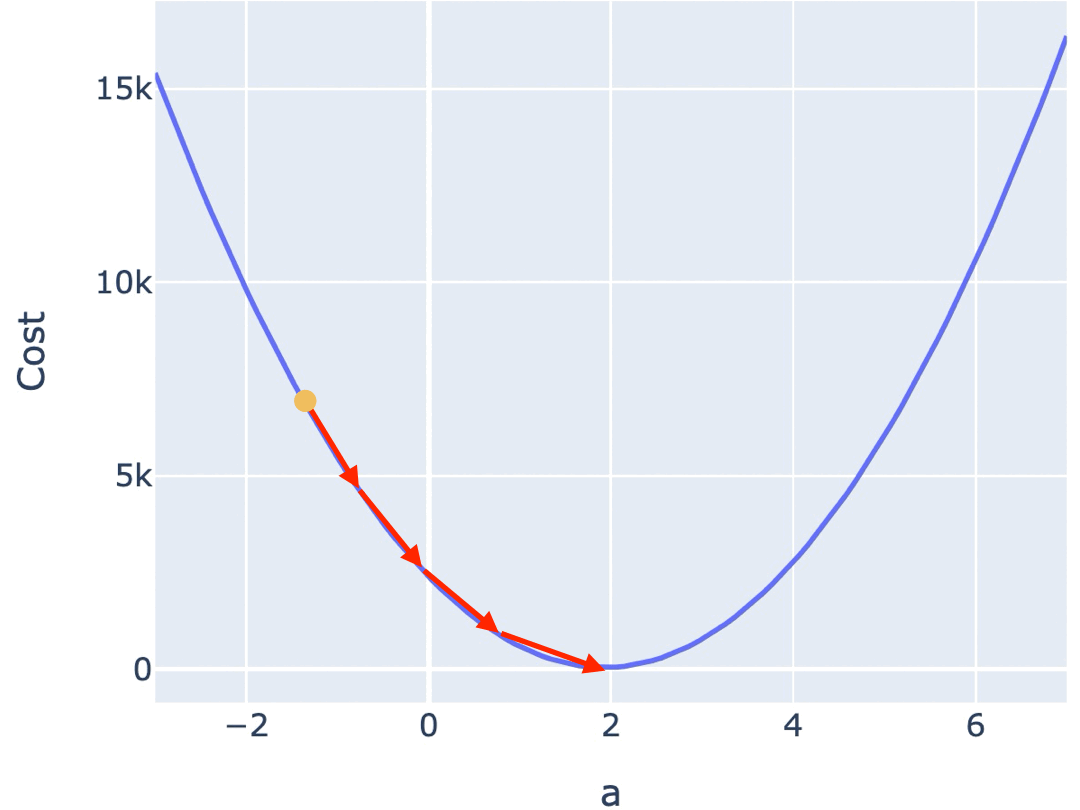
每一步的调整幅度由学习率(learning rate)决定。学习率太大,参数在最优解附近反复横跳无法收敛;太小则收敛速度慢,训练时间过长;合适的学习率才能稳步逼近最优解。
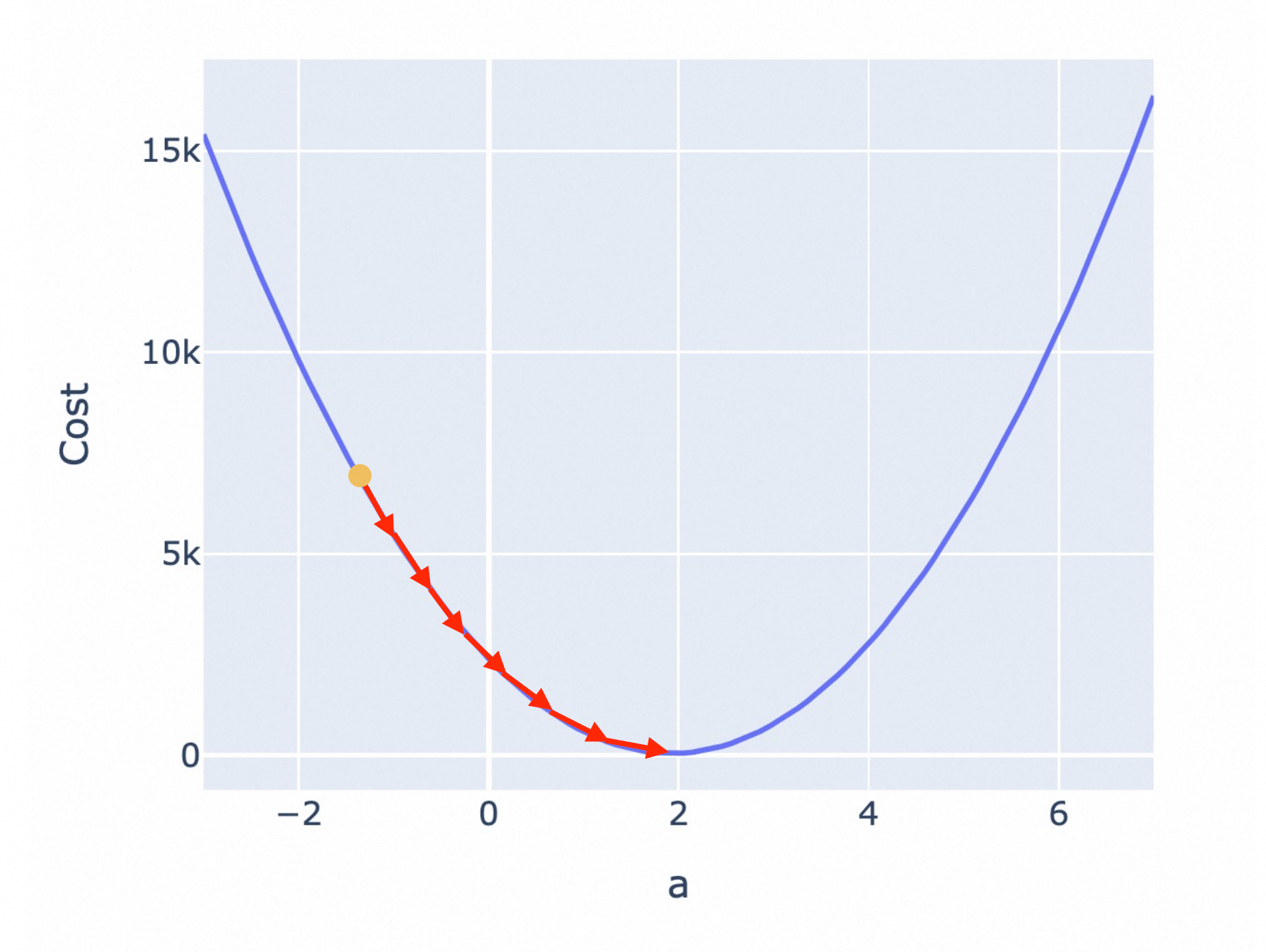
合适的学习率,能让你在较短的时间里,找到合适的参数。
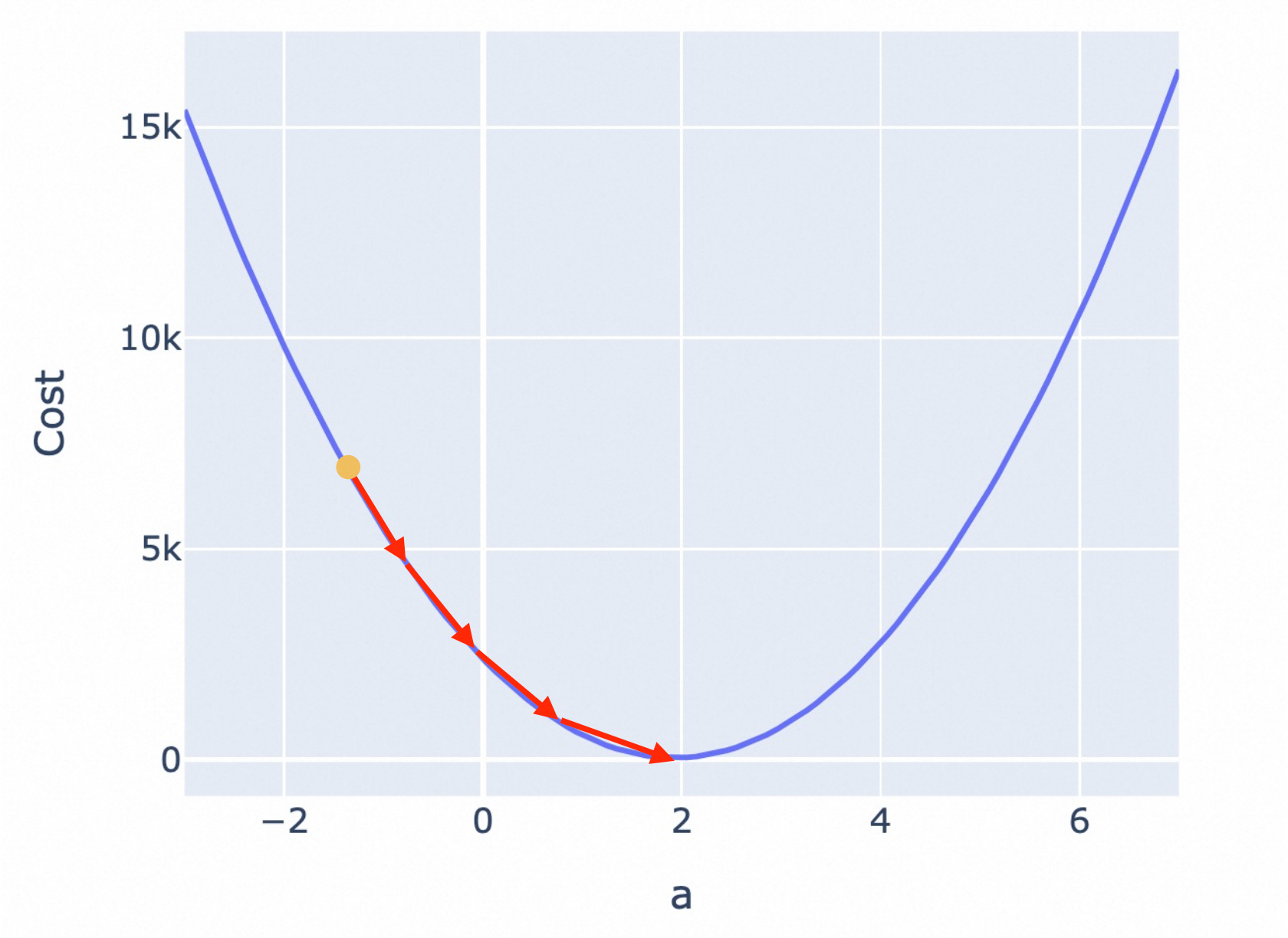
过低的学习率,虽然能找到合适的参数,但会有更大的耗时和资源消耗。
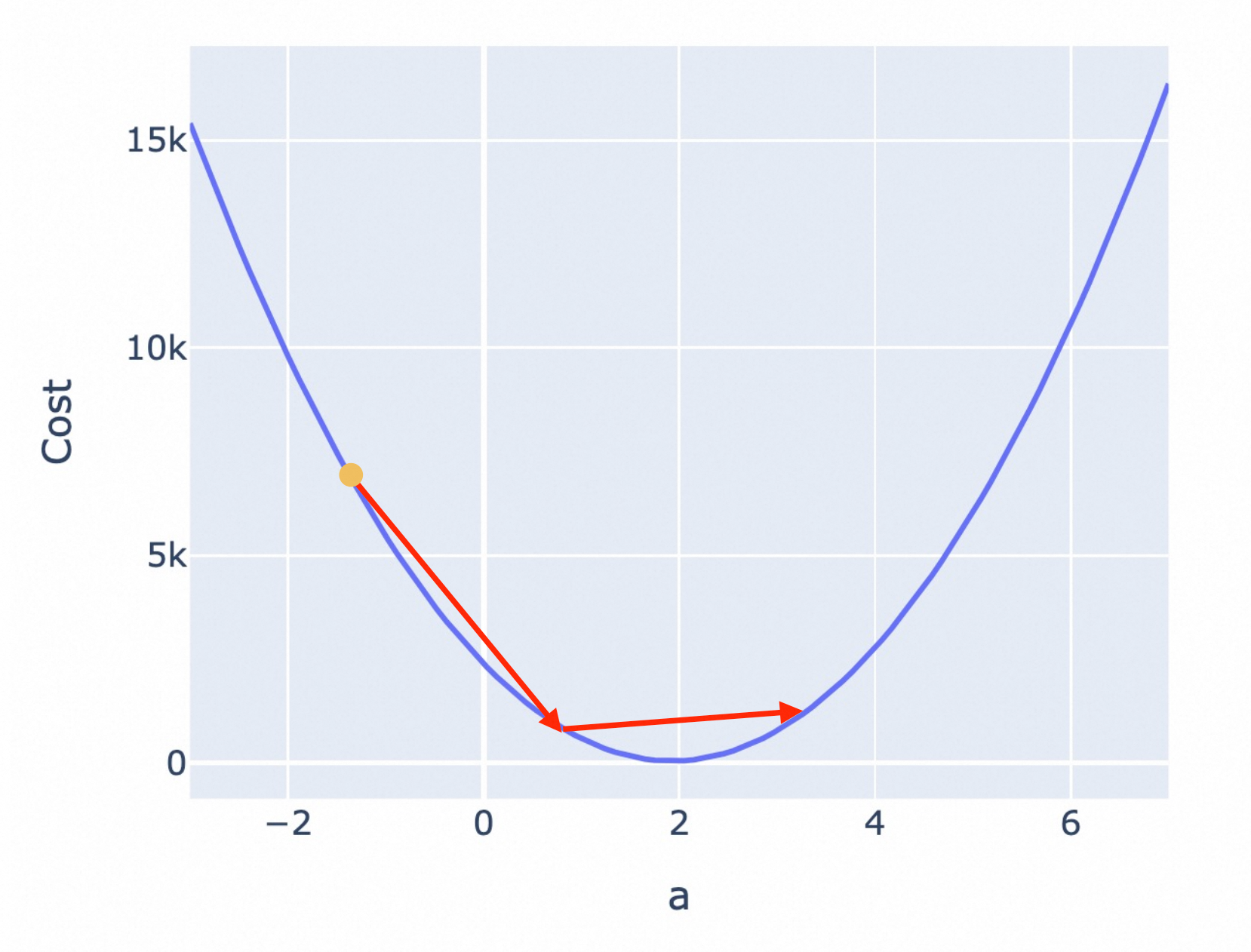
过高的学习率,可能导致你跳过了最优解,最终找不到最低点。
# 5.2 LoRA:高效微调
全参数微调需要更新模型的所有权重,大模型动辄数十亿参数,计算和存储成本都很高。LoRA(Low-Rank Adaptation)是一种高效的替代方案。
LoRA 的核心思想:不直接修改原始权重矩阵,而是在旁边"挂"一对小的低秩矩阵来学习变化量。
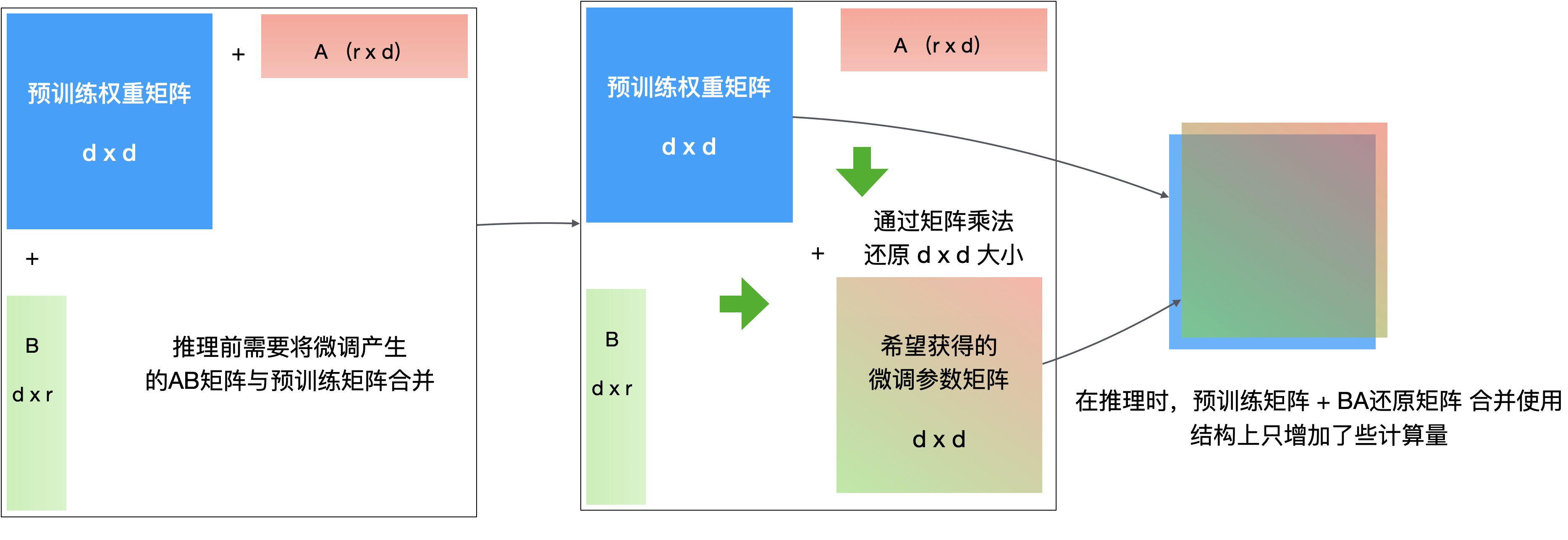
假设原始权重矩阵是 $W$(维度 $d \times d$),LoRA 将变化量 $\Delta W$ 分解为两个小矩阵的乘积:$\Delta W = A \times B$,其中 $A$ 的维度是 $d \times r$,$B$ 的维度是 $r \times d$,$r$ 远小于 $d$。
例如,当 $d = 4096$,$r = 8$ 时,全参数微调需要更新 $4096 \times 4096 = 16,777,216$ 个参数,而 LoRA 只需要更新 $4096 \times 8 + 8 \times 4096 = 65,536$ 个参数,参数量减少到原来的 0.4%。
LoRA 的关键参数 lora_rank(即 $r$)控制低秩矩阵的维度。$r$ 越大,可学习的变化量越多,但训练成本也越高。对于蒸馏任务,$r = 8$ 通常就够了。LoRA 还有一个重要优势:只训练"补丁"参数,原始模型权重不变,能保留模型 97% 以上的基础能力,有效避免"灾难性遗忘"。
# 5.3 训练状态判断
训练过程中,你需要关注两个关键指标来判断训练状态:训练损失(training loss)反映模型在训练数据上的表现,验证损失(evaluation loss)反映模型在未参与训练的验证数据上的表现。通过这两个指标的变化趋势,可以判断模型处于哪种状态:
| 训练损失 | 验证损失 | 状态 | 含义 |
|---|---|---|---|
| 不降 / 上升 | 不降 / 上升 | 训练失败 | 学习率可能太高,模型无法学习 |
| 下降 | 下降 | 欠拟合 | 模型在学习,但还没学够,继续训练 |
| 下降 | 先降后升 | 过拟合 | 模型在"背题",需要更多数据或减少训练轮次 |
| 趋于平稳 | 趋于平稳 | 训练成功 | 模型已经充分学习 |
# 6. 训练
环境依赖和基座模型已在 Section 0 中安装和下载完成。整个训练流程分四步:

| 步骤 | 说明 |
|---|---|
| 1. 准备数据 | 训练数据已预置在 resources/4_1/train.jsonl,确认文件可访问即可 |
| 2. 启动训练 | 运行下方 swift sft 命令,A10 GPU 上约 10 分钟 |
| 3. 监控 Loss | 观察训练日志中的损失变化,判断训练状态(参考 Section 5.3) |
| 4. 查看结果 | 模型和日志保存在 output/model/<训练目录>/(见下方说明),loss 曲线图在其 images/ 子目录,TensorBoard 日志在 runs/ 子目录 |
💡 ms-swift 会自动为每次训练创建一个目录,命名格式为
v{版本号}-{日期}-{时间},例如v1-20260415-145518。训练完成后,在output/model/下找到对应目录即可。
# 6.1 准备训练数据
确保 resources/4_1/train.jsonl 在当前目录下可访问。如果你通过安装脚本克隆了课程代码,训练数据已经就位。
# 6.2 开始训练
使用 ms-swift 框架进行 LoRA 微调。关键参数说明:
--model:Section 0 中下载的基座模型路径--model_type qwen3:显式指定模型类型(从本地路径加载时 ms-swift 无法自动识别)--split_dataset_ratio 0.1:自动切分 10% 训练数据作为验证集,用于监控过拟合--lora_rank 8:LoRA 低秩矩阵维度,8 对结构化提取任务足够--num_train_epochs 5:训练轮次--learning_rate 5e-5:学习率--per_device_train_batch_size 8:每张 GPU 的训练批次大小--eval_steps 20:每 20 步计算一次验证损失,用于观察是否过拟合
