
 Qwen Code 实践
Qwen Code 实践
# 3.7 Qwen Code 实践——掌握 Coding Agent 的日常工作方式
# 🚄 前言
在 3.5 中,你学会了如何设计 Skill——将经验封装为可复用的指令集,并通过评测驱动优化不断改进它。回头看整个第三章的脉络:从 Function Calling 和 ReAct 循环(3.1),到任务规划(3.2),到 SubAgent 协作(3.3),到记忆管理(3.4),再到 Skill 系统(3.5),你已经掌握了构建 Agent 的全部核心概念。
但这是否意味着你每次都需要从零搭建一个 Agent?当然不是。就像你学过了发动机原理,并不意味着你要自己造一辆车——你应该去开一辆好车。Qwen Code 就是这样一辆"好车":它把你学过的 Function Calling、ReAct、规划、SubAgent、记忆、Skill 全部集成在一个成熟的工具中,让你能直接用自然语言驱动它完成真实的开发任务。
这节课的目标是:让你把 Qwen Code 当作日常开发工具来使用,在这个过程中,你会发现 3.1 到 3.5 学过的每一个概念都有对应的实际操作。更重要的是,你将建立一套可重复的工作方法,让 Coding Agent 真正成为你的生产力工具,而不仅仅是一个"试过一次觉得挺有趣"的体验。
# 🍁 课程目标
学完本节课程后,你将能够:
- 说出 Qwen Code 中至少 5 个行为分别对应 3.1—3.5 中的哪个 Agent 概念,并解释其原理
- 使用 Explore → Plan → Code → Commit 四阶段工作流,独立完成一个完整的功能开发任务
- 使用
/context命令监控上下文使用情况,在合适的时机使用/compress或/clear管理上下文 - 为答疑机器人项目创建并维护 QWEN.md 项目配置文件
- 配置自定义命令、MCP 和 Skill 三种扩展机制,并根据需求选择合适的机制
- 综合运用所有机制,使用 Qwen Code 独立完成 Gradio Web UI 的构建
# 安装 Qwen Code
Qwen Code 是通义千问团队开源的终端 AI 智能体,能理解代码库、调用工具、自主完成编程任务。本节课全程在 Qwen Code 中操作,请先完成安装:
一键安装 Qwen-Code(约 1 分钟), 安装完成后请到终端中输入 qwen 启动,不要在 Notebook 中运行
1 |
安装完成后,打开一个新的终端窗口(在 DSW 中点击顶部菜单 Terminal,然后点击右上角的 ![]() 图标),输入
图标),输入 qwen 启动,按以下三步完成登录:
- 选择模型服务提供方,选默认的 Qwen 即可
- 选择 OAuth Login,Qwen-Code 会生成一个授权链接
- 在浏览器中打开链接,登录通义千问账号后点击确定授权
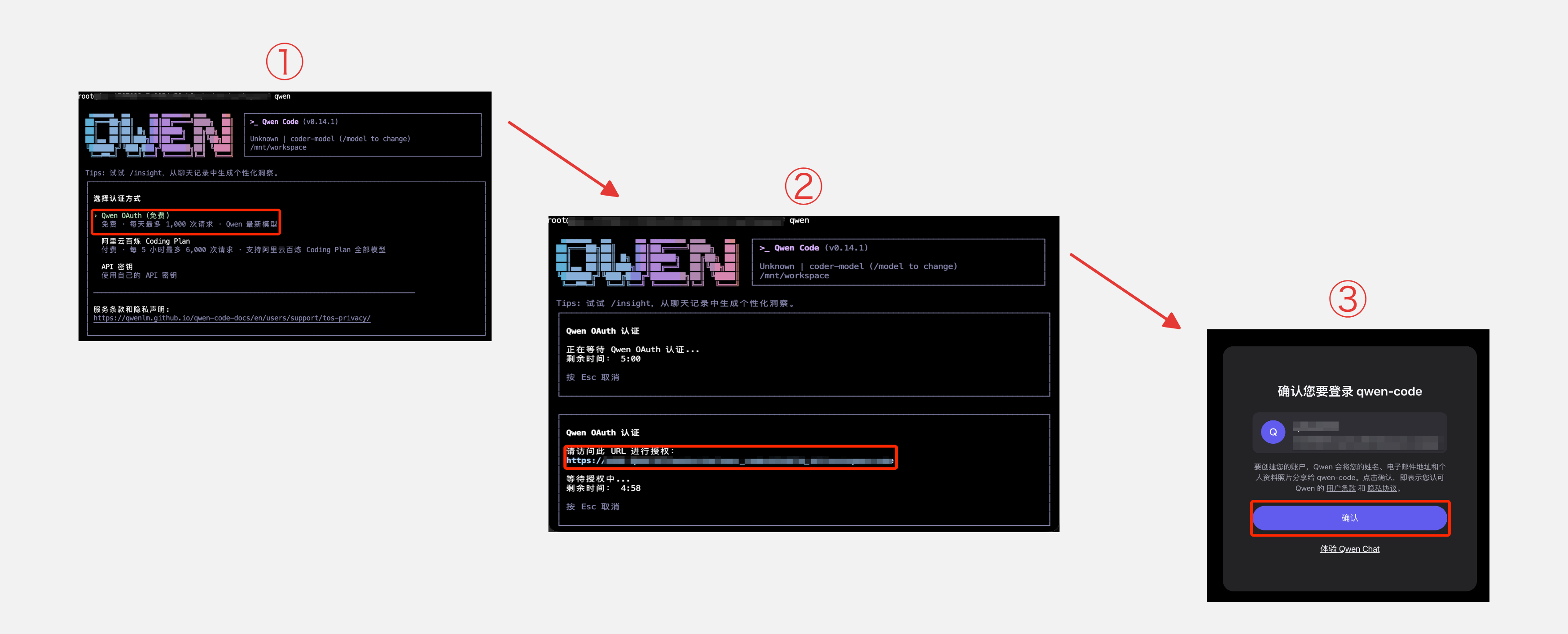
授权完成后终端会自动完成登录,通过 OAuth 方式每天可免费使用 1,000 次请求。更多配置选项可参考 Qwen-Code 官方文档。
# 1 从概念到工具:Qwen Code 如何集成你学过的一切
登录成功后,进入课程项目目录并启动 Qwen Code:
cd /path/to/大模型ACP认证教程/
qwen
2
启动后,输入一句话:
帮我看一下 course_core/chatbot/ 目录的整体结构,告诉我每个文件的职责
观察 Qwen Code 的响应过程。你会看到它先读取文件、分析代码,然后给出结构化的回答。这个过程看似简单,背后涉及你在前几节学过的多个概念:
| 你观察到的 Qwen Code 行为 | 对应的 Agent 概念(章节) | 本质 |
|---|---|---|
| 自动调用文件读取、代码搜索等工具 | Function Calling(3.1) | 模型输出结构化的工具调用指令,而非直接回答 |
| 读取结果 → 思考 → 再读取 → 再思考,循环多轮 | ReAct 循环(3.1) | 交替执行推理和行动,直到任务完成 |
| 使用 Plan Mode 时先列出步骤再逐步执行 | Plan & Execute(3.2) | 先生成完整计划,再按步骤执行 |
| 复杂任务中自动拆分子任务并行处理 | SubAgent(3.3) | 主 Agent 派遣临时子 Agent 处理独立子任务 |
| 长对话中能记住你之前的偏好和指令 | 会话记忆(3.4) | 短期记忆存储在上下文窗口中 |
| QWEN.md 文件中的项目配置持久生效 | 持久记忆(3.4) | 将关键信息写入文件,跨会话保留 |
| 按需加载 Skill 执行特定工作流 | Skill(3.5) | 预定义的指令集,Agent 根据任务自动判断是否加载 |
这张表的意义不在于记忆对应关系,而在于让你确认一件事:Qwen Code 不是一个独立的新知识点,而是你已经学过的所有概念的一个工程实现。 当你理解了这一点,后面学习它的每一个功能时,你都可以追问"这对应的是哪个 Agent 概念",而不是把它当作一个需要死记硬背的工具手册。
# 2 核心工作流:Explore → Plan → Code → Commit
# 2.1 为什么需要工作流
现在给你一个真实的开发任务:
为答疑机器人添加"对话历史导出为 JSON"功能——用户在对话结束后,可以将本次对话的所有问答记录导出为一个结构化的 JSON 文件,包含时间戳、用户问题、机器人回答和引用来源。
如果你直接把这段需求丢给 Qwen Code:
帮我实现对话历史导出为 JSON 的功能
它大概率会立刻开始写代码——在 agent.py 里加一个导出函数,或者新建一个 export.py 文件。代码可能能跑,但你会遇到这些问题:
- 它可能不知道你的对话历史存储在哪里,凭猜测选择了错误的数据结构
- 它可能和现有的
rag.py中的引用来源格式不兼容 - 它生成的代码没有测试,你也不确定是否正确
- 它一次性改了多个文件,你很难审查每个改动是否合理
这不是 Qwen Code 的能力问题,而是你没有给它足够的上下文和结构化的指引。这和 3.2 中学过的道理一样:没有规划的执行,效率远低于先规划再执行。
接下来,你将用 Explore → Plan → Code → Commit(EPCC)四个阶段完成同一个任务。完成后,你自己对比两种方式的差异。
# 2.2 Explore:先理解再动手
Explore 阶段的目标只有一个:让 Agent(也让你自己)充分理解当前代码的状态,再决定怎么改。
在 Qwen Code 中输入以下提示:
我要给答疑机器人添加"对话历史导出为 JSON"的功能。在开始之前,请先帮我搞清楚以下问题:
1. 当前对话历史是怎么存储的?在哪个文件、什么数据结构?
2. rag.py 中的引用来源(source)字段的格式是什么样的?
3. 现有代码中有没有和导出相关的功能可以复用?
请只分析,不要写任何代码。
2
3
4
5
注意最后一句话——"请只分析,不要写任何代码"。这是 Explore 阶段的关键约束。如果不加这句,Qwen Code 的 ReAct 循环会在分析完成后自然地进入"Action"阶段开始写代码,这不是你现在想要的。
观察 Qwen Code 的响应。它会使用文件读取工具打开 agent.py、rag.py 等文件,搜索关键词(如 history、message、source),然后给你一份结构化的分析报告。
读完它的分析后,你可能会发现一些自己之前没注意到的细节——比如对话历史可能存储在 AgentScope 的消息列表中,而不是一个简单的 Python 列表;引用来源的格式可能包含文件路径和相关段落,需要特殊处理。
这就是 Explore 的价值:它让你在动手之前,建立了对现状的准确认知。 很多开发者会跳过这一步,直接凭印象开始写代码,然后在写到一半时才发现某个假设是错的,不得不推翻重来。用 Agent 做 Explore 的成本很低——几十秒的分析时间,换来的是对项目状态的清晰理解。
# 2.3 Plan:用 Plan Mode 生成方案
现在你对代码现状有了清晰的认知,下一步是生成一个具体的实现方案。这里要用到 Qwen Code 的 Plan Mode(规划模式)。
Qwen Code 有四种审批模式(Approval Mode),通过按 Shift+Tab 在它们之间循环切换:
| 模式 | 行为 | 适用场景 |
|---|---|---|
| plan | 只分析和规划,不修改文件,不执行命令 | 审查方案、理解代码 |
| default | 修改文件或执行命令前需要你确认 | 日常开发(推荐默认) |
| auto-edit | 自动批准文件修改,命令仍需确认 | 大量代码修改场景 |
| yolo | 自动批准所有操作 | 充分信任 Agent 的场景 |
你也可以用斜杠命令直接切换:
/approval-mode plan
切换到 Plan Mode 后,输入以下提示:
基于刚才的分析结果,请为"对话历史导出为 JSON"功能制定实现方案。要求:
1. 导出的 JSON 包含字段:timestamp, user_query, bot_response, sources
2. 提供一个 export_history(chat_history, output_path) 函数
3. 在现有的对话流程中加入导出入口
4. 包含基本的单元测试
请列出具体步骤,每一步说明改哪个文件、改什么内容。
2
3
4
5
6
在 Plan Mode 下,Qwen Code 只做规划、不做执行——这正是你在 3.2 中学过的 Plan & Execute 模式中"Plan"阶段的直接体现。它会生成一个分步方案,列出需要创建或修改的文件、每一步的具体内容。
在 Plan Mode 下,你的核心工作是审查方案,而不是被动接受。 关注这几个问题:
- 步骤粒度是否合适? 每一步是否只做一件事?如果某步过于笼统,要求它拆分。
- 依赖关系是否正确? 比如新建
export.py必须在修改agent.py之前完成。 - 有没有遗漏? 比如是否需要处理对话历史中包含 RAG 引用来源的情况?
如果你对方案有修改意见,直接在 Plan Mode 中反馈:
方案需要调整:
- 步骤 1 中,sources 字段应该从 rag.py 的检索结果中提取,不是从消息内容里解析
- 增加一步:导出前先验证 chat_history 的格式是否符合预期
2
3
Qwen Code 会根据你的反馈更新方案。你可以反复迭代,直到方案满意。这个过程和 3.2 中讲的"计划不是一次性生成的,而是需要人类审查和调整"完全一致。
确认方案后,切换回 default 模式开始执行:
/approval-mode default
# 2.4 Code:执行并审查
回到 default 模式后,告诉 Qwen Code 开始执行方案:
请按照刚才确认的方案开始实现。从第 1 步开始,每完成一步先停下来让我确认。
💡 预测练习:如果你不加"每完成一步先停下来让我确认"这个约束,在 default 模式下 Agent 会怎么执行?它会一口气做完所有步骤吗?
想一想再往下看:在 default 模式下,Agent 每次修改文件或执行命令前都会暂停等你确认——所以即使你不加这个约束,它也不会完全"失控"。但问题在于,它会把多个步骤的修改混在一起提交给你确认,你很难分辨哪些改动属于哪个步骤。加上"每完成一步先停下来"的约束,等于是在步骤之间增加了一个汇报节点,让你在更高的粒度上审查进展。
对于简单任务不加这个约束没有问题,但对于涉及多个文件修改的任务,逐步确认能让你在问题扩散之前发现并纠正错误。
当 Qwen Code 完成第一步后,它会显示生成的代码和文件变更。此时你需要做两件事:
第一,审查代码内容。 不是逐行阅读,而是关注几个关键点:函数签名是否和方案中约定的一致?数据处理逻辑是否正确?有没有硬编码的值应该改成参数?