参数选择依据:这些参数不是固定值,需要根据具体情况调整。下表列出每个关键参数的调优方向:
| 参数 | 本课选值 | 调优方向 |
|---|---|---|
lora_rank | 8 | 训练数据 < 200 条可降到 4;> 2000 条或任务更复杂可升到 16 |
learning_rate | 5e-5 | loss 不降 → 调高到 1e-4;loss 震荡 → 调低到 1e-5 |
num_train_epochs | 5 | 验证损失开始上升 → 减少轮次;验证损失仍在下降 → 增加轮次 |
per_device_train_batch_size | 8 | 显存不足 → 减小到 4;显存充裕 → 增大可加速训练 |
💡 你可能注意到本课训练数据约 100 条,按表格建议似乎可以选
r=4。这里选r=8是因为"请求理解"需要同时学习意图识别(8 类多选)、部门判断、紧急度判断、实体提取和路由决策五个维度的联合映射,复杂度高于典型的单标签分类任务。表中"< 200 条可降到 4"更适用于输出只有一两个简单字段的场景。
# 🤖 试试用 Qwen Code 完成训练(可选)
你可以直接运行下方代码 cell 手动启动训练,也可以试试另一种方式:把提示词复制到 Qwen Code 中,让它帮你完成训练,并在过程中逐步讲解每个阶段正在发生什么。
如果你还没有安装 Qwen Code,参考 Section 0.3 中的安装步骤。
启动后,将以下提示词粘贴到 Qwen Code 中:
我正在学习模型蒸馏,需要你帮我完成一次 LoRA 微调训练。请按以下步骤执行,每一步都向我解释你在做什么、为什么这么做。
## 环境信息
- 基座模型路径:/mnt/workspace/model(Qwen3-0.6B,0.6B 参数)
- 训练数据:resources/4_1/train.jsonl(messages 格式,每条包含 system/user/assistant 三个角色)
- 框架:ms-swift(系统环境已安装,直接使用 swift 命令即可)
- GPU:A10(30GB 显存)
- 工作目录:/mnt/workspace/aliyun_acp_learning/大模型ACP认证教程/C4_交付上线/
- ⚠️ 不要激活 llm_learn 虚拟环境,不要运行 source activate。venv 中的 PyTorch 版本与系统 CUDA 不兼容,激活后 GPU 不可用。直接使用系统默认环境。