第二,确认文件变动。 你可以让 Qwen Code 显示当前的改动:
显示目前所有文件的 diff
如果某处代码有问题,直接说:
export_history 函数中,timestamp 应该用 ISO 8601 格式,不是 Unix 时间戳。请修改。
如果需要中断当前操作——比如 Qwen Code 正在做一个你不想要的改动——按 Esc 键可以立即停止。你随时可以打断 Agent,调整方向后再继续。
确认第一步无误后,让它继续:
第 1 步确认通过,请继续第 2 步。
重复这个过程,直到所有步骤完成。
# 2.5 Commit:验证并提交
所有代码写完了,但在提交之前,你需要验证它确实能正常工作。让 Qwen Code 帮你执行测试:
运行 tests/test_export.py 中的测试,如果有失败的测试,分析原因并修复。
这个指令利用了 ReAct 循环的特性——Qwen Code 会运行测试、观察结果、分析失败原因、修改代码、再次运行测试,直到所有测试通过。
测试通过后,让 Agent 审查自己的改动。这是一种低成本的质量保障:
请审查你刚才的所有代码改动,找出潜在的问题。
确认无误后,生成提交:
所有测试通过,审查无问题。请生成 git commit message 并提交。
回顾整个过程:Explore 让你理解了现状,Plan 让你确认了方向,Code 让你逐步实现并审查,Commit 让你验证并形成可追溯的记录。 这四个阶段不是凭空设计的流程,而是经过大量实践验证的、使用 Coding Agent 最高效的协作方式。在后续的开发中你会反复使用它。
# 3 审批模式与上下文管理
上一节你已经在实践中使用了 Plan Mode。这一节深入讲解 Qwen Code 的审批模式和上下文管理机制——它们共同决定了 Agent 的"自主程度"和"持久工作能力"。
# 3.1 四种审批模式的选择
在 2.3 节中你接触了 Plan Mode(规划模式),它是 Qwen Code 四种审批模式中的一种。按 Shift+Tab 可以在四种模式之间循环切换。它们的区别在于Agent 的自主权大小:
| 模式 | Agent 能自主做什么 | 你需要做什么 | 适用场景 |
|---|---|---|---|
| plan | 只读——分析代码、搜索信息 | 审查 Agent 的分析和方案 | 代码理解、方案设计 |
| default | 读+提议——生成代码但等你确认 | 逐个确认文件修改和命令执行 | 日常开发(推荐) |
| auto-edit | 读+写——自动修改文件 | 只确认命令执行 | 批量修改(如统一添加 docstring) |
| yolo | 全自主——所有操作自动执行 | 事后审查结果 | 你对 Agent 有充分信任的简单任务 |
四种模式的使用原则是最小权限:给 Agent 刚好够完成当前任务的自主权,不多不少。刚开始使用时,建议始终保持 default 模式。当你积累了足够的信任——知道 Agent 在哪些任务上稳定可靠——再考虑在特定场景下放宽权限。
💡 小贴士:你在 3.2 学过"自主性更高不等于更好"。这个原则在审批模式选择上同样适用。yolo 模式看起来最高效(不需要你确认任何操作),但如果 Agent 犯错,你可能要花更多时间排查和回滚。
# 3.2 上下文窗口:Agent 的工作台
在 3.4 学习记忆机制时,你已经知道 Agent 的短期记忆存储在上下文窗口中。现在来看这个概念在 Qwen Code 中的具体表现。
Qwen Code 的上下文窗口大小为 256K Token(约等于 20 万字中文文本)。乍看之下足够大——但在实际使用中,它消耗得比你想象的要快。原因是上下文窗口中存储的不仅仅是你输入的提示和 Agent 的回答,还包括:
- 每一次文件读取的完整内容
- 每一次代码搜索的结果
- Agent 的思考过程
- 工具调用的请求和返回值
你可以把上下文窗口想象成一张固定大小的工作台。每当你让 Qwen Code 读一个文件,就相当于把一份文档摊在台面上;每做一次分析,就相当于铺开一张草稿纸。台面空间是有限的——当所有空间被占满时,最早放上去的文档会被"推落"到桌下(即被丢弃)。
在 Qwen Code 中输入 /context,你会看到当前会话的上下文使用详情,包括已使用的 Token 数量和各部分的占比。如果你跟着第 2 节做完了整个"对话历史导出"任务,此时的上下文使用量可能已经达到 30%—50%。
这意味着:在一个过长的会话中,Qwen Code 可能会"忘记"早期的对话内容和分析结果。 这不是 Bug,而是上下文窗口的固有限制。理解了这一点,你就明白为什么需要主动管理上下文。
# 3.3 /compress 与 /clear:管理上下文
Qwen Code 提供了两个命令来管理上下文空间:
/compress(别名 /summarize)——压缩上下文。执行后,Qwen Code 会对当前会话的内容生成一个滚动摘要(Rolling Summary),只保留关键信息,释放大量空间。你在 3.4 中学过记忆的"摘要压缩"策略,/compress 就是它的实际应用。
💡 预测练习:如果你在
/compress之后让 Agent 引用压缩前讨论过的某个具体函数参数名(比如"刚才分析的export_history的第二个参数叫什么?"),它还能准确回答吗?想一想再验证:大概率不能。
/compress保留的是关键决策和结论的摘要,具体的参数名、变量名这类细节通常会在压缩中丢失。这就是为什么在压缩前,你应该把后续需要引用的关键细节写入 QWEN.md 或直接记在别处。
试一下:先运行 /context 记录当前 Token 使用量,然后运行 /compress,再次运行 /context 对比压缩前后的变化。你会看到显著下降。但要注意:压缩是有信息损失的。 细节性的内容(比如某个函数的具体参数名、某次讨论中的具体结论)可能在压缩后丢失。如果后续还需要引用这些细节,你需要在压缩前手动记录——比如写入 QWEN.md,下一节会讲。
/clear——清空上下文。这相当于完全重置会话,所有对话历史、分析结果、已建立的上下文全部丢失。
两者的使用时机不同:
| 场景 | 推荐操作 | 原因 |
|---|---|---|
| 上下文使用超过 70%,但当前任务还没完成 | /compress | 保留核心上下文,释放空间继续工作 |
| 当前任务已完成,准备开始一个不相关的新任务 | /clear | 旧上下文对新任务没有价值,清空避免干扰 |
| Agent 的回答开始出现明显错误或前后矛盾 | /clear | 上下文可能已被过多信息污染,重新开始更高效 |
关键原则是:/compress 是在任务进行中节省空间的手段,/clear 是在任务之间划清界限的手段。
# 3.4 实用策略:什么时候该新开会话
理解了上下文管理后,一个自然的问题是:与其在一个会话中反复压缩,为什么不直接新开一个会话?
答案是:很多时候,新开会话确实是更好的选择。 以下三个信号提示你应该这样做:
任务边界清晰。 你完成了"对话历史导出"功能的开发,接下来要做一个完全不同的任务。这两个任务之间没有上下文依赖,新开会话可以让 Agent 以全部注意力聚焦在新任务上。
上下文使用超过 80%。 即使
/compress还能释放一些空间,但在高占用的上下文中,Agent 的注意力分配会变得不均匀——它可能过度关注最近的内容,而忽略早期的重要信息。Agent 开始"循环"或给出不一致的回答。 如果你发现 Qwen Code 反复尝试同一种方案,或者前后矛盾地建议修改某段代码,这通常意味着上下文已经变得混乱。
一个经过实践验证的节奏是:每天使用 5—10 个短会话,而不是 1 个长会话。 每个会话聚焦在一个具体任务上(一个功能、一个 Bug、一次重构),完成后提交代码,然后新开会话做下一个任务。
如果新会话中需要上一个会话的成果,不需要手动复述。Qwen Code 可以直接读取你已经提交到 Git 的代码、读取 QWEN.md 中的配置——这些持久化的信息会自然地成为新会话的上下文。真正需要跨会话传递的关键决策和约定,应该写入 QWEN.md,而不是依赖记忆。
# 4 项目配置:用 QWEN.md 建立持久记忆
在前面的练习中,你已经体验了 EPCC 工作流,也学会了用 /compress、/clear 管理单次会话的上下文。但有一个问题你可能已经注意到了:每次启动新会话,Agent 对你的项目一无所知。
你不得不反复告诉它:"这个项目用 LlamaIndex 0.12+ 搭建 RAG""API 调用走 DashScope 的 OpenAI 兼容接口""代码遵循 PEP 8 规范"。如果你在 3.4 节学过记忆体系的分类,会发现这正是操作习惯(Procedural Memory)的典型场景——不是某次对话的临时信息,而是跨会话始终成立的项目级知识。
问题很明确:Agent 的会话上下文在 /clear 或关闭终端后就消失了。你需要一种持久化的项目记忆机制,让 Agent 每次启动时自动加载这些背景知识。