## 重要约束
- 不要读取 notebook 文件(.ipynb)来查看已有的训练命令或参数。请根据你自己对数据的分析来独立决定参数值。
- 不要运行 swift --version(会报错)、不要运行 swift sft --help(输出不完整,没有参考价值)。
- 不要访问 GitHub 或其他外部网站查文档(当前环境无法访问外网)。
- 训练参数的决策依据应来自你对训练数据的实际分析(样本数、token 长度等),而非查阅文档。
## 请执行以下步骤
### 第 1 步:验证环境
- 确认当前没有激活任何虚拟环境(命令行提示符前不应有 `(llm_learn)` 等前缀)
- 验证 GPU 是否可用:运行 `python3 -c "import torch; print('GPU可用:', torch.cuda.is_available(), '| 设备数:', torch.cuda.device_count())"`
- 如果输出 False,检查是否误激活了虚拟环境,运行 `deactivate` 退出后重试
- **GPU 验证通过后才能继续下一步**
- 确认 swift 命令存在(运行 `which swift`,不要运行 swift --version)
- 切换到工作目录
- 确认基座模型文件存在
- 确认训练数据文件存在并统计样本条数
### 第 2 步:分析训练数据并决定训练参数
先对训练数据做以下分析(用 Python 脚本,不要用 swift 命令):
1. 统计总样本数
2. 读取 5-10 条样本,了解数据格式,向我解释 system/user/assistant 三个角色各自的内容
3. 用 tokenizer 计算每条样本的 token 长度分布(最小值、最大值、平均值、P95),代码示例:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/model", trust_remote_code=True)
# 对每条样本拼接 system+user+assistant 内容后 tokenize,统计长度
```
然后根据分析结果,为以下参数选择值,并向我解释每个参数的含义和你选择该值的理由:
- --lora_rank:LoRA 低秩矩阵维度。考虑因素:任务需要同时学习 5 个字段(intents/department/urgency/entities/route)的联合映射