# 4.1 什么是 QWEN.md
QWEN.md 是一个 Markdown 文件,放在项目根目录下,Agent 每次启动时自动读取并加入系统上下文。它是 Qwen Code 实现持久记忆的具体方式。
你可以手动创建这个文件,也可以让 Agent 帮你生成初始版本。在 Qwen Code 中运行:
/init
Agent 会扫描项目的目录结构、读取关键文件(如 requirements.txt、主要模块的代码),然后生成一份 QWEN.md 草稿。
但不要直接使用生成结果。 /init 生成的是 Agent 的"第一印象",它可能遗漏重要约束,也可能误判某些设计意图。你需要审阅并修改它,就像审查 Agent 生成的代码一样。
# 4.2 该写什么、不该写什么
一个常见的误区是把 QWEN.md 写成项目文档的复制品。QWEN.md 不是给人看的文档,它是给 Agent 的工作指令——只写那些"如果 Agent 不知道,就会反复犯错"的内容。
以答疑机器人项目为例,一份实用的 QWEN.md 大致如下:
# 答疑机器人项目
## 项目概述
公司内部答疑机器人,基于 RAG 架构,检索公司知识库回答员工问题。
## 技术栈
- 框架:LlamaIndex 0.12+(不要使用 LangChain)
- 大模型:通义千问(qwen-plus),通过 DashScope OpenAI 兼容接口调用
- Embedding:DashScope text-embedding-v2
- API Key 加载:统一使用 config/load_key.py,不要硬编码 API Key
## 代码结构
- chatbot/llm.py:基础大模型调用(invoke, invoke_with_stream_log)
- chatbot/rag.py:RAG 核心逻辑(indexing, create_query_engine, ask)
- chatbot/agent.py:Agent 创建(基于 AgentScope 的 ReActAgent)
- chatbot/evaluate.py:RAGAS 评测
- config/load_key.py:API Key 加载,读取 Key.json
## 代码规范
- 遵循 PEP 8
- 函数必须有 docstring,说明参数和返回值
- 新增模块需在此文件中更新代码结构说明
## 常见陷阱
- DashScope 的 base_url 是 https://dashscope.aliyuncs.com/compatible-mode/v1,不要用 OpenAI 默认地址
- LlamaIndex 0.12 的 import 路径已改为 llama_index.core,不要用旧版路径
- ✗ from llama_index import VectorStoreIndex
- ✓ from llama_index.core import VectorStoreIndex
- create_query_engine() 返回的 query_engine 支持流式输出,前端对接时注意处理 streaming_response
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
这份 QWEN.md 的每一条都对应一个 Agent 可能犯的具体错误。下面的表格帮你判断什么该写、什么不该写:
| 该写 | 不该写 |
|---|---|
| 技术栈和版本约束(LlamaIndex 0.12+) | 完整的 API 文档或使用教程 |
| 关键模块的职责和调用方式 | 每个函数的源码实现细节 |
| 代码规范(PEP 8、docstring 要求) | 通用的 Python 编程常识 |
| Agent 反复犯过的具体错误及修复方式 | 一次性的调试记录 |
| API 地址、认证方式等环境配置 | API Key 本身(安全风险) |
左列的共同特征是:Agent 不知道就会出错,且跨会话始终成立。右列要么太细碎(Agent 可以自己读代码),要么是安全风险(Key.json 的内容),要么是通用知识(Agent 本来就知道 PEP 8 是什么)。
QWEN.md 的总长度建议控制在 200 行以内。超过这个长度,它本身就会占用过多的上下文空间,挤占留给实际工作的容量。
# 4.3 三级配置层次
Qwen Code 支持三级配置层次:
| 层级 | 文件位置 | 作用范围 | 典型内容 |
|---|---|---|---|
| 全局 | ~/.qwen/QWEN.md | 所有项目 | 个人编码偏好、通用规范 |
| 项目 | 项目根目录 QWEN.md | 当前项目 | 技术栈、模块结构、项目约束 |
| 目录 | 子目录 QWEN.md | 特定目录 | 该模块的特殊规则 |
Agent 启动时,三级配置按"全局 → 项目 → 目录"的顺序加载并合并。更具体的配置优先级更高——如果全局配置写了"使用 4 空格缩进",但项目配置写了"使用 2 空格缩进",Agent 在该项目中会遵循 2 空格。
在答疑机器人项目中,一个实际的用法是:在 chatbot/ 目录下放一份目录级 QWEN.md,专门说明该目录下的模块调用关系和测试方式。这样,Agent 在 chatbot/ 目录中工作时,不仅知道项目全局约束,还知道这个目录的特殊规则。
# 4.4 让 QWEN.md 自我演进
QWEN.md 不是写一次就不动的。回忆 3.4 节的核心观点:面向失败写记忆——记忆系统最有价值的内容来自 Agent 犯过的错误。
举一个你可能遇到过的场景:你让 Agent 修改 rag.py,它生成的代码用了 from llama_index import VectorStoreIndex——这是 LlamaIndex 旧版的 import 路径,在 0.12+ 版本中会报 ModuleNotFoundError。你纠正了它,Agent 改对了。但下一次会话,同样的错误可能再次出现,因为上次的纠正只存在于已经 /clear 掉的会话记忆中。
正确的做法是:当你发现 Agent 反复犯同一类错误时,把修复方式写进 QWEN.md。 你甚至可以让 Agent 自己来做这件事:
请把 LlamaIndex 0.12 的 import 路径注意事项添加到 QWEN.md 的"常见陷阱"部分。
Agent 会修改 QWEN.md,下次启动时加载更新后的版本。这就形成了一个记忆演进闭环:Agent 犯错 → 你纠正 → 写入 QWEN.md → Agent 不再犯同类错误。
💡 预测练习:假设你没有在 QWEN.md 中写明"API Key 通过
config/load_key.py加载",Agent 在新会话中需要调用大模型时,它最可能生成什么样的代码?想一想再往下看:Agent 大概率会直接写
os.getenv("OPENAI_API_KEY")或硬编码一个占位字符串——因为这是它在训练数据中见得最多的模式。它不知道你的项目有一个专用的 Key 加载模块,除非你告诉它。
# 5 扩展能力:自定义命令、MCP 与 Skill
到目前为止,你使用的都是 Qwen Code 的内置功能:读文件、写代码、执行命令。但实际开发中,团队往往有自己的特定流程——代码审查要检查哪些要点、提交前要运行哪些检查、遇到特定问题要查阅哪些文档。这些需求超出了内置命令的覆盖范围。
Qwen Code 提供了三种扩展机制来应对不同的需求。我们逐一实操,然后在 5.4 节建立一个清晰的选择框架。
# 5.1 自定义命令:固定流程一键触发
先看最简单的场景:你希望 Agent 在提交代码前执行一次代码审查,检查 PEP 8 规范、docstring 完整性和常见错误模式。每次手动输入一长段提示词太繁琐——你需要把这个固定流程封装成一个可复用的命令。
在项目根目录下创建 .qwen/commands/review.md:
---
description: 审查代码变更,检查规范和常见问题
---
请审查以下文件的代码变更:$ARGUMENTS
检查要点:
1. 是否符合 PEP 8 规范
2. 所有函数是否有 docstring(包含参数和返回值说明)
3. 是否有硬编码的 API Key 或密钥
4. DashScope API 调用是否使用了正确的 base_url
5. LlamaIndex import 路径是否使用 llama_index.core
输出格式:
- 按文件分组列出问题
- 每个问题标注严重程度(Error / Warning / Info)
- 最后给出总体评价和修改建议
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
使用时,在 Qwen Code 中输入:
/review chatbot/rag.py
Agent 收到的指令是模板中的完整内容,其中 $ARGUMENTS 被替换为 chatbot/rag.py。它会读取文件,按照检查要点逐一审查,输出结构化的审查报告。