- --learning_rate:学习率。考虑因素:数据规模和模型大小
- --num_train_epochs:训练轮次。考虑因素:数据量大小,轮次过多会过拟合
- --per_device_train_batch_size:每张 GPU 的批次大小。考虑因素:A10 显存 30GB,模型 0.6B 参数
- --max_length:最大序列长度。根据你上面统计的 token 长度 P95 来决定,留出一定余量即可
以下参数请固定使用这些值(用于确保生成 loss 曲线图和验证集评估):
--model /mnt/workspace/model
--model_type qwen3
--dataset resources/4_1/train.jsonl
--split_dataset_ratio 0.1
--eval_steps 20
--save_strategy steps
--save_steps 20
### 第 3 步:启动训练
⚠️ 训练约需 10-15 分钟。必须以后台方式运行,否则日志持续输出会导致终端闪屏,且命令可能因超时被终止。
按以下方式启动:
```bash
cd /mnt/workspace/aliyun_acp_learning/大模型ACP认证教程/C4_交付上线/
nohup swift sft [你决定的参数] > /tmp/swift_train.log 2>&1 &
echo "训练 PID: $!"
```
启动后,每隔 2-3 分钟运行 `tail -20 /tmp/swift_train.log` 查看最新日志,向我汇报:
- 当前训练进度(第几个 epoch、第几步)
- loss 的变化趋势(是否在正常下降)
- 如果出现异常(如 loss 突然飙升),提醒我并建议处理方式
判断训练是否结束:运行 `pgrep -f "swift sft"` 检查进程是否还在。进程消失说明训练已完成,此时再查看日志末尾确认最终状态。
### 第 4 步:训练完成后的分析
训练结束后:
1. 找到输出目录(output/model/ 下最新的目录)
2. 在该目录的 images/ 子目录下找到 loss 曲线图片
3. 分别展示 train/loss 和 eval/loss 的曲线图
4. 对曲线进行解读:
- 训练是否正常收敛?
- 有没有过拟合迹象?(eval/loss 是否出现上升)
- 最终的 loss 值是否合理?
5. 根据 loss 曲线给出你的判断:这次训练算成功吗?
### 第 5 步:准备下一步
- 告诉我合并后的模型会保存在哪里
- 简要说明接下来可以做什么(合并 LoRA 参数、评测效果)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
如果你选择使用 Qwen Code 完成训练,可以跳过下方代码 cell。如果你更习惯手动执行,直接运行下方命令即可,参数含义已在上文说明。
# LoRA 微调 Qwen3-0.6B(A10 GPU 约 10 分钟)
!swift sft \
--model /mnt/workspace/model \
--model_type qwen3 \
--dataset resources/4_1/train.jsonl \
--split_dataset_ratio 0.1 \
--learning_rate 5e-5 \
--lora_rank 8 \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--max_length 512 \
--eval_steps 20 \
--save_strategy steps \
--save_steps 20
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6.3 训练结果观察
训练完成后,ms-swift 会在训练日志末尾打印输出目录路径(images_dir),例如:
images_dir: /mnt/workspace/aliyun_acp_learning/大模型ACP认证教程/C4_交付上线/output/model/vx-xxxxxxxx-xxxxxx/images
其中 vx-xxxxxxxx-xxxxxx 是 ms-swift 自动生成的训练目录名(格式 v{版本}-{YYYYMMDD}-{HHMMSS}),每次训练的目录名不同,以你实际看到的为准。
有三种方式查看 loss 变化:
- 曲线图(最直观):在 DSW 文件浏览器中打开上述
images/目录,双击 loss 曲线图即可查看。 - TensorBoard 日志:同一训练目录下的
runs/子目录保存了 TensorBoard 日志。在 Terminal 中运行tensorboard --logdir output/model/可启动交互式面板。 - 训练日志:上方 cell 的输出中包含每一步的 loss 值,可以直接观察数字是否在下降。
根据 Section 5.3 的判断标准:训练损失和验证损失都持续下降说明模型在正常学习;验证损失开始上升则说明过拟合,需要减少训练轮次或增加数据。
# 6.4 合并 LoRA 参数
训练完成后,将 LoRA 参数与基础模型合并,生成一个独立的完整模型。下方代码会自动查找最新的 checkpoint 并执行合并。合并后的模型保存在 checkpoint-xxx-merged 目录中。
import glob
# 自动查找最新的 LoRA checkpoint(排除已合并的目录)
all_ckpts = sorted(glob.glob("output/model/*/checkpoint-*"))
ckpts = [c for c in all_ckpts if not c.endswith('-merged')]
if not ckpts:
print("未找到 checkpoint,请先运行 Section 6.2 的训练命令。")
else:
latest_ckpt = ckpts[-1]
print(f"找到 checkpoint:{latest_ckpt}")
print(f"开始合并 LoRA 参数...")
!swift export --adapters {latest_ckpt} --merge_lora true
2
3
4
5
6
7
8
9
10
11
12
13
# 6.5 常见问题
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 训练损失不降 | 学习率太高 | 降低 learning_rate 到 1e-5 |
| 验证损失上升 | 过拟合 | 减少 epochs 或增加训练数据 |
| JSON 格式崩坏 | 训练数据中 JSON 格式不统一 | 检查数据格式一致性 |
| 意图遗漏 | 多意图样本占比不足 | 确保训练集中多意图样本 ≥ 30% |
| 显存不足 | batch_size 或 max_length 太大 | 减小 batch_size 到 4 |
# 7. 蒸馏效果评测
训练完成后,评测蒸馏模型的表现,并与基座模型和教师模型对比。
💡 小贴士:如果你没有在 PAI-DSW 上训练,可以跳过代码执行,直接查看下方的预生成评测结果。
import glob
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
# 释放基座模型的显存(如果还在内存中)
if 'base_model' in dir():
del base_model
torch.cuda.empty_cache()
print("已释放基座模型显存")
# 自动查找合并后的 checkpoint 路径
merged_dirs = sorted(glob.glob("output/model/*/checkpoint-*-merged"))
if not merged_dirs:
print("未找到合并后的 checkpoint,请先运行 Section 6.4 的 swift export 命令。")
else:
student_path = merged_dirs[-1] # 取最新的
print(f"加载蒸馏模型:{student_path}")
student_tokenizer = AutoTokenizer.from_pretrained(student_path, trust_remote_code=True)
student_model = AutoModelForCausalLM.from_pretrained(
student_path, dtype=torch.float16, device_map='auto',
trust_remote_code=True
)
# 加载测试数据(如果重启过内核)
if 'test_data' not in dir():
import json
test_data = []
with open("resources/4_1/test_30.jsonl", "r", encoding="utf-8") as f:
for line in f:
test_data.append(json.loads(line))
print(f"正在评测蒸馏模型({len(test_data)} 条测试样本)...")
student_preds = []
for i, item in enumerate(test_data):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": item["query"]}
]
text = student_tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
enable_thinking=False
)
inputs = student_tokenizer(text, return_tensors="pt").to(student_model.device)
with torch.no_grad():
outputs = student_model.generate(
**inputs, max_new_tokens=512,
temperature=0.1, do_sample=True
)
response = student_tokenizer.decode(
outputs[0][inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
parsed = validate_label(response)
student_preds.append({"raw": response, "parsed": parsed})
status = "OK" if parsed else "FAIL"
print(f" [{i+1}/{len(test_data)}] {status} | {item['query'][:50]}...")