自定义命令的本质是提示词模板——把反复使用的复杂提示词固化下来,通过 /命令名 一键触发。它的特点是手动触发、固定流程。
💡 小贴士:自定义命令还支持目录嵌套。如果你在
.qwen/commands/check/下创建style.md和security.md,就能用/check style和/check security分别触发。
# 5.2 MCP 实操:连接百炼联网搜索
自定义命令解决了"固定流程"的问题,但有些能力不是提示词能实现的。比如,你希望 Agent 在编写代码时能实时查阅 LlamaIndex 的最新文档。这需要让 Agent 调用外部服务——也就是 3.1 节学过的 MCP(Model Context Protocol)。
你在 3.1 中理解了 MCP 的设计思想:将工具提供方和 Agent 解耦,Agent 通过标准协议发现并调用工具。现在来实际配置。
在终端中运行:
qwen mcp add web-search -- npx -y @anthropic/mcp-server-web-search
这条命令告诉 Qwen Code:有一个名为 web-search 的 MCP 服务可用。Agent 启动后会通过 MCP 协议发现该服务提供的工具。
添加完成后,你可以直接对 Agent 说:
请搜索 LlamaIndex 0.12 版本中 VectorStoreIndex 的最新用法,
然后检查 chatbot/rag.py 中的实现是否需要更新。
2
观察 Agent 的行为——它会进入 3.1 节学过的 ReAct 循环:思考(需要了解最新 API)→ 行动(调用联网搜索)→ 观察(搜索返回文档)→ 思考(对比现有代码)→ 结论(给出是否需要修改的判断)。
整个过程中,MCP 工具的调用对你是透明的——Agent 自主判断何时需要联网搜索,你不需要手动触发。这是 MCP 和自定义命令最本质的区别:MCP 提供的是 Agent 可以自主调用的工具,而自定义命令是你手动触发的固定流程。
自定义命令和 MCP 分别解决了"固定流程"和"连接外部服务"的问题。但还有一种更深层的扩展需求没有覆盖:如何让 Agent 按需加载特定领域的专家知识——比如代码审查时自动遵循团队规范,课程审查时自动检查教学设计标准。这就是 Skill 的用武之地,下一节将深入讲解。
# 6 Skill——固化专家经验为可复用流程
# 6.1 从临时指令到 Skill:为什么需要一套演进路径
MCP 给 Agent 增加了"能做的事",但有时候 Agent 需要的不是新工具,而是特定领域的专家知识。比如,你在做答疑机器人的代码审查时,希望 Agent 自动检查以下几点:是否使用了 config/load_key.py 加载 API Key、LlamaIndex 的 import 路径是否正确、所有函数是否有 docstring。
你可以每次把这些规则打在对话框里。但第三次你就会觉得烦——规则越来越长,复制粘贴容易遗漏,而且不同的任务需要不同的规则集。
你在 3.5 学过 Skill 的理论——把专家知识封装为可触发的独立单元。现在来看它在 Qwen Code 中是怎么落地的。
这个演进过程分四步,每一步解决前一步的一个具体痛点:
| 阶段 | 形态 | 解决的痛点 | 新的问题 |
|---|---|---|---|
| 临时指令 | 在对话中直接输入规则 | 无 | 规则越来越长,反复粘贴 |
| 独立文件 | 把规则存成 .md 文件,对话中 @rules.md 引用 | 不用反复粘贴 | 每次手动引用,容易忘记 |
| 自定义命令 | 放入 .qwen/commands/ 目录 | /review 一键触发 | 必须手动触发,Agent 不会自主使用 |
| Skill | 放入 .qwen/skills/ 目录 | Agent 根据任务自动判断是否加载 | — |
最后一步才是 Skill 的真正价值:你不需要告诉 Agent "现在用审查规范"——它根据你的任务描述自动判断需要什么知识,并按需加载。 这就是 3.5 节讲的"渐进式披露"(Progressive Disclosure)在实际工具中的实现。
# 6.2 Skill 的结构与触发设计
一个 Skill 是一个目录,目录名即 Skill 名,其中必须包含一个 SKILL.md 文件。文件由两部分组成:
YAML frontmatter(元数据):
---
name: course-review
description: 审查 ACP 课程内容是否符合编写规范。当用户要求审查课程文稿、检查教学内容质量时使用。
---
2
3
4
Body(指令正文):
# 课程内容审查规范
## 语言风格
- 必须使用第二人称"你"
- 不使用网络用语或卖萌措辞
...
2
3
4
5
6
触发机制的底层逻辑: Qwen Code 启动时,只读取所有 Skill 的 name 和 description 字段(不读 Body),把这些摘要注入 Agent 的系统提示词。当你输入一个任务——比如"帮我审查课时 3.5 的课程内容"——Agent 发现 description 中的"审查课程内容"与当前任务匹配,就会读取完整的 Body 加入上下文。
这个设计有三个你在实际使用中需要理解的含义:
description的质量决定触发准确率。 写得太模糊(如"通用审查"),Agent 可能在不需要时也加载;写得太窄(如"审查课时 3.5"),Agent 可能在审查课时 3.6 时不触发。好的 description 应该描述任务类型而非具体实例。Body 不会常驻上下文。 和 QWEN.md 不同,Skill 的 Body 只在被触发时才加载。这意味着你可以创建很多 Skill 而不担心挤占上下文——只有当前任务真正需要的 Skill 才会被加载。
复杂 Skill 应使用渐进式披露。 如果审查规范有 10 个类别、200 条规则,不要全部写在 SKILL.md 里。主文件只写框架和目录,详细规则放在同目录下的子文件中。Agent 执行到对应步骤时再读取子文件——这样每次只加载需要的部分,避免上下文浪费。
# 6.3 五步编写法:从失败中提炼 Skill
写 Skill 最常见的误区是"凭空设计"——坐下来想"Agent 应该遵循哪些规则",然后一条一条列出来。这种方式写出的 Skill 往往要么过于笼统("写好代码"),要么遗漏关键场景(因为你没有预见到 Agent 会在哪里犯错)。
3.5 节教过一个更可靠的方法:从失败中提炼。在 Qwen Code 中,这个过程可以用五步完成:
第一步:让 Agent 完成一次真实任务,不给任何 Skill。 比如让它审查 chatbot/rag.py 的代码质量。记录它的输出:它检查了什么、遗漏了什么、给了哪些不准确的建议。
第二步:从失败中提取模式。 假设你发现三个问题:(1) 它没有检查 LlamaIndex 的 import 路径;(2) 它建议了一个已废弃的 API 用法;(3) 它忽略了 load_key() 的调用规范。这三个问题就是你的 Skill 需要覆盖的核心场景。
第三步:写 Skill 初稿。 针对第二步发现的问题写规则。不要追求完美——先覆盖最关键的 3-5 条规则。
第四步:用新会话验证。 启动一个全新的 Qwen Code 会话(/clear 或新终端),让 Agent 加载你的 Skill 后重新执行同一个任务。对比有 Skill 和没 Skill 时的输出差异。第一步中发现的三个问题解决了吗?有没有引入新的问题?
第五步:迭代。 根据第四步的结果修改 Skill,然后重复第四步验证,直到 Agent 能稳定通过你关心的所有检查点。
这个过程的关键洞察是:先有基线(Agent 裸跑的失败案例),再有 Skill。 不要跳过第一步。没有基线,你无法判断 Skill 是否真正改善了 Agent 的行为——你只是在"感觉"它变好了。
# 6.4 评测驱动 Skill 优化
五步法帮你写出了一个能用的 Skill。但"能用"和"好用"之间还有差距——Skill 可能在你测试过的场景下表现良好,但在新场景下失效。
3.5 节介绍过评测驱动的 Skill 自优化。在 Qwen Code 中,这个过程可以这样实现:
构建评测集。 为你的 Skill 准备 10-20 个测试用例,包含三类:
- 正向触发(8-12 条):Agent 应该加载 Skill 并正确执行的场景
- 边界案例(3-5 条):容易出错的边缘情况
- 负向控制(2-3 条):Agent 不应该触发 Skill 的场景(如"帮我写一个新函数"不需要课程审查 Skill)
自动化运行。 在 Qwen Code 的 headless 模式下批量执行评测:
qwen -p "请审查以下代码片段的质量:[测试用例 1]" --output-format stream-json
每个用例的输出可以自动收集并与预期结果比对。
分析失败案例。 找到 Skill 没能正确处理的用例,分析根因:是 description 没有触发?还是规则本身有遗漏?还是规则写得太模糊导致 Agent 误解?