ground_truths = [item["ground_truth"] for item in test_data]
student_results = evaluate_predictions(student_preds, ground_truths)
print_eval_results(student_results, "蒸馏模型")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 渲染三方对比表格
# 如果已运行所有评测代码,使用实际结果;否则显示预生成参考数据
from IPython.display import display, Markdown
if 'base_results' in dir() and 'teacher_results' in dir() and 'student_results' in dir():
print("### 7.1 三方对比\n")
render_comparison_table(
[base_results, teacher_results, student_results],
["基座模型 (0.6B)", "教师模型 (qwen3.6-plus)", "蒸馏模型 (0.6B)"]
)
else:
display(Markdown("""### 7.1 三方对比
> 以下为预生成参考数据,运行 Section 4 和 Section 7 的评测代码后将显示实际结果。
| 指标 | 基座模型 (0.6B) | 教师模型 (qwen3.6-plus) | 蒸馏模型 (0.6B) |
| --- | --- | --- | --- |
| JSON 合规率 | 15/31 (48%) | 31/31 (100%) | 31/31 (100%) |
| intents F1 | 23.7% | 83.9% | 70.4% |
| route 准确率 | 5/31 (16%) | 28/31 (90%) | 24/31 (77%) |"""))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
蒸馏最立竿见影的收益是 JSON 格式问题的彻底解决:蒸馏后模型的输出几乎都能正常解析为合法 JSON,说明模型已经稳定掌握了输出格式。意图识别 F1 和路由准确率也有大幅提升,模型确实学到了教师的判断逻辑。路由准确率的提升对生产系统意义最大,它直接决定了请求能否被分发到正确的处理模块。蒸馏模型还没有完全追平教师,但已经接近 0.6B 参数量在这个任务上的能力天花板。如果需要更高精度,可以换用 1.5B 或 4B 模型做学生。
# 7.2 蒸馏的能力边界
蒸馏不是万能的。有些情况蒸馏后仍然容易出错:意图间有依赖关系的多意图(比如"请假后自动调整考勤",两个意图之间有因果关系,0.6B 模型难以捕捉);训练集未覆盖的罕见组合(比如"IT支持 + 差旅申请"的组合,如果训练数据中没有类似样本,模型会猜错);以及极度含糊的表达(比如"那个事情帮我处理一下",缺少任何可以抓取的信号)。
0.6B 模型适合"高频、固定域、单步判断"的专用任务,不是小号通用助手。它在系统中的角色是预处理器,不是全能替代品。
# 7.3 你的任务适合蒸馏吗
在投入时间和算力之前,先做一个快速判断。
适合蒸馏的任务特征:
- 输出格式固定,可以用规则自动校验(如 JSON schema、分类标签)
- 不依赖实时更新的外部知识,只看输入文本本身
- 调用频次高,属于系统的高频调用链路
- 教师模型表现稳定,错误有明确规律(比如某类意图总是识别错,而非随机出错)
不适合蒸馏的场景及替代方案:
| 场景 | 原因 | 替代方案 |
|---|---|---|
| 需要实时知识更新(如政策查询) | 蒸馏模型的知识固化在训练时刻 | 蒸馏做意图识别 + RAG 提供最新知识 |
| 需要多步推理(如数学证明) | 小模型推理能力有限 | 保留大模型,或用推理压缩蒸馏 |
| 教师模型本身表现不稳定 | 学生无法超过教师的上限 | 先优化教师的 prompt 或换更强的教师 |
| 基座模型已能基本完成需求 | 提升空间有限,投入产出不划算 | 权衡投入产出比,考虑直接使用基座模型 |
快速验证流程:正式训练前,建议先用少量样本做一次快速实验。如果基座模型已经能基本完成需求,或微调后提升不明显,可以重新评估任务选择,或调整优化策略(比如增加训练数据的多样性、调整教师 prompt)。
数据分布与生产不匹配也是常见陷阱。合成数据的表达模式可能与真实用户的提问方式存在差异,导致模型在生产环境中效果下降。可以适当混入真实数据,帮助模型适应实际分布。
# 8. 成本收益分析
蒸馏的最终目的是降低生产环境的推理成本。我们来算一笔账。
# 8.1 成本对比
假设一个典型的请求理解场景:日均 2 万次请求,平均每条输入 200 token(system prompt + 员工提问),输出 100 token(JSON 工单)。
方案 A:大模型 API(qwen3.6-plus)
DashScope 按 token 计费,输入 2 元/百万 token,输出 12 元/百万 token。按上述用量计算:
- 每日输入成本:2 万 × 200 token ÷ 100 万 × 2 元 = 8 元
- 每日输出成本:2 万 × 100 token ÷ 100 万 × 12 元 = 24 元
- 日成本约 32 元,月成本约 960 元
API 成本与请求量严格线性:请求量翻倍,成本翻倍。
方案 B:蒸馏小模型 GPU 部署
以 PAI-EAS 的 T4 实例(4GB 显存)为例,按量付费 3.6 元/小时。0.6B 模型 FP16 权重约 1.2GB,4GB 显存足够运行。GPU 按运行时长计费,不按 token 计费,因此成本取决于服务在线时长:
| 部署方式 | 日成本 | 月成本 | 说明 |
|---|---|---|---|
| 工作时间运行(8 小时) | 28.8 元 | 864 元 | 利用 EAS 定时伸缩,仅工作时段保持实例 |
| 24 小时常驻 | 86.4 元 | 2592 元 | 服务全天在线,适合全球化/跨时区场景 |
# 8.2 盈亏平衡点
单次 API 调用成本约 0.0016 元。在不同部署模式下,盈亏平衡点差异很大:
- 工作时间运行(8 小时):GPU 日成本 28.8 元,盈亏平衡在日均约 1.8 万次请求。日均 2 万次时,GPU(864 元/月)已比 API(960 元/月)便宜约 10%。
- 24 小时常驻:GPU 日成本 86.4 元,需要日均约 5.4 万次请求才能和 API 打平。
请求量越大,GPU 优势越明显。日均 10 万次时,API 月成本约 4800 元,而工作时间运行 GPU 仍只需 864 元。
但成本只是决策的一个维度。蒸馏在以下场景中即使推理成本不占优,仍然值得考虑:
- 延迟敏感:本地推理约 50ms,API 调用约 500ms,10 倍延迟差距在实时系统中影响显著
- 数据安全:员工的提问可能涉及内部人事信息,走外部 API 存在数据出域风险
- 离线场景:内网部署、无外网环境等无法调用云端 API 的场景
- 稳定性:不依赖外部服务的可用性和限流策略
# 8.3 部署决策
什么时候该用蒸馏,什么时候不该?