迭代修改。 根据分析结果修改 SKILL.md,然后重新运行评测集,确认修改解决了问题且没有破坏已有用例——这和 3.5 节讲的"全量回归防止跷跷板效应"是同一个原则。
💡 小贴士:3.5 节提到的 skill-creator 元 Skill 可以加速这个过程——把失败案例和执行轨迹交给它,让它分析根因并提出 SKILL.md 的修改建议。但 skill-creator 加速迭代不能替代你对 Skill 结构和触发设计的理解。不懂原理就用 skill-creator,改了也可能白改。
# 6.5 Qwen Code 的 Skill 生态
你为答疑机器人项目创建的 Skill,和你每天使用的 QWEN.md、自定义命令,本质上是同一套理念的不同层次:
| 机制 | 本质 | 作用范围 |
|---|---|---|
| QWEN.md | 始终生效的项目知识 | 每次会话自动加载 |
| 自定义命令 | 手动触发的固定流程 | /命令名 时加载 |
| Skill | Agent 自主判断的专家知识包 | 匹配任务时按需加载 |
Qwen Code 的 Skill 存储在两个位置:项目级(.qwen/skills/)和用户级(~/.qwen/skills/)。你可以用 /skills 命令查看当前可用的所有 Skill。
Skill 的价值随复用范围的扩大而增长。你为课程审查写的 Skill,团队里每个人都可以用——只要把 .qwen/skills/ 目录纳入 Git 版本控制。当你的 Skill 被 10 个人使用时,你封装一次的投入获得了 10 倍的回报。这就是 3.5 节讲的"一次封装,多次复用"在 Qwen Code 中的实际体现。
# 7 Harness Engineering——从工具使用到系统驾驭
# 7.1 什么是 Harness Engineering
到目前为止,你学到的所有内容——EPCC 工作流、审批模式、上下文管理、QWEN.md、自定义命令、MCP、Skill——看起来是一系列独立的技巧。但如果你退一步看,它们共同构成了一个完整的体系:围绕大模型这个不可预测的"引擎",构建一整套让它可控、可靠、可持续改进的控制机制。
这个体系有一个名字:Harness Engineering(驾驭工程)。
你在 3.7 节会系统学习 HE 的理论框架。这一节聚焦一个实践问题:在 Qwen Code 的日常使用中,HE 的原则具体体现在哪里?
大模型是引擎——它能理解代码、生成方案、执行操作。但引擎本身是不可预测的:同一个提示词可能产生不同的结果,Agent 可能在第三次执行时犯了第一次没犯的错误。Harness 不是限制引擎,而是让引擎的能量可控地输出。 就像赛车的驾驭系统不会让发动机变慢,而是让车手能精确控制每一匹马力的去向。
# 7.2 仓库知识即系统记录
Harness Engineering 的第一条核心原则是:仓库知识应该成为 Agent 的唯一事实来源(System of Record)。
Agent 只能看到它能访问的内容。团队在即时通讯里讨论的架构决策、会议纪要中记录的产品方向、存在你脑子里的编码偏好——如果没有写进仓库,对 Agent 来说就不存在。就像一个新入职的同事,如果公司的规范只存在于老员工的脑子里,他根本无从遵守。
你可能的第一反应是"那就写一个超级详细的 QWEN.md 把所有东西都塞进去"。但这条路走不通,原因有四个:
- 上下文是稀缺资源。 一个巨大的指令文件会挤占任务本身和代码的上下文空间,Agent 要么遗漏关键约束,要么开始优化错误的方向。
- 什么都"重要"等于什么都不重要。 当规则太多时,Agent 会局部模式匹配,而不是有目的地导航。
- 大文件立刻腐烂。 一个 monolithic 的手册很快变成陈旧规则的坟场,Agent 分不清哪些还有效,人也懒得维护。
- 难以机械验证。 一个大文件无法做覆盖度检查、时效性验证或交叉引用校验。
正确的做法你在前面几节已经学过了——QWEN.md 是目录,不是百科全书。 QWEN.md 保持在 100-200 行,只提供项目概况和"去哪里找更详细信息"的指引。详细的设计文档、编码规范、架构决策放在独立文件中——Skill 放在 .qwen/skills/,参考文档放在 docs/,Agent 执行到具体任务时按需读取。
你在第 4 节学到的 QWEN.md 写法——"该写什么 vs 不该写什么"——就是这个原则的直接应用。而 Skill 的渐进式披露设计(SKILL.md 只写框架,详细规则放子文件)是同一个原则在另一个层面的体现。
行业中大量使用 Coding Agent 的团队都独立验证了同一个结论:把 QWEN.md(或等效的配置文件)当作"目录"而不是"百科全书",是 Agent 辅助开发能否规模化的关键分水岭。
# 7.3 机械化执行与人类品味
Harness Engineering 的第二条核心原则是:通过机械化手段执行架构约束,而不是依赖 Agent 的自觉。
"告诉 Agent 遵守规范"和"让 Agent 不得不遵守规范"是完全不同的两件事。前者是提示词——Agent 可能遵守,也可能忘记;后者是机制——违反时会被拦截或自动修正。
在实际项目中,这意味着把关键规则编码成可执行的检查:自定义命令中的审查清单、CI 流水线中的 linter、Hooks 中的格式校验。当 Agent 违反规则时,检查工具的错误消息本身就是修复指引——Agent 读到错误后能自动修正,不需要人类介入。
下面这张表把 HE 的核心原则和你在 Qwen Code 中学到的具体机制做了对应:
| HE 原则 | 在 Qwen Code 中的实现 |
|---|---|
| 仓库知识即事实来源 | QWEN.md + Skill 文件(版本控制,随代码同步) |
| 目录式导航,不是百科全书 | QWEN.md 保持精简,详细信息放 Skill 和 docs/ |
| 机械化执行约束 | 自定义命令(/review)+ Hooks(自动格式检查) |
| Agent 可观测性 | /context 查看上下文 + /export 导出会话日志 |
| 持续清理技术债 | 面向失败更新 QWEN.md(记忆演进闭环) |
| 人类品味持续反馈 | 审批模式(default)+ Plan Mode 审查方案 |
最后一行尤其重要。在 Coding Agent 时代,人类的工作不再是写代码,而是设计环境、表达意图、构建反馈循环。在 Qwen Code 的日常使用中,这三件事分别对应:
- 设计环境 = 维护 QWEN.md、创建 Skill、配置 MCP
- 表达意图 = 在 EPCC 工作流中清晰描述需求
- 构建反馈循环 = 用评测驱动 Skill 优化、面向失败写记忆
# 7.4 从"会用工具"到"驾驭系统"
把前面学到的所有内容整合起来,你可以看到一个清晰的分层:
| 层次 | 你学到的能力 | HE 的定位 |
|---|---|---|
| 工具层 | EPCC 工作流、审批模式 | Agent 能做什么、做多少 |
| 上下文层 | /context、/compress、/clear | Agent 的注意力管理 |
| 记忆层 | QWEN.md 三级配置 | Agent 的持久知识 |
| 能力层 | 自定义命令、MCP、Skill | Agent 的可扩展能力 |
| 验证层 | 评测驱动 Skill 优化、代码审查 | Agent 的质量保障 |
| 演进层 | 面向失败写记忆、Skill 迭代 | Agent 的自我改进 |
这六层叠加在一起,就是围绕大模型引擎构建的完整 Harness。你不需要一次性搭完所有层次——从 QWEN.md 开始,逐步添加自定义命令,遇到重复工作时创建 Skill,在关键环节加入评测。
重要的不是每一层都做到完美,而是形成"发现问题 → 固化解法 → 验证效果"的持续循环。 每一次 Agent 犯错都是改进 Harness 的机会。当这个循环运转起来,你的 Coding Agent 环境会随着使用时间的增长而持续变好——这就是 Harness Engineering 的核心承诺。
💡 预测练习:假设你的团队有 5 个人都在用 Qwen Code 开发答疑机器人项目。每个人都有自己的
.qwen/skills/和.qwen/commands/。当一个人写了一个好用的代码审查 Skill,其他人怎么用上它?想一想再往下看:把
.qwen/skills/和.qwen/commands/纳入 Git 版本控制。一个人创建的 Skill,其他人git pull后就能自动使用。这就是 3.5 节讲的"从个人记忆到团队知识"在工程上的落地方式——也是 Harness Engineering "仓库知识即系统记录"原则的直接体现。
# 8 综合实践:用 Qwen Code 构建 Gradio Web UI
前面五节中,你分别学习了工作流、上下文管理、项目配置和扩展机制。现在把它们整合起来,完成一个完整的开发任务:为答疑机器人添加 Gradio Web 界面。
# 8.1 项目需求与任务拆解
需求很明确:把目前只能在 Notebook 中调用的 chatbot/rag.py 封装成一个 Web 应用,用户在浏览器中输入问题,看到答案和检索到的原始文档来源。
- 用户输入问题,点击"提问"按钮
- 页面展示答疑机器人的回答
- 回答下方展示检索到的文档来源(文件名和相关段落)
- 使用
chatbot/rag.py中的现有函数 - 代码放在项目根目录的
app.py中
在 Qwen Code 中切换到 Plan Mode(/approval-mode plan),输入需求让 Agent 生成方案。
# 8.2 Explore + Plan:分析现有代码并设计方案
Agent 在 Plan Mode 下会先阅读 chatbot/rag.py 的代码,理解 load_index()、create_query_engine()、ask() 等函数的接口,然后生成分步计划。
💡 预测练习:
ask()函数目前调用streaming_response.print_response_stream()直接打印到终端。如果 Agent 在app.py中直接调用ask(question, query_engine),Gradio 界面上会显示什么?答案是:界面上什么也不显示。
print_response_stream()把内容输出到了标准输出(终端),不是返回给调用方。Agent 必须绕过ask(),直接使用query_engine.query()获取返回值。如果你在审查 Agent 的计划时发现它打算调用ask()获取回答字符串,应该立即指出这个问题。
审查计划时的核心问题是:Agent 是否正确理解了现有函数的行为?确认方案合理后,切换回 default 模式开始执行。
# 8.3 Code:分步实现
实现过程中,运用前面学到的所有关键实践:
检查 diff。 特别关注 Agent 是否改动了 chatbot/rag.py 中的现有函数——如果任务只要求新建 app.py,Agent 不应该修改现有模块的公共接口。如果它试图修改 ask() 的签名,你需要判断:这个修改是否会影响其他依赖 ask() 的代码(如 Notebook 中的调用)?