| 场景特征 | 推荐方案 | 原因 |
|---|---|---|
| 高频、固定域、结构化输出 | 蒸馏 | 小模型推理成本低,效果接近大模型 |
| 知识每天更新 | RAG | 蒸馏模型无法自动适应新知识 |
| 需要复杂推理 | 保留大模型 | 小模型推理能力有限 |
| 蒸馏 + RAG 混合 | 混合架构 | 蒸馏做预处理,RAG 做知识查询 |
在我们的答疑机器人系统中,蒸馏模型的角色是预处理器:快速将自然语言转为结构化工单,然后根据路由决策分发给不同的后端处理模块。混合架构下的处理流程如下:
员工提问:"调岗到 AI 部门需要什么条件?"
↓
[蒸馏模型] 结构化理解 → {intents: ["制度咨询"], department: "HR", route: "rag_query"}
↓
[RAG 系统] 用提取的意图和部门查询知识库 → 检索到调岗政策文档
↓
[大模型] 基于检索结果生成最终回复(可选)
2
3
4
5
6
7
蒸馏模型保证结构化提取的稳定性和低延迟,RAG 保证知识的实时性(政策变更无需重新训练),大模型负责需要复杂推理的最终回答。三者各司其职。
⚠️ 合规提醒:如果你使用开源模型(如 Qwen 系列,Apache 2.0 协议)作为教师,蒸馏产出的学生模型可以自由商用。但部分商业模型(如 GPT-4、Claude)的服务条款明确禁止用其输出训练竞品模型,使用前请确认合规性。
# 本节小结
本节课程围绕"请求理解"这个生产场景,完整走通了数据合成蒸馏的全流程。蒸馏的本质是把大模型的判断能力固化到小模型的权重中,与微调的区别在于训练数据来源不同:蒸馏用教师模型生成,微调用人工标注。
在数据合成阶段,我们通过"生成多样化查询 → 教师模型标注 → 质量过滤 → 格式化训练数据"的流水线构建了高质量训练集,数据质量比数量更重要。在训练阶段,我们在 PAI-DSW 上使用 ms-swift 框架以 LoRA 方法训练 Qwen3-0.6B 模型,LoRA 只训练 0.4% 的参数,保留了模型 97% 的基础能力。最终通过 JSON 合规率、意图 F1、路由准确率三项指标量化验证了蒸馏效果:蒸馏模型从基座模型的"几乎不可用"大幅提升到接近教师模型的水平。
蒸馏不是替代 RAG,而是把系统中"可预测的、高频的、结构化的"工作环节交给专用小模型。它和 RAG、Agent 是互补关系,各自负责系统的不同环节。
# 进一步学习
- 阿里云 PAI 平台:基于 PAI-DSW 微调 Qwen3 模型 (opens new window)
- ms-swift 框架文档 (opens new window)
- LoRA 原始论文 (opens new window)
# 🔥 课后小测验
# 🔍 单选题
蒸馏和微调的核心区别是什么? - A. 蒸馏不需要训练,微调需要训练
- B. 蒸馏的训练数据由教师模型生成,微调的训练数据由人工标注
- C. 蒸馏只能用于小模型,微调可以用于任何模型
- D. 蒸馏需要 GPU,微调不需要 GPU
【点击查看答案】
✅ 参考答案:B
📝 解析:
蒸馏和微调的训练流程(SFT)本身几乎相同,核心区别在于训练数据的来源。蒸馏使用教师模型的输出作为训练数据,微调使用人工标注的数据。两者都需要 GPU 进行训练,都可以用于不同规模的模型。
# 🔍 单选题
以下哪种任务最适合蒸馏到 0.6B 小模型? - A. 撰写 5000 字的技术分析报告
- B. 多轮对话式的客户投诉处理
- C. 从用户输入中提取结构化的意图和实体
- D. 根据上下文生成创意营销文案
【点击查看答案】
✅ 参考答案:C
📝 解析:
0.6B 模型的能力边界决定了它适合"高频、固定域、单步判断"的任务。结构化提取(意图识别、实体抽取、分类)正是这类任务的典型代表,输出格式固定、不需要外部知识、不需要多步推理。长文本生成、多轮对话、创意写作都超出了 0.6B 模型的能力范围。
# 🔍 单选题
为什么不能随意使用商业大模型(如 GPT-4)作为蒸馏的教师模型? - A. GPT-4 的输出质量不够高
- B. GPT-4 不支持 JSON 格式输出
- C. 部分商业模型的服务条款禁止用其输出训练竞品模型
- D. 商业模型的 API 调用速度太慢
【点击查看答案】
✅ 参考答案:C
📝 解析:
这是一个合规问题,而非技术问题。部分商业模型(如 OpenAI、Anthropic 的模型)在服务条款中明确禁止使用其输出来训练竞品模型。使用开源模型(如 Qwen 系列,Apache 2.0 协议)作为教师则不存在此限制。在实施蒸馏项目前,务必确认教师模型的许可条款。
# ✉️ 评价反馈
感谢你学习阿里云大模型ACP认证课程,如果你觉得课程有哪里写得好、哪里写得不好,期待你通过问卷提交评价和反馈 (opens new window)。
你的批评和鼓励都是我们前进的动力。