监控上下文。 定期运行 /context 查看上下文使用量。当 Agent 反复读取文件、生成代码、修复错误时,上下文会快速膨胀。使用量超过 60% 时,在一个子任务完成后运行 /compress 压缩历史对话。
更新 QWEN.md。 如果 Agent 犯了重复错误(比如使用了 Gradio 的旧版 API),修正后写入 QWEN.md。
利用 MCP。 如果 Agent 在使用 Gradio API 时不确定某个组件的参数,它可以通过你在 5.2 节配置的联网搜索 MCP 查阅最新文档。
Agent 生成的 app.py 核心逻辑大致如下:
import gradio as gr
from config.load_key import load_key
from chatbot.rag import load_index, create_query_engine
load_key()
# 启动时加载索引和查询引擎
index = load_index()
query_engine = create_query_engine(index)
def answer_question(question):
"""处理用户提问,返回回答和来源信息。"""
response = query_engine.query(question)
# 提取回答文本
answer = response.response
# 提取来源信息
sources = []
for node in response.source_nodes:
source_info = {
"文件": node.metadata.get("file_name", "未知"),
"内容": node.get_content()[:200]
}
sources.append(source_info)
source_text = "\n\n".join(
[f"📄 {s['文件']}\n{s['内容']}" for s in sources]
)
return answer, source_text
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
注意两个关键设计决策:第一,代码使用了 config/load_key.py 加载 API Key(因为 QWEN.md 中有明确约束);第二,Agent 没有调用 ask() 函数,而是直接使用 query_engine.query() ——因为它需要拿到完整的 Response 对象来提取 source_nodes。
# 8.4 验证与交付
代码实现后,在终端中启动应用进行测试:
python app.py
测试以下场景:
- 正常提问:输入一个知识库中有答案的问题(如"公司的写作规范有哪些要求?"),确认回答正确、来源展示完整
- 知识库外的问题:输入一个知识库中没有的问题,确认机器人不编造答案
- 空输入:不输入任何内容直接点击"提问",确认不会报错
- 长文本:输入一个较长的问题,确认界面布局不变形
测试通过后,使用你创建的自定义命令做一次代码审查:
/review app.py
确认无严重问题后,让 Agent 生成提交:
请为这次改动生成 git commit 并提交。
在确认提交之前,检查 staged 文件列表——确保 Key.json 没有被包含。
至此,你用 Qwen Code 完成了一个从需求分析到代码交付的完整开发流程。
# 9 复盘:Coding Agent 的能力边界与反模式
# 9.1 Agent 擅长的事与容易出错的地方
Agent 擅长的事:
- 代码脚手架:根据需求描述生成模块的基本结构,如
app.py的 Gradio 界面框架 - 读代码和解释代码:快速分析
chatbot/rag.py中函数之间的调用关系 - 重复性修改:比如为所有函数统一添加 docstring、批量修改 import 路径
- 生成测试用例:根据函数签名和 docstring 自动生成测试代码
- 搜索和整合信息:通过 MCP 连接联网搜索,查阅框架文档并总结要点
Agent 容易出错的地方:
- 过时的 API 用法:Agent 的训练数据有截止日期,可能生成已废弃的函数调用
- 项目特有的约束:除非写在 QWEN.md 里,Agent 不知道项目的特殊规则
- 跨文件的副作用:修改一个函数的返回值类型时,Agent 可能忘记检查其他调用方
- 边界条件处理:生成的代码通常覆盖正常路径,但容易遗漏空输入、异常响应等
- 安全敏感操作:Agent 可能在代码中硬编码 API Key,或在
.gitignore之外创建包含敏感信息的文件
这两个列表不是用来评价 Agent 好不好,而是帮你建立一个清晰的预期:在 Agent 擅长的领域放手让它做,在它容易出错的地方重点审查。
# 9.2 五个反模式
以下是使用 Coding Agent 时最常见的五种低效做法:
| 反模式 | 表现 | 正确做法 |
|---|---|---|
| 一次性说太多 | 把多个不相关的需求塞进一条指令 | 一次一个任务,按 EPCC 四阶段逐步推进 |
| 不看 diff | Agent 修改文件后直接继续,不检查改了什么 | 每次文件变更后审查 diff,关注是否改动了不该改的文件 |
| 不管上下文膨胀 | 长时间会话不使用 /compress 或 /clear | 定期 /context 监控,子任务完成后 /compress,新任务前 /clear |
| 把 Agent 当搜索引擎 | 反复问概念性问题而不是让它做开发任务 | 概念查询用文档或搜索引擎,Agent 的价值在于读写代码和执行操作 |
| 不验证就提交 | Agent 生成代码后直接 commit,没有运行测试或手动验证 | 先运行、先测试、先审查,确认无误再提交 |
这五个反模式的共同根源是对 Agent 过度信任或过度依赖。Agent 是高效的协作伙伴,但它不替你做判断——判断"这段代码该不该这么改""这个结果对不对"仍然是你的责任。
# ✅ 本节小结
本节你从使用者的视角系统地实践了 Coding Agent 的核心能力:
- EPCC 工作流(Explore → Plan → Code → Commit)让你有章法地推进开发任务,每个阶段有明确的目标和操作
- 审批模式让你根据任务需要控制 Agent 的自主权,Plan Mode 用于方案审查,default 模式适合日常开发
- 上下文管理(
/context、/compress、/clear)让 Agent 在长时间工作中保持高效 - QWEN.md 将项目知识持久化为 Agent 的跨会话记忆,通过面向失败的更新策略不断演进
- Skill 把专家经验封装为可复用流程,通过五步编写法从失败中提炼,用评测驱动持续优化
- Harness Engineering 把所有机制整合成一个分层体系——围绕大模型引擎构建可控、可靠、可持续改进的驾驭系统
- 五个反模式帮你识别低效的使用方式,建立与 Agent 协作的正确心智
这些实践覆盖了"怎么用好 Coding Agent"和"怎么持续改进 Agent 环境"两个核心问题。但还有一个更根本的问题没有回答:你怎么知道 Agent 做得好不好? "看起来能用"不等于"做得好"。答疑机器人回答了问题,但回答的准确率是多少?检索到的文档来源是否真的相关?当你修改了检索策略,整体质量是变好了还是变差了?下一节(评测驱动 Agent 开发),你将学习如何把"做得好"这个主观判断变成可量化、可自动化的工程实践。
# 🔥 课后小测验
# 🔍 单选题 3.8.1
关于 EPCC 工作流,以下哪种做法最合理❓ - A. 每次都严格按照 E → P → C → C 四个阶段执行,不跳过任何阶段
- B. 对于简单的单文件修改,可以跳过 Explore 和 Plan,直接进入 Code 阶段
- C. Plan 阶段让 Agent 生成计划后直接执行,不需要人工审查
- D. Commit 阶段直接让 Agent 提交,不需要检查 staged 文件列表
【点击查看答案】
✅ 参考答案:B
📝 解析:
EPCC 是灵活的工作框架,不是僵化的流程。对于简单任务直接告诉 Agent 做什么即可。但对于涉及多文件、多步骤的复杂任务,Explore 和 Plan 阶段能显著减少返工。C 选项错误:Plan 的计划必须人工审查。D 选项错误:提交前必须检查 staged 文件列表。
# 🔍 单选题 3.8.2
Agent 每次新会话都把 DashScope 的 API 地址写成 OpenAI 默认地址,你已经纠正了三次。最合理的解决方式是❓ - A. 每次会话开始时手动提醒 Agent
- B. 将正确的 API 地址和错误示例写入 QWEN.md 的"常见陷阱"部分
- C. 创建一个自定义命令
/fix-url,每次发现错误时手动触发 - D. 创建一个 Skill,让 Agent 在写代码时自动检查 API 地址
【点击查看答案】
/fix-url,每次发现错误时手动触发✅ 参考答案:B
📝 解析:
这是一个跨会话始终成立的项目约束,且是 Agent 反复犯的具体错误——完全符合 QWEN.md"面向失败写记忆"的原则。写入后 Agent 每次启动都会加载。C 选项是事后补救而非预防。D 选项过于重量级。
# 🔍 单选题 3.8.3
开发 Gradio UI 时,/context 显示上下文使用量达 75%。此时最合理的操作是❓ - A. 立即运行
/clear 清空所有上下文 - B. 运行
/compress 压缩历史对话,然后继续当前任务 - C. 忽略使用量,继续开发直到 Agent 出现明显遗忘
- D. 关闭终端重新启动 Qwen Code
【点击查看答案】
/clear 清空所有上下文/compress 压缩历史对话,然后继续当前任务✅ 参考答案:B
📝 解析:
当上下文使用量较高但任务尚未完成时,/compress 保留关键信息,压缩冗余的历史对话,释放空间继续工作。A 选项过于激进——丢失所有会话上下文,你需要重新向 Agent 解释当前任务。C 选项有风险——上下文溢出后 Agent 可能丢失重要约束的记忆。
# 🔍 单选题 3.8.4
以下四种需求分别应该使用哪种扩展机制?
① 每次提交前检查是否有硬编码的 API Key
② 编写代码时实时查阅 LlamaIndex 最新文档
③ 项目必须使用 PEP 8 规范
④ 审查课程内容时自动检查教学编写规范❓ - A. ① Skill ② MCP ③ QWEN.md ④ 自定义命令
- B. ① 自定义命令 ② MCP ③ QWEN.md ④ Skill
- C. ① 自定义命令 ② Skill ③ QWEN.md ④ MCP
- D. ① QWEN.md ② MCP ③ Skill ④ 自定义命令
【点击查看答案】
✅ 参考答案:B
📝 解析:
按 5.4 节决策树分析——① 是固定检查流程,手动触发 → 自定义命令。② 需要调用外部服务,Agent 自主判断何时查阅 → MCP。③ 是跨会话始终成立的项目约束 → QWEN.md。④ 是领域专家知识,Agent 识别到相关任务时自动加载 → Skill。
# 🔍 单选题 3.8.5
以下哪种做法属于"不验证就提交"的反模式❓ - A. Agent 修改了 rag.py 后,你运行了已有的测试用例,确认通过后提交
- B. Agent 生成了 app.py 后,你启动 Gradio 应用并手动测试了三个场景后提交
- C. Agent 修改了 evaluate.py 后,你检查了 diff 确认改动合理,直接提交
- D. Agent 新建了 .gitignore 文件后,你检查了文件内容确认包含 Key.json 后提交
【点击查看答案】
✅ 参考答案:C
📝 解析:
C 选项只检查了 diff"看起来合理",但没有实际运行代码验证修改是否正确。evaluate.py 涉及 RAGAS 评测逻辑,diff 审查无法发现运行时才暴露的问题(如参数类型不匹配)。"不验证就提交"的核心问题不是"没看 diff",而是"没有运行或测试就认为代码正确"。
# 🔍 单选题 3.8.6
关于 QWEN.md 的三级配置层次,以下说法正确的是❓ - A. 目录级 QWEN.md 的内容会完全覆盖项目级 QWEN.md 的内容
- B. 全局 QWEN.md 适合放置特定项目的技术栈和模块结构信息
- C. 三级配置按"全局 → 项目 → 目录"顺序加载,更具体的层级优先级更高
- D. 如果项目级和目录级 QWEN.md 有冲突,Agent 会提示用户选择
【点击查看答案】
✅ 参考答案:C
📝 解析:
三级配置的设计原则是"从通用到具体",更具体的配置优先级更高。A 错:目录级是在项目级基础上追加和覆盖,不是完全替换。B 错:全局配置放跨项目通用的内容(如个人编码偏好)。D 错:配置冲突按优先级自动解决,不需要用户手动选择。
# 🔍 单选题 3.8.7
关于 Skill 的五步编写法,以下哪个步骤最关键❓ - A. 第三步:写 Skill 初稿——规则写得越完整越好
- B. 第一步:让 Agent 裸跑一次,记录失败案例作为基线
- C. 第五步:反复迭代直到 Skill 完美覆盖所有场景
- D. 第四步:用新会话验证——确保 Agent 加载了 Skill
【点击查看答案】
✅ 参考答案:B
📝 解析:
第一步(建立基线)是整个方法的基础。没有基线,你无法判断 Skill 是否真正改善了 Agent 的行为——你只是在"感觉"它变好了。跳过第一步直接写 Skill,往往会得到"看起来合理但实际不解决问题"的规则。A 选项的问题是追求完整性而非针对性——Skill 应该首先覆盖最关键的失败场景,而不是试图写一本百科全书。
# 🔍 单选题 3.8.8
根据 Harness Engineering 的原则,QWEN.md 应该扮演什么角色❓ - A. 项目的完整技术文档,越详细越好
- B. 项目知识的目录和导航——保持精简,指向更详细的信息源
- C. Agent 的唯一知识来源——所有规则都必须写在 QWEN.md 里
- D. 一次性写好的配置文件,后续不需要更新
【点击查看答案】
✅ 参考答案:B
📝 解析:
Harness Engineering 的核心原则之一是"QWEN.md 是目录,不是百科全书"。QWEN.md 保持在 100-200 行,只提供项目背景和"去哪里找更详细信息"的指引。详细的设计文档、编码规范、架构决策放在独立文件中(Skill、docs/),Agent 按需读取。A 选项会导致上下文被挤占。C 选项忽略了 Skill 和独立文档的作用。D 选项违背了"面向失败持续演进"的原则。
# ✉️ 评价反馈
感谢你学习阿里云大模型 ACP 认证课程,如果你觉得课程有哪里写得好、哪里写得不好,期待你通过问卷提交评价和反馈 (opens new window)。
你的批评和鼓励都是我们前进的动力。